June 2, 2026
ग्रोक बनाम लामा अनुवाद के लिए: कौन सा एआई मॉडल बेहतर प्रदर्शन करता है?
दो बहुत अलग दर्शन एक अनुवाद कार्य में उतरते हैं।
ग्रोक को xAI द्वारा बनाया गया है, यह वेब और X से वास्तविक समय में लाइव डेटा से जुड़ता है, और ऐसी भाषा के लिए ट्यून किया गया है जो तेजी से बदलती है — ट्रेंडिंग स्लैंग, समसामयिक घटनाएँ, और सांस्कृतिक संदर्भ जो सप्ताह-दर-सप्ताह बदलते रहते हैं। लामा मेटा द्वारा बनाया गया है, इसे दुनिया के लिए ओपन-सोर्स जारी किया गया है, और इसे आपकी अपनी अवसंरचना पर डाउनलोड, संशोधित और परिनियोजित करने के लिए डिज़ाइन किया गया है, शून्य प्रति-टोकन लागत पर।
वे दोनों MachineTranslation.com के 24-मॉडल सर्वसम्मति प्रणाली के भीतर हैं। वे दोनों अनुवाद करते हैं। और वे वास्तव में विभिन्न प्रकार के अनुवाद कार्य के लिए उपयुक्त हैं।
यह लेख बताता है कि प्रत्येक वास्तव में किसमें अच्छा है, प्रत्येक कहाँ कम पड़ता है, और क्या होता है जब आप उन्हें एक ही सामग्री पर साथ-साथ परखते हैं।
इस लेख में
- ग्रोक क्या है और यह अनुवाद को कैसे संभालता है?
- लामा क्या है और यह अनुवाद को कैसे संभालता है?
- ग्रोक बनाम लामा: अनुवाद गुणवत्ता की तुलना
- क्या अनुवाद के लिए लामा ग्रोक से बेहतर है?
- दस्तावेज़ अनुवाद के लिए कौन सा बेहतर है?
- क्या मैं अनुवाद के लिए लामा को स्थानीय रूप से चला सकता हूँ?
- MachineTranslation.com ग्रोक और लामा दोनों का उपयोग कैसे करता है
- अक्सर पूछे जाने वाले प्रश्न
ग्रोक क्या है और यह अनुवाद को कैसे संभालता है?

ग्रोक को एलन मस्क द्वारा स्थापित एआई कंपनी xAI द्वारा विकसित किया गया है, और इसे सामान्य वेब डेटा और X (पूर्व में ट्विटर) से लाइव सामग्री के संयोजन पर प्रशिक्षित किया गया है। वर्तमान संस्करण ग्रॉक 3 और ग्रॉक 4 हैं, जिन्हें क्रमशः फरवरी और जुलाई 2025 में जारी किया गया। ग्रोक को अधिकांश एआई मॉडलों से वास्तुकला की दृष्टि से अलग बनाने वाली बात वास्तविक समय डेटा तक पहुंच है — यह अनुमान के दौरान वर्तमान वेब सामग्री और एक्स प्लेटफॉर्म से जानकारी खींच सकता है, बजाय इसके कि एक निश्चित प्रशिक्षण स्नैपशॉट पर काम करे।
अनुवाद के लिए, यह एक विशिष्ट और संकीर्ण तरीके से मायने रखता है। ग्रोक विशेष रूप से ऐसी सामग्री का अनुवाद करने में सक्षम है जो तेज़ी से बदलने वाली वर्तमान घटनाओं, प्रचलित शब्दावली, इंटरनेट स्लैंग और सांस्कृतिक संदर्भों का उल्लेख करती है। यदि आपको किसी हालिया समाचार कहानी, किसी उत्पाद लॉन्च की घोषणा, या तीन सप्ताह पहले सामने आए किसी वायरल वाक्यांश के बारे में किसी सोशल मीडिया पोस्ट का अनुवाद करना है, तो Grok की लाइव डेटा एक्सेस इसे वह संदर्भ देती है जो पिछले साल के डेटा पर प्रशिक्षित मॉडल के पास बस नहीं होता।
