June 10, 2026
जीपीटी-4.1 बनाम डीपसीक वी3: सटीकता, मतिभ्रम और अनुवाद प्रदर्शन की तुलना
2026 के मध्य में अनुवाद दल चुपचाप जो सवाल पूछ रहे हैं वह यह नहीं है कि क्या हमें एआई का उपयोग करना चाहिए?, वह निर्णय लिया जा चुका है। असली सवाल यह है कि किस एआई मॉडल को मानकीकृत किया जाए, और क्या हर भाषा युग्म, हर दस्तावेज़ प्रकार और हर बजट के लिए इसका उत्तर एक ही है।
पेशेवर अनुवाद वर्कफ़्लो के लिए अक्सर मूल्यांकन किए जाने वाले दो विकल्पों के रूप में GPT-4.1 और DeepSeek V3 उभर कर सामने आए हैं। वे वास्तव में विभिन्न दर्शनों का प्रतिनिधित्व करते हैं: एक OpenAI का एक कड़ाई से नियंत्रित, व्यावसायिक रूप से पॉलिश किया गया API है; दूसरा एक चीनी शोध प्रयोगशाला का एक ओपन-वेट, एमआईटी-लाइसेंस प्राप्त मॉडल है जिसने चुपके से WMT24 बेंचमार्क पर कई मालिकाना प्रतिस्पर्धियों को बेहतर प्रदर्शन किया। कोई भी सार्वभौमिक रूप से बेहतर नहीं है। प्रत्येक का मामला इस बात पर निर्भर करता है कि आप किसका अनुवाद कर रहे हैं, किसके लिए, और किन बाधाओं के तहत।
यह लेख अनुवादकों, स्थानीयकरण प्रबंधकों और उद्यम खरीदारों के लिए सबसे महत्वपूर्ण आयामों पर दोनों मॉडलों को तोड़ता है: वास्तविक भाषा युग्मों पर सटीकता, मतिभ्रम व्यवहार, शब्दावली पालन जैसे बाधित कार्यों को संभालना, और पैमाने पर किसी को भी चलाने की कुल लागत।
विषय-सूची
- यह तुलना अभी क्यों मायने रखती है
- प्रत्येक मॉडल वास्तव में क्या है
- आमने-सामने: अनुवाद सटीकता और बेंचमार्क प्रदर्शन
- करता है, और कब?
- ?
- लागत और परिनियोजन : बड़े पैमाने पर क्या बदलता है
- बिना किसी एक को चुने दोनों मॉडलों का परीक्षण कैसे करें
- अपने अनुवाद वर्कफ़्लो के लिए आपको कौन सा मॉडल चुनना चाहिए?
- अक्सर पूछे जाने वाले प्रश्न
- संबंधित तुलनाएँ
यह तुलना अभी क्यों मायने रखती है
अनुवाद खरीदार ऐतिहासिक रूप से मशीन अनुवाद का मूल्यांकन एक संकीर्ण अक्ष पर करते आए हैं: BLEU स्कोर बनाम कीमत। एलएलएम उस फ्रेम को पूरी तरह से तोड़ देते हैं। GPT-4.1 और DeepSeek V3 पारंपरिक अर्थों में मशीन ट्रांसलेशन (MT) इंजन नहीं हैं — वे मजबूत बहुभाषी क्षमताओं वाले सामान्य-उद्देश्य वाले मॉडल हैं, और अनुवाद कार्यों पर उनका प्रदर्शन आर्किटेक्चर, प्रशिक्षण डेटा और जिस तरह से आप उन्हें प्रॉम्प्ट करते हैं, उसके आधार पर भिन्न होता है।
