June 2, 2026
Grok vs Llama do tłumaczenia: Który model AI działa lepiej?
Dwie bardzo różne filozofie podchodzą do zadania tłumaczeniowego.
Grok jest zbudowany przez xAI, łączy się z danymi na żywo z sieci i X w czasie rzeczywistym i jest dostrojony do rodzaju języka, który szybko się zmienia — popularny slang, bieżące wydarzenia, odniesienia kulturowe, które zmieniają się z tygodnia na tydzień. Llama jest zbudowana przez Meta, udostępniona jako open-source światu i zaprojektowana do pobierania, modyfikowania i wdrażania na własnej infrastrukturze przy zerowym koszcie za token.
Oba znajdują się w 24-modelowym systemie konsensusu MachineTranslation.com. Oboje tłumaczą. I są one naprawdę przystosowane do różnych rodzajów pracy tłumaczeniowej.
Ten artykuł omawia, w czym każdy z nich jest naprawdę dobry, gdzie każdy z nich ma braki i co się dzieje, gdy testujesz je obok siebie na tej samej treści.
W tym artykule
- Czym jest Grok i jak radzi sobie z tłumaczeniem?
- Czym jest Llama i jak radzi sobie z tłumaczeniem?
- Grok kontra Llama: Porównanie jakości tłumaczenia
- Czy Llama jest lepsza od Groka do tłumaczenia?
- Co jest lepsze do tłumaczenia dokumentów?
- Czy mogę uruchomić Llamę lokalnie do tłumaczenia?
- Jak MachineTranslation.com wykorzystuje Groka i Llamę
- Często zadawane pytania
Czym jest Grok i jak radzi sobie z tłumaczeniem?

Grok jest rozwijany przez xAI, firmę AI założoną przez Elona Muska, i jest szkolony na kombinacji ogólnych danych internetowych oraz treści na żywo z X (dawniej Twitter). Obecne wersje to Grok 3 i Grok 4, wydane odpowiednio w lutym i lipcu 2025 roku. Co sprawia, że Grok wyróżnia się architektonicznie od większości modeli AI, to dostęp do danych w czasie rzeczywistym — może pobierać dane z bieżących treści internetowych i platformy X podczas wnioskowania, zamiast pracować na podstawie stałej migawki treningowej.
W przypadku tłumaczenia ma to znaczenie w specyficzny i wąski sposób. Grok jest szczególnie zdolny do tłumaczenia treści, które nawiązują do bieżących wydarzeń, popularnej terminologii, slangu internetowego oraz szybko zmieniających się odniesień kulturowych. Jeśli potrzebujesz przetłumaczyć post w mediach społecznościowych dotyczący niedawnej wiadomości, ogłoszenia o wprowadzeniu produktu na rynek lub wirusowej frazy, która pojawiła się trzy tygodnie temu, dostęp Groka do danych w czasie rzeczywistym zapewnia mu kontekst, którego model wytrenowany na danych z zeszłego roku po prostu nie ma.
To jest prawdziwa przewaga. Jest to również dość specyficzne.
Poza treściami wrażliwymi na czas, Grok zachowuje się jak większość czołowych LLM-ów w zakresie tłumaczenia: zdolny do pracy z głównymi parami językowymi, słabszy w przypadku języków o mniejszych zasobach i podlega temu samemu ograniczeniu strukturalnemu, które dzielą wszystkie systemy jednomodelowe — brak mechanizmu weryfikacji własnych wyników.
Grok jest dostępny za pośrednictwem X Premium+ (22 USD/miesiąc) lub SuperGrok (30 USD/miesiąc) do użytku konsumenckiego oraz za pośrednictwem API xAI w cenie około 0,20 USD za milion tokenów wejściowych. Nie może być hostowane samodzielnie. Dostrajanie na niestandardowych danych nie jest dostępne.
Czym jest Llama i jak radzi sobie z tłumaczeniem?
Llama to rodzina modeli AI o otwartej wadze firmy Meta. Obecna generacja (Llama 4 Maverick i Llama 4 Scout) została wydana w 2025 roku i stanowi znaczący skok w porównaniu do Llama 3 zarówno pod względem możliwości, jak i zasięgu językowego. Llama 4 obsługuje ponad 200 języków i jest multimodalna, co oznacza, że może przetwarzać obrazy wraz z tekstem. Ta multimodalna zdolność jest praktycznie istotna dla tłumaczenia: dokumenty z osadzonymi obrazami, zeskanowane pliki PDF i wykresy z etykietami tekstowymi mogą być obsługiwane przez Llama 4 w sposób, w jaki modele wyłącznie tekstowe nie potrafią.