यह एक वास्तविक लाभ है। यह काफी विशिष्ट भी है।
समय-संवेदनशील सामग्री के बाहर, ग्रोक अनुवाद के लिए अधिकांश फ्रंटियर एलएलएम (LLMs) की तरह व्यवहार करता है: प्रमुख भाषा युग्मों पर सक्षम, कम-संसाधन वाली भाषाओं पर कमजोर, और उसी संरचनात्मक सीमा के अधीन है जो सभी एकल-मॉडल प्रणालियाँ साझा करती हैं — अपने स्वयं के आउटपुट को सत्यापित करने के लिए कोई तंत्र नहीं।
उपभोक्ता उपयोग के लिए ग्रोक X Premium+ ($22/माह) या SuperGrok ($30/माह) के माध्यम से उपलब्ध है, और xAI के API के माध्यम से लगभग $0.20 प्रति मिलियन इनपुट टोकन पर उपलब्ध है। यह स्वयं-होस्टेड नहीं हो सकता है। कस्टम डेटा पर फाइन-ट्यूनिंग उपलब्ध नहीं है।
लामा क्या है और यह अनुवाद को कैसे संभालता है?
लामा मेटा के ओपन-वेट एआई मॉडल परिवार का हिस्सा है। वर्तमान पीढ़ी (लामा 4 मेवरिक और लामा 4 स्काउट) को 2025 में जारी किया गया था और यह क्षमता और भाषा कवरेज दोनों में लामा 3 से एक महत्वपूर्ण छलांग है। लामा 4, 200 से अधिक भाषाओं का समर्थन करता है और मल्टीमॉडल है, जिसका अर्थ है कि यह टेक्स्ट के साथ-साथ छवियों को भी संसाधित कर सकता है। वह मल्टीमॉडल क्षमता अनुवाद के लिए व्यावहारिक रूप से प्रासंगिक है: एम्बेडेड छवियों वाले दस्तावेज़, स्कैन किए गए पीडीएफ, और टेक्स्ट लेबल वाले चार्ट को लामा 4 उन तरीकों से संभाल सकता है जो केवल टेक्स्ट वाले मॉडल नहीं कर सकते।
लामा की परिभाषित विशेषता यह है कि आप इसके साथ क्या कर सकते हैं। क्योंकि मॉडल के वज़न वाणिज्यिक-उपयोग लाइसेंस के तहत सार्वजनिक रूप से उपलब्ध हैं, सही बुनियादी ढाँचे वाली टीमें लामा डाउनलोड कर सकती हैं, इसे अपने सर्वर पर चला सकती हैं, इसे डोमेन-विशिष्ट डेटा पर फाइन-ट्यून कर सकती हैं, और किसी बाहरी एपीआई को कुछ भी भेजे बिना संवेदनशील सामग्री को संसाधित कर सकती हैं। कानूनी, चिकित्सा और वित्तीय अनुवाद वर्कफ़्लो के लिए जहाँ डेटा रेज़िडेंसी एक अनुपालन आवश्यकता है, यह एक 'होना अच्छा है' वाली चीज़ नहीं है — यह एकमात्र स्वीकार्य विकल्प है।
मानक सामग्री पर लामा का अनुवाद आउटपुट मज़बूत है लेकिन क्षेत्र में सबसे ऊपर नहीं है। इंटेंटो की स्टेट ऑफ ट्रांसलेशन ऑटोमेशन 2025, जिसने 11 भाषा युग्मों में लामा 4 मेवरिक और लामा 4 स्काउट का मूल्यांकन किया, में पाया गया कि किसी भी व्यक्तिगत भाषा युग्म मूल्यांकन में कोई भी मॉडल शीर्ष-14 समाधानों में से नहीं था। यह कहने के लिए एक ईमानदार मानदंड है: लामा सक्षम है, लेकिन GPT-4.1, Claude Opus 4, और Gemini 2.5 Pro जैसे मॉडल उन युग्मों पर इससे बेहतर प्रदर्शन करते हैं जिनका इंटेंटो ने मूल्यांकन किया। लामा अपनी जगह अपने ओपन-सोर्स लचीलेपन, अपनी भाषा की व्यापकता और उच्च-मात्रा वाले वर्कफ़्लो के लिए अपनी लागत संरचना के कारण बनाता है।