वह परिवर्तनशीलता मूल्यांकन समस्या का मूल है। अंग्रेजी→स्पेनिश मार्केटिंग कॉपी पर दोनों मॉडलों का परीक्षण करने वाला एक स्थानीयकरण प्रबंधक लगभग समान आउटपुट गुणवत्ता देख सकता है। वही प्रबंधक अरबी→अंग्रेज़ी कानूनी दस्तावेजों का परीक्षण करेगा, उसे एक महत्वपूर्ण अंतर दिखाई देगा — लेकिन कौन सा मॉडल आगे निकलता है यह इस बात पर निर्भर करता है कि दस्तावेज़ में नामित संस्थाएं, तकनीकी शब्दजाल, या सांस्कृतिक संदर्भ शामिल हैं जिन्हें पैटर्न-मिलान के बजाय विश्व ज्ञान की आवश्यकता होती है।
दांव भी विषम हैं। डीपसीक वी3 चलाना, खासकर सेल्फ-होस्टेड, कई गुना सस्ता है। जीपीटी-4.1 की लागत काफी अधिक है। यदि दोनों मॉडल आपके विशिष्ट कार्यभार पर स्वीकार्य गुणवत्ता प्रदान करते हैं, तो लागत अंतर यह निर्धारित कर सकता है कि बड़े पैमाने पर एआई अनुवाद वर्कफ़्लो आर्थिक रूप से व्यवहार्य है या नहीं।
प्रत्येक मॉडल वास्तव में क्या है
जीपीटी-4.1: ओपनएआई का निर्देश-अनुकूलित प्रमुख मॉडल अप्रैल 2025 में जारी, जीपीटी-4.1 अब तक का ओपनएआई का सबसे निर्देश-पालक मॉडल
है। इसका हेडलाइन सुधार GPT-4o पर कच्ची अनुवाद प्रवाह (यह पहले से ही मजबूत था) के बजाय जटिल, बहु-भाग निर्देशों का पालन करने में सटीकता है। अनुवाद वर्कफ़्लो के लिए, यह विशेष रूप से सीमित कार्यों में मायने रखता है: क्लाइंट शब्दावली लागू करना, लंबे ग्रंथों में दस्तावेज़ स्वरूपण को संरक्षित करना, एक विशिष्ट रजिस्टर बनाए रखना, या अनुवाद न करें सूची का पालन करना।
GPT-4.1 एक मिलियन टोकन संदर्भ विंडो का समर्थन करता है, जिसका अर्थ है कि यह एक ही कॉल में पुस्तक-लंबाई वाले दस्तावेज़ों को संसाधित कर सकता है। संरचित आउटपुट कार्यों पर (JSON में अनुवाद मेमोरी उत्पन्न करना, अनुवाद के साथ-साथ सेगमेंट-स्तरीय गुणवत्ता स्कोर का उत्पादन करना, द्विभाषी तालिकाओं को प्रारूपित करना), यह अपने पूर्ववर्तियों की तुलना में स्पष्ट रूप से अधिक विश्वसनीय है। समझौता लागत है: GPT-4.1 अधिकांश विकल्पों की तुलना में उच्च मूल्य वर्ग में आता है, जिसमें DeepSeek V3 भी शामिल है।
DeepSeek V3: ओपन-सोर्स चैलेंजर
