May 14, 2026
Claude vs. DeepL for oversættelse: Hvilken er egentlig bedst?
Her er det ærlige udgangspunkt: Claude og DeepL konkurrerer ikke rigtigt om den samme bruger.
DeepL blev bygget til oversættelse. Det har forfinet én ting (at konvertere tekst fra ét sprog til et andet med naturlig flydende tale) siden 2017. Claude er en generel ræsonnementsmodel udviklet af Anthropic, som tilfældigvis oversætter usædvanligt godt, især når indholdet er langt, komplekst eller kræver dyb kontekstuel fortolkning.
Spørgsmålet Claude vs DeepL er vigtigt for folk, der reelt beslutter, hvordan de skal håndtere professionelt oversættelsesarbejde, og ønsker et klart svar, ikke en markedsføringssammenligning. Det er det, denne artikel sigter efter at være.
I denne artikel
- Hvad hvert værktøj er bygget til at gøre
- Hvordan sammenlignes Claude og DeepL med hensyn til nøjagtighed?
- Hvor DeepL har en reel fordel
- Hvor Claude trækker sig foran
- Sprogdækning og dokumenthåndtering
- Pris: Hvad du faktisk betaler
- Hvilken skal du bruge?
- Hvad sker der, når du kører begge på én gang
- Ofte stillede spørgsmål
Hvad hvert værktøj blev bygget til at gøre
Claude: en ræsonnementsmodel, der bruges til oversættelse

Claude er udviklet af Anthropic og er i sin kerne en stor sprogmodel designet til ræsonnement, analyse og generering på tværs af en bred vifte af opgaver. Oversættelse er en af de opgaver, og det viser sig, at Claude er ret god til det - især for indhold, hvor den omgivende kontekst bestemmer betydningen: juridiske dokumenter, litterære tekster, tekniske specifikationer og alt, hvor en enkelt sætning ikke kan forstås isoleret.
Den nuværende Claude 4-familie (Claude Opus 4 og Claude Sonnet 4) har et kontekstvindue på 200.000 tokens, hvilket ændrer, hvad der er muligt i oversættelse. En dokumentoversætter, der arbejder segment for segment, går glip af afhængigheder mellem sætninger, uoverensstemmelser i karakternavne eller terminologi og tonale skift på tværs af kapitler. Claude har ikke det problem. Når du fodrer den med en hel kontrakt, ser den hele kontrakten.
Ifølge Intentos State of Translation Automation 2025{4} rangerer Claude Opus 4 og Claude Sonnet 3.7 blandt de bedst præsterende single-agent løsninger på tværs af engelsk til tysk, engelsk til hollandsk, engelsk til italiensk, engelsk til japansk og engelsk til koreansk sprogpar i både automatiseret og menneskelig LQA-evaluering.
DeepL: et værktøj bygget specifikt til oversættelse

DeepL gør én ting og har optimeret ubarmhjertigt for det. Dens neurale maskinoversættelsesmotor er trænet specifikt på oversættelsesrelevante data, og den specialisering ses i dens output: DeepL-oversættelser lyder konsekvent mere naturlige for europæiske sprogpar end de fleste konkurrenter. Sproget er idiomatisk, grammatikken er ren, og registeret passer som regel godt til kilden.
I MachineTranslation.coms interne benchmark på tværs af 5.000 ord med blandet teknisk og marketingindhold scorede DeepL 94,2 % nøjagtighed – den højeste af alle selvstændige motorer, der blev testet, og beskrevet i benchmarken som kongen af flow. For europæiske sprogpar lyder det især mest menneskeligt.
DeepL lancerede også DeepL next-gen i 2024, en specialbygget LLM til oversættelse, der forbedrer den klassiske model til længere tekster, og som Intentos 2025-evaluering placerer blandt de bedst præsterende realtidsløsninger på tværs af flere sprogpar, herunder engelsk til spansk, fransk, italiensk, hollandsk, koreansk og portugisisk.