ग्रोक बनाम लामा: अनुवाद गुणवत्ता की तुलना की गई
जब MachineTranslation.com ने Grok और Llama दोनों का परीक्षण एक ही 500-शब्दों वाले अंग्रेजी से स्पेनिश मार्केटिंग टेक्स्ट पर किया, तो Grok ने 10 में से 8.1 का गुणवत्ता स्कोर प्राप्त किया और Llama ने 7.9 स्कोर किया। इसी टेक्स्ट का जापानी में अनुवाद करने पर, ग्रोक ने 7.4 और लामा ने 7.6 अंक प्राप्त किए — एक छोटा सा उलटफेर जो एशियाई भाषाओं के लिए लामा 4 के मजबूत बहुभाषी प्रशिक्षण डेटा की गहराई को दर्शाता है। दो मॉडलों के बीच स्पेनिश पाठ पर सहमति दर 74% थी; जापानी पाठ पर यह घटकर 61% हो गई, जो यह दर्शाता है कि विशेष रूप से जापानी के लिए, दोनों मॉडल स्रोत पाठ के महत्वपूर्ण हिस्सों की अलग-अलग व्याख्या कर रहे थे।
यह सहमति डेटा विचारणीय है। जब ग्रोक और लामा किसी अनुवाद पर सहमत होते हैं, तो आप उस अभिसरण को एक आत्मविश्वास संकेत के रूप में पढ़ सकते हैं — दो वास्तुशिल्प रूप से भिन्न मॉडल, विभिन्न डेटा पर प्रशिक्षित, एक ही आउटपुट पर पहुँचते हुए। जब वे भिन्न होते हैं, जैसा कि उन्होंने उस परीक्षण में 39% जापानी वाक्यों पर किया था, तो वह भिन्नता एक संकेत है: कि या तो उस अंश में वास्तविक व्याख्यात्मक अस्पष्टता है, या मॉडलों में से एक ने ऐसा विकल्प चुना जो दूसरा नहीं चुनता।
| ग्रोक (ग्रोक 4) | लामा (लामा 4 मेवरिक) | |
|---|---|---|
| रीयल-टाइम डेटा एक्सेस | हाँ | नहीं |
| सेल्फ-होस्ट करने योग्य | नहीं | हाँ |
| फाइन-ट्यून करने योग्य | नहीं | हाँ |
| भाषाएँ | 40+ | 200+ |
| मल्टीमॉडल (छवियाँ/दस्तावेज़) | सीमित | हाँ |
| एपीआई लागत | ~$0.20/M इनपुट टोकन | मुफ्त (सेल्फ-होस्टेड) |
| सर्वश्रेष्ठ सामग्री प्रकार | ट्रेंडिंग/सोशल/समाचार | उच्च-मात्रा, डोमेन-विशिष्ट |
| MachineTranslation.com गुणवत्ता स्कोर (EN-ES) | 8.1/10 | 7.9/10 |
| MachineTranslation.com गुणवत्ता स्कोर (EN-JA) | 7.4/10 | 7.6/10 |
कोई भी मॉडल हावी नहीं है। अंतर वास्तविक हैं, लेकिन मानक सामग्री पर नाटकीय नहीं। उपयोग का मामला तय करता है कि वास्तव में कौन सा अधिक उपयोगी है — और अधिकांश पेशेवर अनुवाद वर्कफ़्लो के लिए, कोई भी अपने आप में सही जवाब नहीं है।
क्या लामा अनुवाद के लिए ग्रोक से बेहतर है?