डीपसीक V3 (वर्तमान उत्पादन संस्करण डीपसीक-V3-0324 है) 685-अरब पैरामीटर वाला मॉडल है जो विशेषज्ञों के मिश्रण (Mixture-of-Experts) आर्किटेक्चर पर बनाया गया है — जिसका अर्थ है कि किसी भी दिए गए इनपुट के लिए इसके पैरामीटर का केवल एक उपसमूह सक्रिय होता है, जो कुल पैरामीटर की विशाल संख्या के बावजूद अनुमान लागत को कम रखता है। यह एमआईटी लाइसेंस के तहत जारी किया गया है, जिसका अर्थ है कि संगठन इसे स्वयं होस्ट कर सकते हैं, इसे फाइन-ट्यून कर सकते हैं, और किसी तीसरे पक्ष को प्रति-टोकन शुल्क के बिना व्यावसायिक रूप से तैनात कर सकते हैं।
मॉडल के अनुवाद प्रदर्शन ने WMT24 के बाद काफी ध्यान आकर्षित किया, जहां इसने चीनी↔अंग्रेजी, अरबी और कोरियाई भाषा युग्मों पर मजबूत BLEU और COMET स्कोर पोस्ट किए - कई मामलों में GPT-4o से बेहतर प्रदर्शन किया। एशियाई या मध्य पूर्वी भाषा युग्मों में भारी काम करने वाली टीमों के लिए, डीपसीक वी3 कोई समझौता विकल्प नहीं है। यह वास्तव में लागत के एक अंश पर प्रतिस्पर्धी है।
आमने-सामने: अनुवाद सटीकता और बेंचमार्क प्रदर्शन आयाम GPT-4.1 DeepSeek V3 संदर्भ विंडो 1,000,000 टोकन ~64,000 टोकन (मानक) आर्किटेक्चर सघन ट्रांसफार्मर मिक्सचर-ऑफ-एक्सपर्ट्स (685B पैरामीटर्स) लाइसेंस मालिकाना ओपन-सोर्स (MIT) सेल्फ-होस्टिंग उपलब्ध नहीं उपलब्ध WMT24 चीनी↔अंग्रेजी मजबूत बहुत
| मजबूत, कई जोड़ों पर GPT-4o से बेहतर प्रदर्शन | किया WMT24 अरबी अनुवाद प्रतिस्पर्धी मजबूत, | विशेष रूप से विशेषीकृत पाठ पर निर्देश-पालन GPT-4o |
|---|---|---|
| बनाम सर्वश्रेष्ठ-इन-क्लास अच्छा; जटिल बहु-चरणीय | संकेतों पर कम सुसंगत संरचित आउटपुट अत्यधिक विश्वसनीय विश्वसनीय; | लंबे आउटपुट पर मामूली स्वरूपण बहाव मतिभ्रम की प्रवृत्ति GPT-4o बनाम |
| कम कम-संसाधन वाले जोड़ों पर | कभी-कभी सापेक्ष एपीआई लागत उच्च काफी | कम उच्च-संसाधन भाषा जोड़ों (अंग्रेजी, फ्रेंच, स्पेनिश, |
| जर्मन, चीनी, | जापानी) पर सामान्य | अनुवाद सटीकता के लिए, |
| दोनों मॉडल एक | ऐसे स्तर पर | प्रदर्शन |
| करते हैं जिसे | पेशेवर | अनुवादक पोस्ट-एडिट रेडी |
| के रूप | में | वर्णित करते |
| हैं। | ||
केवल प्रवाह और पर्याप्तता के बीच का अंतर अधिकांश टीमों के लिए खरीद निर्णय लेने के लिए पर्याप्त बड़ा नहीं है।
सार्थक अंतर तीन विशिष्ट परिदृश्यों में उभरते हैं: कम-संसाधन वाली भाषाएँ, बाधित कार्य, और मतिभ्रम-प्रवण दस्तावेज़ प्रकार।
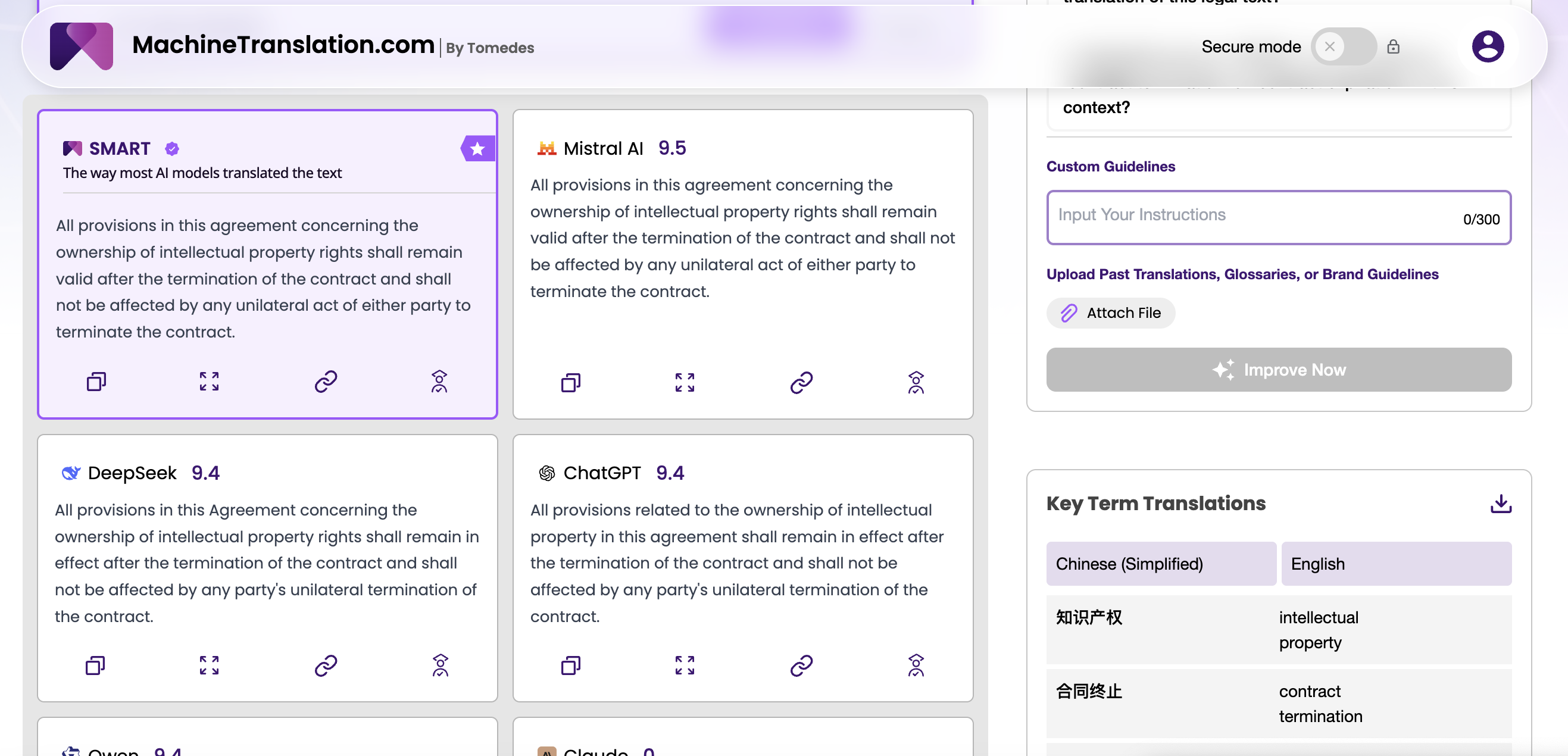
कौन सा मॉडल अधिक मतिभ्रम करता है, और कब?