Afvejningen for den specialisering: DeepL understøtter 33 sprog, hvilket er begrænset. Og det er et enkeltmodel-system – outputtet, du modtager, er DeepLs fortolkning, uden krydstjek-signal og uden mulighed for at vide, hvornår det har truffet et valg, du måske er uenig i.
Hvordan er Claude og DeepL sammenlignet med hensyn til nøjagtighed?
Svaret afhænger i høj grad af, hvad du oversætter, og til hvilket sprog.
Europæiske sprogpar
For centrale europæiske par (tysk, fransk, spansk, italiensk, hollandsk, portugisisk) er DeepL next-gen virkelig konkurrencedygtig. Intentos menneskelige LQA-evaluering for 2025 placerer det i topklassen for seks af de elleve sprogpar, der er evalueret. Uddata lyder naturlig, idiomatisk og passende formel uden at kræve nogen prompt engineering fra brugeren.
Claude Opus 4 og Sonnet 3.7 optræder også i topklassen for flere af disse par, især engelsk til tysk og engelsk til hollandsk, hvor Claudes kontekstuelle ræsonnement hjælper den med at håndtere morfologisk kompleksitet og kasusoverensstemmelse på tværs af længere tekster.
Den praktiske forskel på dette niveau: for kort, standardindhold (produktbeskrivelser, formularfelter, UI-tekst) betyder DeepLs hastighedsfordel noget, og dens kvalitet er konsekvent. For længere, mere komplekst indhold producerer Claudes kontekstvindue og ræsonnementdybde mærkbart stærkere output.
Lange dokumenter og konteksthåndtering
Det er her, sammenligningen bliver mindre tæt.
Som det fremgår af MachineTranslation.coms interne analyse{10}, er de fejl, der er tilbage i moderne AI-oversættelse, næsten udelukkende semantiske: forkert tone, forkert register, forkert udtryk, manglende afhængighed på tværs af sætninger. Dette er ikke fejl, som en segment-for-segment oversættelse opfanger. Det er fejl, der først dukker op, når du læser hele dokumentet og bemærker, at en karakters titel ændrede sig tre sider inde, eller at en defineret term blev gengivet forskelligt i to klausuler.
Claudes kontekstvindue på 200.000 tokens betyder, at den kan rumme en hel juridisk aftale, en teknisk manual eller et litterært kapitel i sin arbejdshukommelse og producere en oversættelse, der er internt konsistent i hele dokumentet. DeepLs dokumentoversættelsesfunktion behandler indhold sektion for sektion, hvilket generelt fungerer godt for strukturerede dokumenter, men kan introducere den slags afvigelse, som Claude undgår ved design.
Teknisk og domænespecifikt indhold
Begge værktøjer håndterer generelt teknisk indhold rimeligt godt. For højt specialiserede domæner (juridisk, medicinsk, finansiel), afhænger resultaterne af, hvor godt kildematerialet matcher hvert værktøjs træningsdata.
DeepL tillader glossarindsprøjtning på betalte API-planer, hvilket hjælper med at opretholde terminologisk konsistens. Claude, brugt via API eller i en velstruktureret prompt, kan absorbere en hel ordliste som kontekst og anvende den overalt. Ingen af tilgangene er definitivt bedre; begge kræver opsætningsarbejde fra brugeren.
Hvor DeepL har en reel fordel
Naturlighed og flydende sprog for europæiske sprogpar. Når en oversættelse skal lyde som om den er skrevet af en indfødt taler (markedsføringstekster, brandkommunikation, forbrugerrettet indhold), er DeepLs output konsekvent blandt de mest naturligt lydende, der findes. Claude oversætter præcist, men DeepLs output, især for EU-sprogpar, lyder mere idiomatisk.
Hastighed. DeepL er en NMT-motor optimeret til gennemløb. For workflows med højt volumen og tidskritiske krav er det betydeligt hurtigere end Claude, som opererer med LLM-hastigheder.
Workflow-integration. DeepL har et modent økosystem: CAT-værktøjsplugins, en veldokumenteret API, ordlisteadministration og toneindstillinger (formel/uformel). Det passer ind i professionelle oversætteres arbejdsgange på måder, som Claude, som en generel model, ikke gør indbygget.