एक सामान्य कथन के रूप में नहीं। उत्तर सामग्री के प्रकार और कार्यप्रवाह पर लगभग पूरी तरह निर्भर करता है।
जब स्रोत सामग्री समय-संवेदनशील होती है तो ग्रोक को बढ़त मिलती है। यदि स्रोत पाठ में कोई ऐसा वाक्यांश आता है जो पिछले कुछ महीनों में सामान्य उपयोग में आया हो (एक राजनीतिक नारा, एक सांस्कृतिक मीम, एक तेजी से बढ़ते उद्योग में हाल ही में गढ़ा गया तकनीकी शब्द), तो ग्रोक की वास्तविक समय की वेब पहुंच इसे लक्ष्य भाषा में सटीक रूप से प्रस्तुत करने का बेहतर अवसर देती है। लामा के प्रशिक्षण डेटा की एक कटऑफ है; ग्रोक में ऐसा नहीं है।
लामा को तब फायदा होता है जब प्राथमिकता नियंत्रण, लागत या भाषा की व्यापकता हो। उन टीमों के लिए जो घर पर ही बड़ी संख्या में दस्तावेज़ों को संसाधित करती हैं, निजी बुनियादी ढांचे पर फाइन-ट्यून किए गए डोमेन मॉडल चलाती हैं, या ग्रोक की लगभग 40 भाषाओं की कवरेज से बाहर की भाषाओं में काम करती हैं, लामा अधिक व्यावहारिक उपकरण है। इसका 200 से अधिक भाषाओं का समर्थन और मल्टीमॉडल क्षमता इसे संरचित एंटरप्राइज़ वर्कफ़्लो के लिए अधिक बहुमुखी बनाती है।
प्रमुख भाषा युग्मों में मानक सामग्री पर पेशेवर अनुवाद गुणवत्ता के लिए, दोनों इतने करीब हैं कि अन्य कारक (एकीकरण, लागत, बुनियादी ढाँचा) गुणवत्ता अंतर से अधिक मायने रखते हैं।
दस्तावेज़ अनुवाद के लिए कौन सा बेहतर है?
लामा, अधिकांश मामलों में।
लामा 4 की मल्टीमॉडल क्षमता जटिल दस्तावेज़ों के लिए निर्णायक कारक है। एम्बेडेड चार्ट वाले पीडीएफ, स्कैन किए गए अनुबंध, छवियों से भरपूर प्रस्तुतियाँ, और मिश्रित-मीडिया फ़ाइलें—इन सभी के लिए एक ऐसे मॉडल की आवश्यकता होती है जो दृश्य और पाठ्य जानकारी को एक साथ संसाधित कर सके। ग्रोक की बहु-मोडल क्षमता वर्तमान संस्करण में अधिक सीमित है, और इसे उन दस्तावेज़ प्रसंस्करण वर्कफ़्लो के लिए डिज़ाइन नहीं किया गया है जिनकी एंटरप्राइज़ अनुवाद को आवश्यकता होती है।
प्रारूप प्रबंधन से परे, संवेदनशील सामग्री वाले दस्तावेज़ों के लिए स्व-होस्टिंग विकल्प महत्वपूर्ण है। एक कानूनी टीम जो गोपनीय विलय दस्तावेजों का अनुवाद कर रही है, उस टेक्स्ट को किसी बाहरी एपीआई को नहीं भेज सकती। एक स्वास्थ्य सेवा प्रदाता जो रोगी रिकॉर्ड संभालता है, उसे ऐसे अनुवाद की आवश्यकता है जो ऑन-प्रिमाइसेस पर ही रहे। लामा 4 स्थानीय रूप से चल रहा इन दोनों आवश्यकताओं को पूरा करता है। Grok, जो विशेष रूप से xAI के क्लाउड इन्फ्रास्ट्रक्चर के माध्यम से संचालित होता है, ऐसा नहीं करता है।
लंबे दस्तावेज़ों के लिए जहाँ पूरे पाठ में संगति मायने रखती है, जैसा कि MachineTranslation.com के आंतरिक विश्लेषण से पता चलता है, टुकड़ों में संसाधित किए गए दस्तावेज़ों में शब्दावली असंगति की दर उन दस्तावेज़ों की तुलना में 28% अधिक होती है जिन्हें समग्र रूप से संसाधित किया जाता है। ग्रोक और लामा दोनों LLM के रूप में पूर्ण-दस्तावेज़ संदर्भ को यथोचित रूप से अच्छी तरह से संभालते हैं, लेकिन बहुत लंबे दस्तावेज़ों (कानूनी समझौते, वार्षिक रिपोर्ट, तकनीकी मैनुअल) के लिए MachineTranslation.com के 24-मॉडल सर्वसम्मति से चलने पर वह अंतर पकड़ में आता है जो कोई भी एक मॉडल 40,000-शब्दों के दस्तावेज़ में पेश करेगा।
क्या मैं अनुवाद के लिए लामा को स्थानीय रूप से चला सकता हूँ?