अनुवाद में मतिभ्रम सामान्य-उद्देश्य वाले उत्पादन में मतिभ्रम के समान नहीं है। मॉडल एक स्रोत पाठ से काम कर रहा है, यह अपने मन से तथ्य नहीं गढ़ रहा है। यहाँ मतिभ्रम के रूप में स्रोत में न होने वाली अतिरिक्त सामग्री, छोड़े गए खंड या प्रतिस्थापित नामित संस्थाएँ प्रकट होती हैं। कानूनी या चिकित्सा अनुवाद में, इनमें से कोई भी त्रुटि गंभीर परिणाम दे सकती है।
GPT-4.1 में GPT-4o की तुलना में मापी गई कम भ्रांति दर दिखाई देती है, खासकर लंबे दस्तावेज़ों पर जहाँ OpenAI के पहले के मॉडल बाद के खंडों में स्रोत से भटकने लगते थे। एक मिलियन टोकन कॉन्टेक्स्ट विंडो और बेहतर इंस्ट्रक्शन-फॉलोइंग का संयोजन GPT-4.1 को विशेष प्रॉम्प्टिंग रणनीतियों की आवश्यकता के बिना लंबे समय तक स्रोत के प्रति निष्ठा बनाए रखने में मदद करता है। नियामक फाइलिंग, उत्पाद दस्तावेज़ीकरण या अनुबंधों को संसाधित करने वाले एंटरप्राइज़ खरीदारों के लिए, यह एक महत्वपूर्ण विश्वसनीयता उन्नयन है।
डीपसीक V3 की मतिभ्रम प्रोफ़ाइल चरित्र में भिन्न है। अच्छी तरह से समर्थित भाषा युग्मों (चीनी, अंग्रेजी, अरबी) पर, यह आम तौर पर विश्वसनीय है। कम-संसाधन वाले जोड़ों पर जोखिम बढ़ जाता है: कोरियाई→स्वाहिली, अरबी→वियतनामी, या कोई भी जोड़ी जहाँ प्रशिक्षण कॉर्पस में एक भाषा का प्रतिनिधित्व कम है। इन मामलों में, डीपसीक वी3 को विशेष रूप से तब, विश्वसनीय लगने वाली लेकिन स्रोत-असमर्थित सामग्री उत्पन्न करते हुए देखा गया है, जब स्रोत में अस्पष्ट नामित संस्थाएं या डोमेन-विशिष्ट शब्दावली हो।
व्यावहारिक निहितार्थ: यदि आपका भाषा जोड़ी पोर्टफोलियो उच्च-संसाधन भाषाओं में केंद्रित है, तो डीपसीक वी3 के मतिभ्रम का जोखिम मानक क्यूए प्रक्रियाओं के साथ प्रबंधनीय है। यदि आप कम-संसाधन वाले जोड़ों में बड़े पैमाने पर अनुवाद चला रहे हैं, तो GPT-4.1 की अतिरिक्त विश्वसनीयता लागत प्रीमियम को उचित ठहरा सकती है।
💬 हम प्लेटफ़ॉर्म पर लगातार जो देखते हैं वह यह है कि हैलुसिनेशन पर GPT-4.1 और DeepSeek V3 के बीच का अंतर मात्रा के बारे में नहीं है, बल्कि यह इस बारे में है कि यह कहाँ होता है। अंग्रेजी, फ्रेंच या स्पेनिश सामग्री पर, अधिकांश पेशेवर अनुवादक विश्वसनीयता में कोई महत्वपूर्ण अंतर नहीं देखेंगे। डीपसीक V3 के साथ समस्याएँ उन कोरियाई या अरबी दस्तावेज़ों पर सामने आती हैं जिनमें अपरिचित उचित संज्ञाएँ या अत्यधिक डोमेन-विशिष्ट शब्दावली होती है। GPT-4.1 उन एज केसों को अधिक रूढ़िवादी रूप से संभालता है, यह किसी गैप को विश्वसनीय लगने वाली चीज़ से भरने की संभावना कम रखता है।
— MachineTranslation.com पर भाषाविद्
कौन सा मॉडल बाधित अनुवाद को बेहतर ढंग से संभालता है?