Konsekvent output for standardindhold. For indhold, hvor oversættelsesopgaven er veldefineret, og outputtet bare skal være pålideligt korrekt, fjerner DeepL variabler. Du ved omtrent, hvad du kommer til at få.
Hvor Claude er foran
Lange, kontekstuelt komplekse dokumenter. En 40-siders kontrakt, et litterært kapitel, en teknisk specifikation i flere sektioner – Claude behandler det hele på én gang og opretholder konsistens på tværs af det på en måde, som segment-for-segment oversættelse ikke kan efterligne.
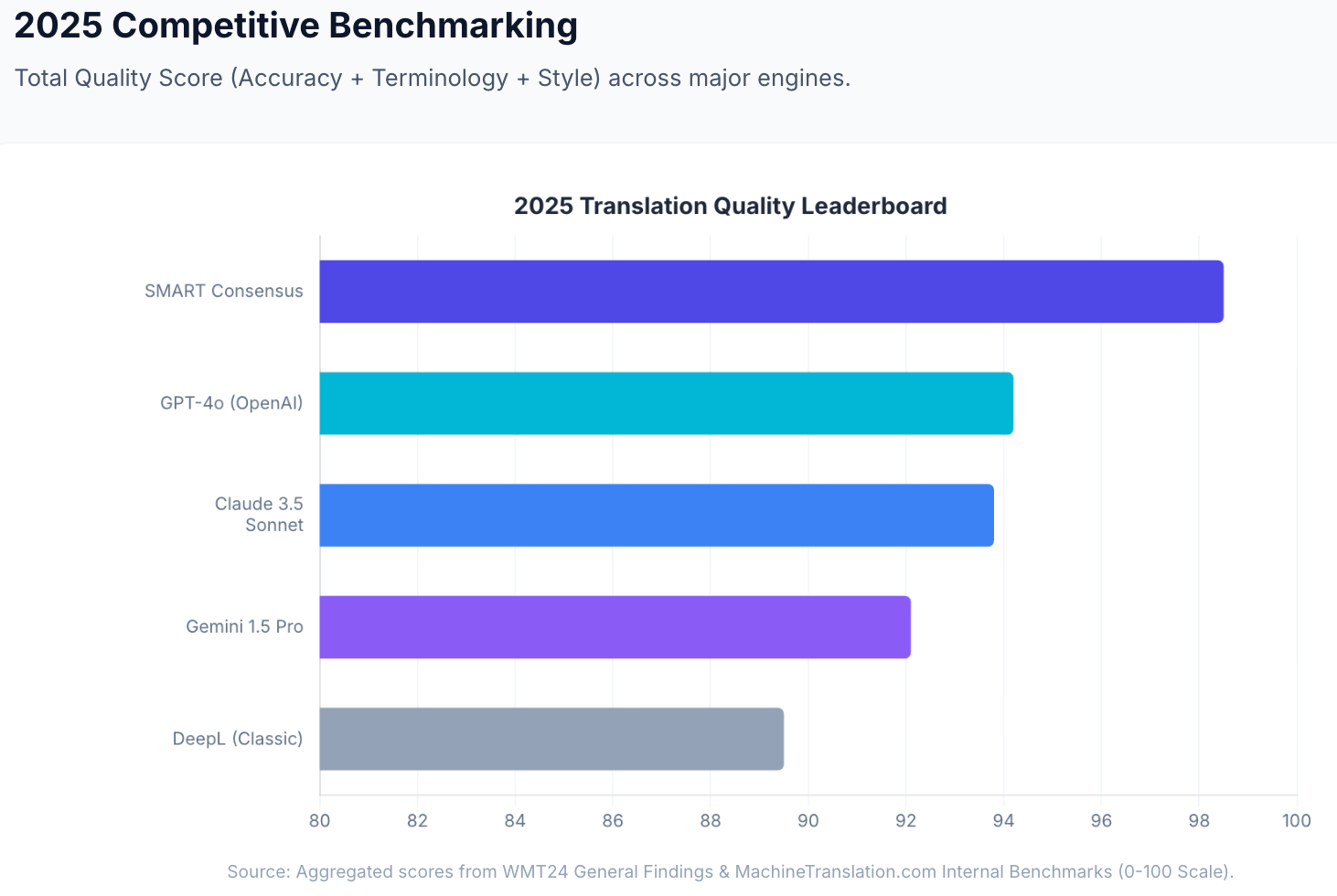
Nuance og register. Claude 3.5 Sonnet scorede 93,8 ud af 100 i MachineTranslation.coms interne kvalitetsbenchmark og klarede sig især godt på indhold, hvor tone er vigtig: oversættelser af brand voice, kommunikation med interessenter og professionel korrespondance, hvor teknisk korrekt ikke er nok.