हाँ, और कुछ विशिष्ट उपयोग के मामलों के लिए यह विशेष रूप से सही तरीका है।
मेटा लामा मॉडल के वज़न को व्यावसायिक-उपयोग लाइसेंस के तहत सार्वजनिक रूप से जारी करता है। ऐसी टीमें जिनके पास बड़े एआई मॉडल चलाने के लिए बुनियादी ढाँचा है, वे लामा 4 मेवरिक या स्काउट डाउनलोड कर सकती हैं और इसे पूरी तरह से ऑन-प्रिमाइसेस पर संचालित कर सकती हैं। इसका मतलब है कि कोई भी डेटा किसी बाहरी सर्वर पर नहीं भेजा जाता है, प्रति-टोकन एपीआई की कोई लागत नहीं आती है, और मॉडल को मालिकाना शब्दावली, क्लाइंट-विशिष्ट शब्दावलियों, या डोमेन-विशिष्ट समानांतर डेटा पर फाइन-ट्यून किया जा सकता है।
व्यावहारिक आवश्यकताएँ महत्वपूर्ण हैं: लामा 4 मेवरिक एक बड़ा मॉडल है जिसे पर्याप्त कंप्यूट संसाधनों की आवश्यकता होती है। जिन टीमों के पास मौजूदा GPU इंफ्रास्ट्रक्चर नहीं है, उनके लिए सेल्फ-होस्टिंग के आर्थिक पहलू अक्सर इसके बजाय क्लाउड API का उपयोग करने को प्राथमिकता देते हैं। लेकिन उन संगठनों के लिए जो पहले से ही अपने हार्डवेयर पर AI वर्कलोड चलाते हैं (एंटरप्राइज़ टेक्नोलॉजी, हेल्थकेयर सिस्टम, कानूनी और वित्तीय संस्थान), सेल्फ-होस्टेड लामा वह अनुवाद इन्फ्रास्ट्रक्चर है जो एक साथ अनुपालन, लागत और गुणवत्ता आवश्यकताओं को पूरा करता है।
उन टीमों के लिए जिन्हें 200 से अधिक भाषाओं में बहुभाषी आउटपुट की आवश्यकता है, जिसमें कम सामान्य भाषा जोड़े भी शामिल हैं जिन्हें कोई भी वाणिज्यिक API मज़बूती से कवर नहीं करता है, लामा का खुला प्रशिक्षण डेटा इसे किसी भी बंद मॉडल की तुलना में अधिक अनुकूलनीय बनाता है।
MachineTranslation.com ग्रोक और लामा दोनों का उपयोग कैसे करता है