बाधित अनुवाद (जहां मॉडल को शब्दावली का सम्मान करना चाहिए, ब्रांड रजिस्टर बनाए रखना चाहिए, कुछ शब्दों का अनुवाद करने से बचना चाहिए, या हेडर और फुटनोट जैसी दस्तावेज़ संरचना को संरक्षित करना चाहिए) वह है जहां GPT-4.1 के आर्किटेक्चर के फायदे सबसे अधिक मूर्त हो जाते हैं।
जब आप 200-शब्दों की शब्दावली के साथ एक सिस्टम प्रॉम्प्ट प्रदान करते हैं और मॉडल को किसी भी स्रोत खंड को फ़्लैग करने का निर्देश देते हैं जहां सटीक मिलान नहीं मिल सकता है, तो GPT-4.1 उन निर्देशों का पालन उन निरंतरता के साथ करता है जो पहले के मॉडल कुछ सौ टोकन से आगे बनाए नहीं रख सकते थे। एक मिलियन टोकन के संदर्भ विंडो में, इसका मतलब है कि आप एक जटिल शब्दावली बाधा के साथ 400 पृष्ठों के तकनीकी मैनुअल का एक ही कॉल में अनुवाद कर सकते हैं और पूरे में सुसंगत शब्दावली अनुप्रयोग की उम्मीद कर सकते हैं।
DeepSeek V3 सीधी बाधाओं को पर्याप्त रूप से संभालता है - एकल-शब्द अनुवाद न करें निर्देश, बुनियादी रजिस्टर वरीयताएँ, सरल स्वरूपण नियम। जहाँ यह कम प्रदर्शन करता है, वह जटिल, यौगिक निर्देश सेटों में है। जैसे-जैसे एक साथ आने वाली बाधाओं की संख्या बढ़ती है, डीपसीक वी3 कुछ निर्देशों को दूसरों पर प्राथमिकता देना शुरू कर देता है, जिनका परीक्षण किए बिना अनुमान लगाना मुश्किल होता है। बहु-स्तरीय शैली गाइड और बड़े अनुवाद मेमोरी का प्रबंधन करने वाली स्थानीयकरण टीमों के लिए, यह असंगति डाउनस्ट्रीम क्यूए ओवरहेड बनाती है जो आंशिक रूप से मॉडल के लागत लाभ को ऑफसेट करती है।
मानक सामग्री (सामान्य व्यावसायिक संचार, विपणन प्रतिलिपि, ई-कॉमर्स उत्पाद विवरण) के शुद्ध, अप्रतिबंधित अनुवाद के लिए, दो मॉडलों के बीच बाधा-हैंडलिंग अंतर काफी हद तक अप्रासंगिक है। एंटरप्राइज़-ग्रेड वर्कफ़्लो चलाने वाली टीमों के लिए अंतर सबसे ज़्यादा मायने रखता है, जहाँ अनुवाद बहु-चरणीय स्थानीयकरण पाइपलाइन में एक कदम है।
💬 हमने दोनों मॉडलों को एक ही शब्दावली के विरुद्ध कानूनी दस्तावेज़ों के एक सेट पर चलाया, जो लगभग 120,000 शब्दों का आठ भाषा युग्मों में था। GPT-4.1 ने शब्दावली की बाधाओं का लगभग पूरी तरह से सम्मान किया। डीपसीक वी3 करीब था, लेकिन यह कभी-कभी एक पसंदीदा शब्द को एक ऐसे समानार्थक शब्द से बदल देता था जिससे हमारे ग्राहकों ने विशेष रूप से हमें बचने के लिए कहा था। उस मात्रा में, 'लगभग' पर्याप्त नहीं है। अनियंत्रित सामग्री के लिए, हम डीपसीक V3 का उपयोग करते हैं और लागत बचत महत्वपूर्ण है। क्लाइंट-अनुमोदित शब्दावली वाली किसी भी चीज़ के लिए, हम अभी भी GPT-4.1 चला रहे हैं।
— मशीन ट्रांसलेशन.कॉम पर लोकलाइज़ेशन मैनेजर
लागत और परिनियोजन: बड़े पैमाने पर क्या बदलता है
लागत वह जगह है जहाँ दोनों मॉडल सबसे अधिक भिन्न होते हैं, और जहाँ मूल्यांकन को प्रति-टोकन मूल्य निर्धारण से अधिक का हिसाब रखना पड़ता है।