 {4}
{4}Flersproget bredde. Claude understøtter en meget bredere vifte af sprog end DeepLs 33. For teams, der arbejder uden for DeepLs centrale europæiske dækningsområde, udfylder Claude et reelt hul.
Ræsonnement om teksten. Hvis du ikke bare oversætter, men også beder modellen om at tilpasse indholdet til et andet publikum, justere registeret eller markere kulturelt upassende udtryk, gør Claude dette som en del af den samme opgave. DeepL oversætter. Claude mener også.
Sprogdækning og dokumenthåndtering
| Claude (Opus 4 / Sonnet 4) | DeepL (Classic + næste generation) | |
|---|---|---|
| Sprog understøttet | Bredt flersproget (100+) | 33 sprog |
| Kontekstvindue | Op til 200.000 tokens | Segment for segment |
| Dokumentformater | Via API eller filupload | PDF, DOCX, PPTX, XLSX |
| Bevaring af layout | Begrænset | Stærk (original formatering bevaret) |
| Filstørrelse | Afhænger af antallet af tokens | Op til 30 MB på højere planer |
| Ordlisteunderstøttelse | Via prompt / API | Indbygget ordlistefunktion |
| Integration med CAT-værktøj | Nej | Ja (understøtter de vigtigste CAT-værktøjer) |
En praktisk bemærkning om dokumenter: DeepL bevarer den originale formatering ved oversættelse af DOCX- og PDF-filer, hvilket er virkelig nyttigt for forretningsdokumenter, hvor omformatering efter oversættelse er tidskrævende. Claudes dokumentoversættelse via API bevarer ikke layoutet på samme måde, hvilket er vigtigt for alt, der skal distribueres direkte uden efterbehandling.
Pris: Hvad du faktisk betaler
Claude (via Anthropic API):
- Claude Sonnet 4: $3.00 pr. million input tokens / $15.00 pr. million output tokens
- Claude Opus 4: $15.00 pr. million input tokens / $75.00 pr. million output tokens
- Via Claude.ai: Gratis niveau tilgængeligt med forbrugsgrænser; Pro-plan til $20/måned
DeepL:
- Gratis: begrænsede tegn, 3 ikke-redigerbare dokumentoversættelser pr. måned
- Starter: ~$10.49/bruger/måned
- Advanced: ~$34.49/bruger/måned
- Ultimate: ~$68.99/bruger/måned
- API Pro: $25 pr. million tegn
For de fleste individuelle professionelle brugere er DeepLs abonnementspriser mere forudsigelige. For API-tunge arbejdsgange afhænger sammenligningen af mængden: Claudes prissætning pr. token skalerer anderledes end DeepLs pr. tegn-model, og ved store mængder kan forskellen gå begge veje afhængigt af den gennemsnitlige dokumentlængde og oversættelsesretning.
Hvilken skal du bruge?