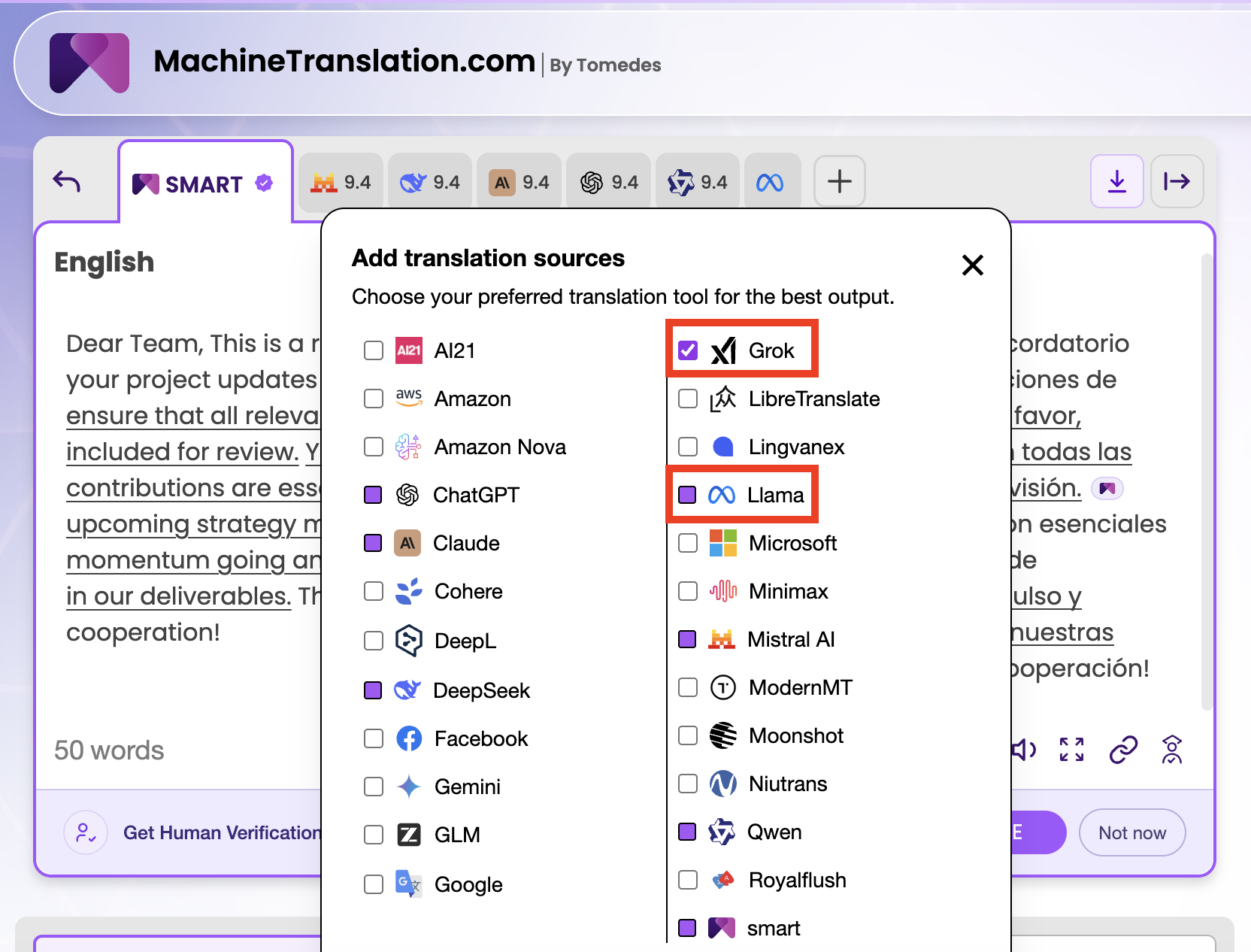
MachineTranslation.com ग्रोक और लामा दोनों को SMART के हिस्से के रूप में चलाता है, जो प्लेटफ़ॉर्म का 24-मॉडल सर्वसम्मति प्रणाली है। जब आप किसी भी पाठ या दस्तावेज़ का अनुवाद करते हैं, तो दोनों मॉडल एक स्वतंत्र आउटपुट उत्पन्न करते हैं। SMART फिर सभी 24 आउटपुट की तुलना करता है और उस अनुवाद को सामने लाता है जिस पर अधिकांश मॉडल सहमत होते हैं, प्रत्येक व्यक्तिगत मॉडल के लिए गुणवत्ता स्कोर के साथ।
इसका व्यावहारिक परिणाम यह है: आप देखते हैं कि ग्रोक ने क्या बनाया, लामा ने क्या बनाया, और 24 मॉडलों की आम सहमति किस पर सहमत है। यदि ग्रोक और लामा उसी अंग्रेजी से स्पेनिश टेक्स्ट पर क्रमशः 8.1 और 7.9 अंक प्राप्त करते हैं, और SMART सर्वसम्मति 9.4 अंक प्राप्त करती है, तो वह अंतर आपको कुछ सार्थक बताता है। सर्वसम्मत आउटपुट में वह सब शामिल है जो दोनों मॉडलों ने सही पाया, जबकि उन त्रुटियों को फ़िल्टर कर दिया गया है जो प्रत्येक ने स्वतंत्र रूप से पेश की थीं।
MachineTranslation.com पर आंतरिक परीक्षण में, SMART सर्वसम्मत दृष्टिकोण किसी एक मॉडल पर निर्भर रहने की तुलना में महत्वपूर्ण अनुवाद त्रुटि जोखिम को 90% तक कम करता है। इस लेख में विशिष्ट तुलना के लिए (ग्रोक 8.1 पर और लामा 7.9 पर अंग्रेजी से स्पेनिश में), उसी पाठ पर स्मार्ट सहमति ने 9.4 अंक प्राप्त किए, जिसमें ग्रोक और लामा 74% वाक्यों पर सहमत थे और सहमति आउटपुट ने शेष 26% में असहमति को सुलझाया।
न तो ग्रोक और न ही लामा पर आँख बंद करके भरोसा किया जाता है। 24-मॉडल समझौता वह संकेत है जो मायने रखता है।