GPT-4.1 को प्रीमियम टियर पर मूल्यवान किया गया है। ओपनएआई एपीआई के माध्यम से प्रति माह लाखों शब्दों को संसाधित करने वाले संगठनों के लिए, वह लागत तेज़ी से बढ़ती है। मॉडल सेल्फ-होस्टिंग के लिए उपलब्ध नहीं है, जिसका अर्थ है कि प्रत्येक टोकन पर एपीआई शुल्क लगता है जिसे बुनियादी ढांचे में निवेश करके कम नहीं किया जा सकता है।
डीपसीक वी3 की लागत प्रोफ़ाइल मौलिक रूप से भिन्न है। डीपसीक एपीआई के माध्यम से, यह जीपीटी-4.1 की तुलना में प्रति टोकन काफी सस्ता है। सेल्फ-होस्टेड, अर्थशास्त्र और भी बदल जाता है: जीपीयू इंफ्रास्ट्रक्चर वाले संगठन डीपसीक वी3 को प्रति-टोकन लाइसेंसिंग के बजाय मुख्य रूप से कंप्यूट द्वारा निर्धारित लागत पर चला सकते हैं। उच्च-मात्रा वाले अनुवाद कार्यों (वैश्विक ई-कॉमर्स कैटलॉग, बहुभाषी सामग्री पाइपलाइन, नियामक दस्तावेज़ प्रसंस्करण) के लिए, यह अंतर उद्यम स्तर पर सालाना लाखों डॉलर का हो सकता है।
डेटा-संवेदनशील क्षेत्रों के लिए डीपसीक V3 का ओपन-सोर्स लाइसेंस भी मायने रखता है। कानूनी, वित्तीय और स्वास्थ्य सेवा संगठन जो ग्राहक दस्तावेज़ों को बाहरी एपीआई पर नहीं भेज सकते, वे डीपसीक वी3 को ऑन-प्रिमाइसेस पर तैनात कर सकते हैं। GPT-4.1 कोई समतुल्य विकल्प प्रदान नहीं करता है।
निर्णय नियम अपेक्षाकृत स्पष्ट है: यदि आपका वर्कलोड उच्च-मात्रा वाला है, आपकी भाषा जोड़ी अच्छी तरह से समर्थित है, और आपकी डेटा गवर्नेंस नीतियां एपीआई सेवाओं या ऑन-प्रिमाइसेस परिनियोजन की अनुमति देती हैं, तो DeepSeek V3 काफी कम लागत पर प्रतिस्पर्धी गुणवत्ता प्रदान करता है। यदि आपके कार्यभार में सीमित अनुवाद, लंबे दस्तावेज़ों की सटीकता, या कम-संसाधन वाली भाषाएँ शामिल हैं, तो GPT-4.1 की विश्वसनीयता प्रीमियम के लायक हो सकती है।
दोनों मॉडलों का परीक्षण कैसे करें, बिना किसी एक को चुने
अधिकांश स्थानीयकरण टीमों के लिए मॉडल चयन में व्यावहारिक बाधा बेंचमार्क को समझना नहीं है — यह दोनों मॉडलों के साथ स्वतंत्र एपीआई एकीकरण स्थापित करने, तुलनीय परीक्षण स्थितियाँ डिज़ाइन करने और अपनी सामग्री पर एक सार्थक मूल्यांकन चलाने की कठिनाई है।
MachineTranslation.com उस बाधा को दूर करता है। यह प्लेटफ़ॉर्म GPT-4.1 और DeepSeek V3 को अगल-बगल चलाता है, जिससे पेशेवर अनुवादकों और स्थानीयकरण प्रबंधकों को एक ही स्रोत पाठ को एक साथ दोनों मॉडलों में सबमिट करने और वास्तविक समय में आउटपुट की तुलना करने की क्षमता मिलती है — बिना किसी अलग API कुंजी के, बिना किसी खरीद प्रक्रिया के, और किसी भी मॉडल के प्रति प्रतिबद्ध हुए बिना। यह महत्वपूर्ण है क्योंकि डेटासेट स्तर पर बेंचमार्क प्रदर्शन हमेशा आपकी विशिष्ट सामग्री पर प्रदर्शन की भविष्यवाणी नहीं करता
है। एक मॉडल जो WMT24 चीनी→अंग्रेजी समाचार पाठ पर मजबूत COMET स्कोर पोस्ट करता है, वह आपकी कंपनी की विशिष्ट शब्दावली या डोमेन पर खराब प्रदर्शन कर सकता है। केवल वही मूल्यांकन निर्णय-प्रासंगिक होता है जो आपके अपने दस्तावेज़ों पर, आपकी अपनी बाधाओं के साथ, आपकी अपनी भाषा युग्मों में किया जाता है।