Valget afhænger af, hvad du oversætter, ikke hvilken værktøj der objektivt set er bedst.
| Anvendelsesområde | Bedste valg |
|---|---|
| Markedsføringstekst, forbrugerrettet EU-indhold | DeepL |
| Lange juridiske eller tekniske dokumenter, der kræver konsistens | Claude |
| UI-strenge, produktbeskrivelser i store mængder | DeepL |
| Litterær oversættelse eller oversættelse af brand-tone | Claude |
| Sprog uden for DeepLs 33 understøttede | Claude |
| Arbejdsgang med CAT-værktøjer eller TMS-integration | DeepL |
| Indhold, der kræver bevarelse af formatering | DeepL |
| Kompleks flersproget ræsonnering eller tilpasning | Claude |
| Hurtig standardoversættelse i store mængder | DeepL |
| Følsomt indhold, hvor kontekstuel nuance betyder mest | Claude |
Intet svar er permanent. Et team, der oversætter et produktkatalog til fransk, og et team, der oversætter en juridisk udtalelse til japansk, har brug for forskellige standardindstillinger.
Hvad sker der, når du kører begge dele på én gang?
Der er et argument for, at spørgsmålet om Claude vs. DeepL ikke er den mest nyttige ramme. Begge er stærke værktøjer med forskellige styrker. Det mere nyttige spørgsmål er: hvordan får man det bedste fra begge verdener?
Når du kører Claude og DeepL på den samme kildetekst og sammenligner resultaterne, fortæller forskellene dig noget om indholdet. Høj overensstemmelse mellem de to betyder, at oversættelsen er relativt entydig. Afvigelse afslører, hvor der findes reelle fortolkningsvalg – hvilket ord, hvilket register, hvilken idiomatisk gengivelse.
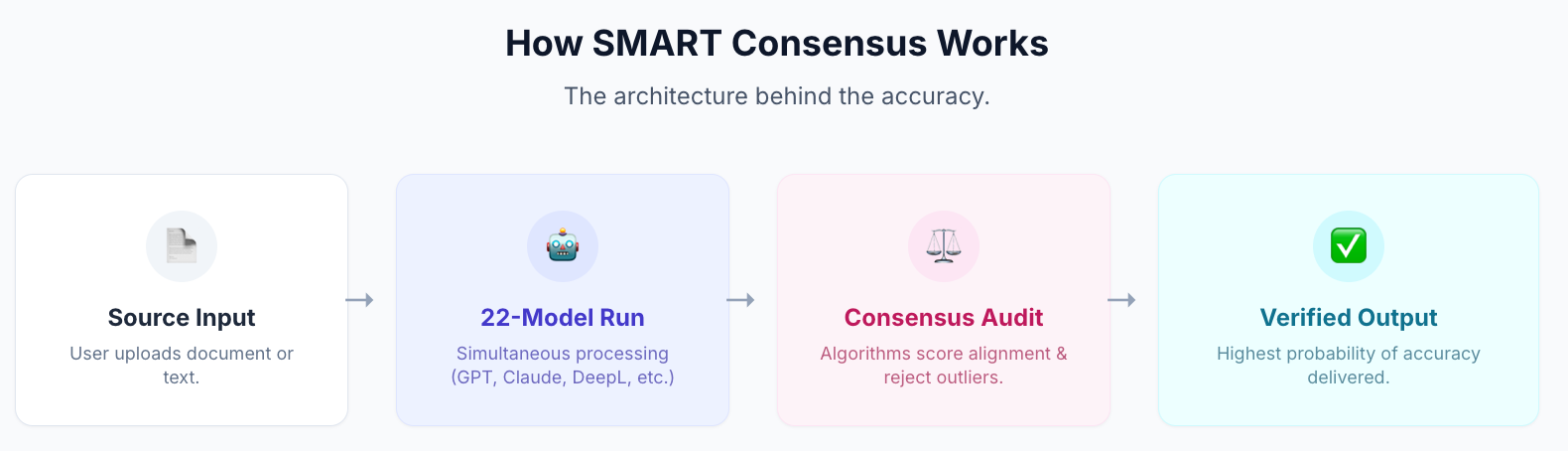
Det er det, MachineTranslation.com's SMART-system gør i praksis. Den kører 22 AI-modeller samtidigt (inklusive både Claude og DeepL) og viser det output, som flertallet af modellerne er enige om, sammen med kvalitetsresultater for hver enkelt. Konvergensen er signalet: når Claude og DeepL (og 20 andre modeller) lander på samme oversættelse, er sandsynligheden for, at den er korrekt, strukturelt højere end at stole på nogen af dem alene.