Cechą definiującą Llama jest to, co można z nią zrobić. Ponieważ wagi modelu są publicznie dostępne na podstawie licencji do użytku komercyjnego, zespoły z odpowiednią infrastrukturą mogą pobrać Llamę, uruchomić ją na własnych serwerach, dostroić ją na danych specyficznych dla danej dziedziny i przetwarzać wrażliwe treści bez wysyłania czegokolwiek do zewnętrznego API. Dla przepływów pracy tłumaczeń prawnych, medycznych i finansowych, gdzie rezydencja danych jest wymogiem zgodności, nie jest to miły dodatek — to jedyna akceptowalna opcja.
Wynik tłumaczenia Llama dla standardowych treści jest mocny, ale nie na samym szczycie w tej dziedzinie. Raport Intento „Stan Automatyzacji Tłumaczeń 2025”, który oceniał Llama 4 Maverick i Llama 4 Scout w 11 parach językowych, stwierdził, że żaden z modeli nie znalazł się wśród 14 najlepszych rozwiązań w żadnej indywidualnej ocenie pary językowej. To jest uczciwy punkt odniesienia do stwierdzenia: Llama jest zdolna, ale modele takie jak GPT-4.1, Claude Opus 4 i Gemini 2.5 Pro przewyższają ją w parach ocenionych przez Intento. Gdzie Llama zdobywa swoje miejsce, to dzięki swojej elastyczności open-source, swojej szerokości językowej oraz swojej strukturze kosztów dla przepływów pracy o dużej objętości.
Grok kontra Llama: Jakość tłumaczenia w porównaniu
Kiedy MachineTranslation.com przetestowało zarówno Groka, jak i Llamę na tym samym 500-słowowym tekście marketingowym z angielskiego na hiszpański, Grok uzyskał wynik jakości 8,1 na 10, a Llama 7,9. W przypadku tego samego tekstu przetłumaczonego na japoński, Grok uzyskał 7,4 punktu, a Llama 7,6 — niewielkie odwrócenie, które odzwierciedla większą głębię wielojęzycznych danych treningowych Llama 4 dla języków azjatyckich. Współczynnik zgodności między dwoma modelami w przypadku tekstu hiszpańskiego wynosił 74%; w przypadku tekstu japońskiego spadł do 61%, co wskazuje, że konkretnie dla języka japońskiego, dwa modele interpretowały znaczące fragmenty tekstu źródłowego inaczej.
Te dane o zgodności zasługują na chwilę uwagi. Kiedy Grok i Llama zgadzają się co do tłumaczenia, możesz odczytać tę zbieżność jako sygnał pewności — dwa architektonicznie różne modele, szkolone na różnych danych, dochodzące do tego samego wyniku. Gdy się rozchodzą, tak jak to miało miejsce w 39% japońskich zdań w tym teście, to rozbieżność jest sygnałem: fragment albo zawiera prawdziwą dwuznaczność interpretacyjną, albo jeden z modeli dokonał wyboru, którego drugi by nie dokonał.
| Grok (Grok 4) | Llama (Llama 4 Maverick) | |
|---|---|---|
| Dostęp do danych w czasie rzeczywistym | Tak | Nie |
| Możliwość samodzielnego hostowania | Nie | Tak |
| Możliwość dostrajania | Nie | Tak |
| Języki | 40+ | 200+ |
| Wielomodalność (obrazy/dokumenty) | Ograniczona | Tak |
| Koszt API | ~$0.20/M tokenów wejściowych | Darmowe (samodzielnie hostowane) |
| Najlepszy typ treści | Popularne/społecznościowe/wiadomości | Duża objętość, specyficzne dla domeny |
| Wynik jakości MachineTranslation.com (EN-ES) | 8.1/10 | 7.9/10 |
| Wynik jakości MachineTranslation.com (EN-JA) | 7.4/10 | 7.6/10 |
Żaden model nie dominuje. Różnice są rzeczywiste, ale nie dramatyczne w przypadku standardowej zawartości. Przypadek użycia decyduje, który z nich jest faktycznie bardziej użyteczny — a dla większości profesjonalnych przepływów pracy tłumaczeniowej, żaden z nich nie jest właściwą odpowiedzią sam w sobie.
Czy Llama jest lepsza niż Grok do tłumaczenia?
Nie jako ogólne stwierdzenie. Odpowiedź zależy niemal wyłącznie od typu treści i przepływu pracy.
Grok ma przewagę, gdy materiał źródłowy jest wrażliwy na czas. Jeśli w tekście źródłowym pojawi się fraza, która weszła do powszechnego użycia w ciągu ostatnich kilku miesięcy (slogan polityczny, mem kulturowy, niedawno ukuty termin techniczny w szybko rozwijającej się branży), dostęp Groka do sieci w czasie rzeczywistym daje mu większą szansę na dokładne oddanie jej w języku docelowym. Dane treningowe Llama mają datę odcięcia; Grok nie ma.