MachineTranslation.com का तटस्थ मल्टी-मॉडल प्लेटफ़ॉर्म के रूप में स्थान का मतलब है कि GPT-4.1 या DeepSeek V3 में से किसी का भी पक्ष लेने के लिए इसका कोई व्यावसायिक प्रोत्साहन नहीं है। प्लेटफ़ॉर्म की भूमिका आपको स्वयं वह निर्णय लेने के लिए तुलना डेटा प्रदान करना है, और फिर मूल्यांकन पूरा होने के बाद उत्पादन पैमाने पर आपके द्वारा चुने गए किसी भी मॉडल को चलाना है। हालांकि, ज़ाहिर है, यह आपको वह अनुवाद भी देता है जिस पर अधिकांश AI मॉडल डिफ़ॉल्ट सर्वश्रेष्ठ अनुवाद के रूप में सहमत होते हैं।
उन टीमों के लिए भी जो OpenAI मॉडल टियर में मूल्यांकन कर रही हैं, GPT-4.1 की अन्य OpenAI मॉडल (GPT-4.5 और GPT-4o सहित) से तुलना, मॉडल संस्करण के प्रति प्रतिबद्ध होने से पहले उपयोगी संदर्भ प्रदान करती है। और उन टीमों के लिए जिन्होंने 2025 की शुरुआत में GPT-4o की तुलना में DeepSeek V3 का मूल्यांकन किया था, यह लेख GPT-4.1 के रिलीज़ के साथ क्या बदला है, इसे कवर करता है।
आपको अपने अनुवाद वर्कफ़्लो के लिए कौन सा मॉडल चुनना चाहिए?
एकल सिफ़ारिश के बजाय, निम्नलिखित ढाँचा निर्णय तर्क को दर्शाता है जो अधिकांश पेशेवर अनुवाद टीमों को उपयोगी लगेगा:
-
अपनी भाषा जोड़ियों से शुरुआत करें। यदि आपका पोर्टफोलियो चीनी↔अंग्रेजी, अरबी, या कोरियाई में केंद्रित है, तो डीपसीक वी3 का WMT24 प्रदर्शन इसे स्वाभाविक पहला परीक्षण बनाता है। यदि आप मुख्य रूप से सीमित शब्दावली वाली यूरोपीय भाषाओं में काम कर रहे हैं, तो GPT-4.1 पहले दिन से ही अधिक सुसंगत आउटपुट उत्पन्न करने की संभावना है।
-
अपनी बाधा जटिलता का आकलन करें। एक-स्तरीय बाधाओं (एक शब्दावली, एक रजिस्टर) को किसी भी मॉडल द्वारा पर्याप्त रूप से संभाला जाता है। बहु-स्तरीय बाधाएं (शब्दावली + प्रारूप + अनुवाद न करें सूची + क्यूए स्कोरिंग), जीपीटी-4.1 वर्तमान में अधिक विश्वसनीय है।
-
लागत अंतर के मुकाबले अपने वॉल्यूम का नक्शा बनाएं। प्रति माह 500,000 शब्दों से कम होने पर, पूर्ण API लागत अंतर आपके बजट पर महत्वपूर्ण रूप से प्रभाव नहीं डाल सकता है। उस सीमा से ऊपर, DeepSeek V3 के लागत लाभ को अनदेखा करना कठिन होता जा रहा है।
-
अपनी डेटा शासन आवश्यकताओं को ध्यान में रखें। यदि दस्तावेज़ आपके बुनियादी ढांचे को नहीं छोड़ सकते हैं, तो डीपसीक वी3 सेल्फ-होस्टेड वर्तमान में दो में से एकमात्र व्यवहार्य विकल्प है।
-
अपने कंटेंट पर मूल्यांकन चलाएं, बेंचमार्क पर नहीं। मशीनट्रांसलेशन.कॉम का उपयोग करके अपने वास्तविक वर्कलोड से प्रतिनिधि नमूने दोनों मॉडलों में सबमिट करें और प्रतिबद्धता से पहले अपने स्वयं के गुणवत्ता मानदंडों के विरुद्ध आउटपुट को स्कोर करें।
वर्तमान एआई अनुवाद परिदृश्य में ये मॉडल कहां स्थित हैं, इस पर व्यापक दृष्टिकोण के लिए, 2026 के सर्वश्रेष्ठ एआई अनुवाद उपकरण पूर्ण प्रतिस्पर्धी क्षेत्र को कवर करते हैं, जिसमें एलएलएम की तुलना उद्देश्य-निर्मित अनुवाद बुनियादी ढांचे से कैसे की जाती है।
अक्सर पूछे जाने वाले प्रश्न
1. क्या GPT-4.1 अनुवाद के लिए DeepSeek V3 से बेहतर है?