I MachineTranslation.com's interne benchmarks opnår denne konsensusmetode en aggregeret kvalitets score på 98,5 ud af 100 — sammenlignet med Claude 3.5 Sonnet på 93,8 og DeepL Classic på 94,2 som selvstændige motorer. Forskellen er ikke marginal: det er kløften mellem at stole på én models fortolkning og at vide, hvad de fleste modeller er enige om.
Til mange oversættelsesopgaver vil enten Claude eller DeepL tjene dig godt. For indhold, hvor det er fatalt at tage fejl, er det mere værd at se, hvor de er enige, end hver for sig.
Ofte stillede spørgsmål
1. Er Claude bedre end DeepL til oversættelse?
Det afhænger af indholdstypen. DeepL er bedre til korte europæiske sprogoversættelser med høj volumen, hvor flydende sprog og hastighed er prioriteret. Claude er bedre til lange dokumenter, komplekst indhold, der kræver ensartet terminologi på tværs af mange sider, og sprogpar uden for DeepLs 33-sprogsdækning. For de fleste professionelle arbejdsgange er det ærlige svar, at de er stærke på forskellige måder.
2. Hvilken er mere præcis: Claude eller DeepL?
I MachineTranslation.coms interne benchmark på tværs af 5.000 ord med blandet teknisk og markedsføringsmæssigt indhold scorede DeepL 94,2 % nøjagtighed, og Claude 3.5 Sonnet scorede 93,8 %. På det niveau er forskellen ikke praktisk meningsfuld for det meste indhold. Hvor Claude adskiller sig, er på længere dokumenter, hvor kontekstkonsistens er vigtig, og hvor DeepLs segment-for-segment-behandling kan introducere terminologisk afvigelse.
3. Understøtter DeepL lige så mange sprog som Claude?
Nej. DeepL understøtter 33 sprog og er særligt stærk i europæiske sprogpar. Claude håndterer et langt bredere udvalg af sprog, herunder mindre almindelige sprogpar, der falder uden for DeepLs træningsfokus. For ethvert sprog, der ikke er på DeepLs liste, er Claude den mere kapable mulighed.
4. Kan jeg bruge Claude og DeepL sammen?
Ikke direkte i noget af værktøjerne. MachineTranslation.com kører både Claude og DeepL samtidigt som en del af deres system med 22 modeller, og viser dig outputtet og kvalitetsresultatet for hver enkelt, og fremhæver den oversættelse, som flertallet af modellerne er enige om. For brugere, der ønsker at sammenligne begge dele uden at administrere separate integrationer, er det en praktisk måde at se, hvordan hvert værktøj håndterer det samme indhold.
5. Er DeepL eller Claude bedre til juridiske dokumenter?
For lange juridiske dokumenter, der kræver intern konsistens (defineret terminologi brugt konsekvent, formel sprogbrug opretholdt gennemgående, krydshenvisninger mellem klausuler), er Claudes kontekstvindue en meningsfuld fordel. For kortere juridiske tekster som standardklausuler eller korte aftaler er DeepLs output typisk flydende og hurtigt. For juridisk oversættelse med store konsekvenser, hvor fejl medfører ansvar, er menneskelig verifikation fortsat det passende sidste trin, uanset hvilket AI-værktøj der har produceret udkastet.
6. Hvordan er DeepLs priser sammenlignet med Claude?
DeepLs abonnementsplaner starter ved cirka $10,49/bruger/måned for professionel brug. Claude er prissat per token via API: $3,00 per million input tokens for Sonnet 4 og $15,00 for Opus 4. For individuelle brugere, der har et moderat volumen, er DeepLs abonnement generelt mere forudsigeligt. For API-workflows med højt volumen afhænger prissammenligningen af dokumentlængde og volumen, og ingen af dem er konsekvent billigere på tværs af alle anvendelsestilfælde.