आप Grok और Llama के आउटपुट की तुलना सीधे MachineTranslation.com पर कर सकते हैं, मुफ़्त, किसी साइन-अप की आवश्यकता नहीं है। दोनों चलाओ। देखें वे कहाँ सहमत हैं। देखें वे कहाँ अलग होते हैं। विचलन ही वह जगह थी जहाँ अनुवाद वास्तव में कठिन था।
अक्सर पूछे जाने वाले प्रश्न
1. क्या लामा अनुवाद के लिए ग्रोक से बेहतर है?
सार्वभौमिक रूप से नहीं। ग्रोक हाल की घटनाओं, ट्रेंडिंग भाषा और वर्तमान सांस्कृतिक संदर्भों से संबंधित समय-संवेदनशील सामग्री पर लामा से बेहतर प्रदर्शन करता है, क्योंकि इसकी वास्तविक समय की वेब पहुँच इसे ऐसा संदर्भ प्रदान करती है जिसकी लामा का स्थिर प्रशिक्षण डेटा बराबरी नहीं कर सकता। लामा उच्च-मात्रा वाले दस्तावेज़ वर्कफ़्लो, अनुपालन-संवेदनशील सामग्री जिसे परिसर में ही रहना चाहिए, और ग्रोक की लगभग 40-भाषा कवरेज से बाहर के भाषा युग्मों के लिए ग्रोक से बेहतर प्रदर्शन करता है। प्रमुख भाषा युग्मों में मानक सामग्री पर, उनके बीच गुणवत्ता का अंतर कम है।
2. अनुवाद के लिए ग्रॉक को अन्य एआई मॉडलों से क्या अलग बनाता है?
ग्रॉक का प्राथमिक अंतर वास्तविक समय डेटा तक पहुंच है। जबकि अधिकांश एआई मॉडल (लामा सहित) ज्ञान की एक निश्चित कटऑफ वाले एक निश्चित डेटासेट पर प्रशिक्षित होते हैं, ग्रोक अनुमान के दौरान लाइव वेब सामग्री और एक्स प्लेटफॉर्म डेटा से जानकारी खींच सकता है। हाल ही में गढ़े गए शब्दावली, ट्रेंडिंग सांस्कृतिक संदर्भों, या वर्तमान घटनाओं के बारे में सामग्री से जुड़े अनुवाद के लिए, यह ग्रोक को तथ्यात्मक सटीकता का ऐसा लाभ देता है जिसे स्थिर मॉडल दोहरा नहीं सकते।
3. क्या अनुवाद के लिए लामा 4 ग्रोक से बेहतर है?