कोई भी मॉडल सार्वभौमिक रूप से बेहतर नहीं है। जीपीटी-4.1 सीमित अनुवाद कार्यों, लंबे दस्तावेज़ों की सटीकता और कम-संसाधन वाली भाषा युग्मों पर डीपसीक वी3 से बेहतर प्रदर्शन करता है, जहाँ मतिभ्रम का जोखिम अधिक होता है। डीपसीक वी3 कई डब्ल्यूएमटी24 बेंचमार्क (विशेष रूप से चीनी↔अंग्रेजी, अरबी और कोरियाई) पर जीपीटी-4.1 से मेल खाता है या उससे बेहतर प्रदर्शन करता है और बड़े पैमाने पर चलाने या स्वयं-होस्ट करने पर काफी सस्ता है।
2. क्या डीपसीक V3 GPT-4.1 से अधिक मतिभ्रम करता है?
उच्च-संसाधन वाली भाषा जोड़ियों पर, मतिभ्रम का अंतर अपेक्षाकृत छोटा है। कम-संसाधन वाले जोड़ों और दुर्लभ नामित संस्थाओं वाली डोमेन-विशिष्ट सामग्री पर अंतर चौड़ा हो जाता है, जहां डीपसीक वी3 ने स्रोत-असमर्थित परिवर्धन या प्रतिस्थापन की उच्च दर दिखाई है। GPT-4.1, GPT-4o की तुलना में कम मतिभ्रम प्रदर्शित करता है, विशेष रूप से लंबे दस्तावेज़ों पर।
3. क्या मैं DeepSeek V3 का व्यावसायिक रूप से उपयोग कर सकता हूँ?
हाँ। डीपसीक V3 एमआईटी लाइसेंस के तहत जारी किया गया है, जो फाइन-ट्यूनिंग और सेल्फ-होस्टिंग सहित व्यावसायिक उपयोग की अनुमति देता है। ऐसे संगठन जो बाहरी एपीआई को दस्तावेज़ नहीं भेज सकते, वे डीपसीक वी3 को अपने स्वयं के बुनियादी ढांचे पर तैनात कर सकते हैं। GPT-4.1 के लिए OpenAI की सेवा की शर्तों के तहत OpenAI API का उपयोग आवश्यक है और यह स्वयं-होस्टिंग के लिए उपलब्ध नहीं
है। चीनी से अंग्रेजी अनुवाद के लिए कौन सा मॉडल बेहतर है?
WMT24 बेंचमार्क परिणामों के आधार पर डीपसीक V3 का चीनी↔अंग्रेजी पर बढ़त है। हालांकि, चीनी→अंग्रेजी अनुवाद के लिए जिसमें सीमित शब्दावली, कानूनी सटीकता, या जटिल स्वरूपण शामिल है, GPT-4.1 की निर्देश-पालन क्षमता इसे उत्पादन वर्कफ़्लो में अधिक विश्वसनीय बनाती है जहाँ एक मानव अनुवादक आउटपुट को पोस्ट-एडिट करेगा।
5. क्या मैं चुनने से पहले जीपीटी-4.1 और डीपसीक वी3 का अगल-बगल परीक्षण कर सकता हूँ?
हाँ — MachineTranslation.com दोनों मॉडलों को एक साथ (और 20+ अन्य) चलाता है और आपको वास्तविक समय में अपनी सामग्री पर आउटपुट की तुलना करने देता है, बिना अलग एपीआई खातों या खरीद प्रक्रिया के।
6. डीपसीक V3 अनुवाद के लिए क्लॉड की तुलना में कैसा है?
जो टीमें एंथ्रोपिक के मॉडल का भी मूल्यांकन कर रही हैं, उनके लिए क्लॉड बनाम डीपसीक V3 तुलना अनुवाद-प्रासंगिक परिदृश्यों में आर्किटेक्चर, सटीकता और परिनियोजन विकल्पों में प्रमुख अंतरों को कवर करती है।