लामा 4 मेवरिक और लामा 4 स्काउट ग्रोक की लगभग 40 भाषाओं की तुलना में 200 से अधिक भाषाओं का समर्थन करते हैं, और लामा 4 की मल्टीमॉडल क्षमता छवि-एम्बेडेड दस्तावेज़ों और स्कैन किए गए पीडीएफ को संभालती है जिन्हें ग्रोक उतनी प्रभावी ढंग से संसाधित नहीं कर सकता है। इंटेंटो द्वारा मूल्यांकित प्रमुख भाषा युग्मों पर अनुवाद की मूल गुणवत्ता के लिए, कोई भी मॉडल शीर्ष-14 समाधानों में शामिल नहीं था — दोनों सक्षम हैं लेकिन वर्ग-अग्रणी नहीं हैं। लामा 4 के व्यावहारिक फायदे इसकी व्यापकता, इसकी ओपन-सोर्स लचीलापन और इसका सेल्फ-होस्टिंग विकल्प हैं।
4. क्या लामा का उपयोग अनुवाद के लिए किया जा सकता है?
हाँ। लामा 4 मेवरिक और लामा 4 स्काउट, वर्तमान पीढ़ी, 200 से अधिक भाषाओं का समर्थन करते हैं और प्रमुख भाषा युग्मों पर अन्य अग्रणी एलएलएम के बराबर अनुवाद आउटपुट उत्पन्न करते हैं। लामा का उपयोग एपीआई के माध्यम से या निजी बुनियादी ढांचे पर स्व-होस्ट करके किया जा सकता है, जो इसे डेटा गोपनीयता या अनुपालन आवश्यकताओं वाले संगठनों के लिए विशेष रूप से प्रासंगिक बनाता है। इसे विशेष सामग्री पर प्रदर्शन बेहतर बनाने के लिए डोमेन-विशिष्ट डेटा पर भी फाइन-ट्यून किया जा सकता है।
5. बहुभाषी सामग्री के लिए कौन सा बेहतर है: ग्रॉक या लामा?
लामा, भाषा की व्यापकता पर एक महत्वपूर्ण अंतर से। लामा 4, 200 से अधिक भाषाओं का समर्थन करता है; ग्रोक लगभग 40 का समर्थन करता है। उन टीमों के लिए जो भाषाओं की एक विस्तृत श्रृंखला पर काम कर रही हैं (विशेषकर अफ्रीकी, दक्षिण एशियाई, या स्वदेशी भाषाओं में), लामा का प्रशिक्षण डेटा कवरेज काफी व्यापक है। प्रमुख यूरोपीय और पूर्वी एशियाई भाषा युग्मों के लिए, दोनों मॉडल तुलनीय प्रदर्शन करते हैं।
6. MachineTranslation.com Grok और Llama का एक साथ उपयोग कैसे करता है?
Grok और Llama दोनों MachineTranslation.com के SMART 24-मॉडल सहमति प्रणाली के हिस्से के रूप में एक साथ चलते हैं। प्रत्येक अनुवाद सभी 24 मॉडल से स्वतंत्र रूप से गुजरता है। SMART उस आउटपुट की पहचान करता है जिस पर बहुमत सहमत होता है और उसे परिणाम के रूप में प्रस्तुत करता है, प्रत्येक मॉडल के लिए गुणवत्ता स्कोर के साथ। उपयोगकर्ता ग्रोक का व्यक्तिगत आउटपुट, लामा का व्यक्तिगत आउटपुट, और आम सहमति वाला अनुवाद देख सकते हैं जो उन सभी 24 मॉडलों की सहमति को संश्लेषित करता है।