Llama ma przewagę, gdy priorytetem jest kontrola, koszt lub szerokość językowa. Dla zespołów przetwarzających duże ilości dokumentów we własnym zakresie, uruchamiających dopracowane modele domenowe na prywatnej infrastrukturze lub pracujących w językach spoza około 40-językowego zasięgu Groka, Llama jest bardziej praktycznym narzędziem. Jego obsługa ponad 200 języków i możliwości multimodalne sprawiają, że jest bardziej wszechstronny w przypadku ustrukturyzowanych przepływów pracy w przedsiębiorstwie.
W przypadku profesjonalnej jakości tłumaczenia standardowych treści w głównych parach językowych, te dwa są na tyle zbliżone, że inne czynniki (integracja, koszt, infrastruktura) mają większe znaczenie niż różnica w jakości.
Co jest lepsze do tłumaczenia dokumentów?
Llama, w większości przypadków.
Możliwości multimodalne Llama 4 są decydującym czynnikiem w przypadku złożonych dokumentów. Pliki PDF z osadzonymi wykresami, zeskanowane umowy, prezentacje bogate w obrazy oraz pliki multimedialne – wszystkie wymagają modelu, który potrafi przetwarzać informacje wizualne i tekstowe jednocześnie. Wielomodalna zdolność Groka jest bardziej ograniczona w obecnej wersji i nie jest on zaprojektowany do rodzajów przepływów pracy związanych z przetwarzaniem dokumentów, których wymaga tłumaczenie korporacyjne.
Poza obsługą formatów, opcja samodzielnego hostingu ma znaczenie dla dokumentów zawierających wrażliwe treści. Zespół prawny tłumaczący poufne dokumenty fuzji nie może wysyłać tego tekstu do zewnętrznego interfejsu API. Podmiot leczniczy obsługujący dokumentację pacjenta potrzebuje tłumaczenia, które jest realizowane lokalnie. Llama 4 działająca lokalnie spełnia oba te wymagania. Grok, który działa wyłącznie za pośrednictwem infrastruktury chmurowej xAI, nie.
W przypadku długich dokumentów, gdzie spójność w całym tekście ma znaczenie, jak pokazuje wewnętrzna analiza MachineTranslation.com, dokumenty przetwarzane we fragmentach wykazują o 28% wyższy wskaźnik niespójności terminologicznej w porównaniu do tych przetwarzanych w całości. Zarówno Grok, jak i Llama dość dobrze radzą sobie z kontekstem całego dokumentu jako LLM-y, ale w przypadku bardzo długich dokumentów (umowy prawne, raporty roczne, instrukcje techniczne) przepuszczenie ich przez konsensus 24 modeli MachineTranslation.com wyłapuje błędy, które pojedynczy model wprowadziłby w dokumencie liczącym 40 000 słów.
Czy mogę uruchomić Llama lokalnie do tłumaczenia?
Tak, a w przypadku niektórych zastosowań jest to szczególnie właściwe podejście.
Meta udostępnia publicznie wagi modeli Llama na licencji do użytku komercyjnego. Zespoły posiadające infrastrukturę do uruchamiania dużych modeli AI mogą pobrać Llama 4 Maverick lub Scout i obsługiwać go w całości lokalnie. Oznacza to, że żadne dane nie są wysyłane na żaden zewnętrzny serwer, nie są ponoszone żadne koszty API za token, a model może być dostrajany na podstawie zastrzeżonej terminologii, glosariuszy specyficznych dla klienta lub danych równoległych specyficznych dla domeny.
Praktyczne wymagania są znaczące: Llama 4 Maverick jest dużym modelem, który wymaga znacznych zasobów obliczeniowych. Dla zespołów bez istniejącej infrastruktury GPU, ekonomika samodzielnego hostowania często przemawia za korzystaniem z API w chmurze zamiast tego. Jednak dla organizacji, które już uruchamiają obciążenia AI na własnym sprzęcie (technologia korporacyjna, systemy opieki zdrowotnej, instytucje prawne i finansowe), samodzielnie hostowana Llama jest infrastrukturą tłumaczeniową, która jednocześnie spełnia wymagania dotyczące zgodności, kosztów i jakości.
Dla zespołów, które potrzebują wielojęzycznych wyników w ponad 200 językach, w tym mniej popularnych par językowych, których żadne komercyjne API nie obejmuje niezawodnie, otwarte dane treningowe Llama sprawiają, że jest ona bardziej elastyczna niż jakikolwiek zamknięty model.
Jak MachineTranslation.com wykorzystuje zarówno Grok, jak i Llama
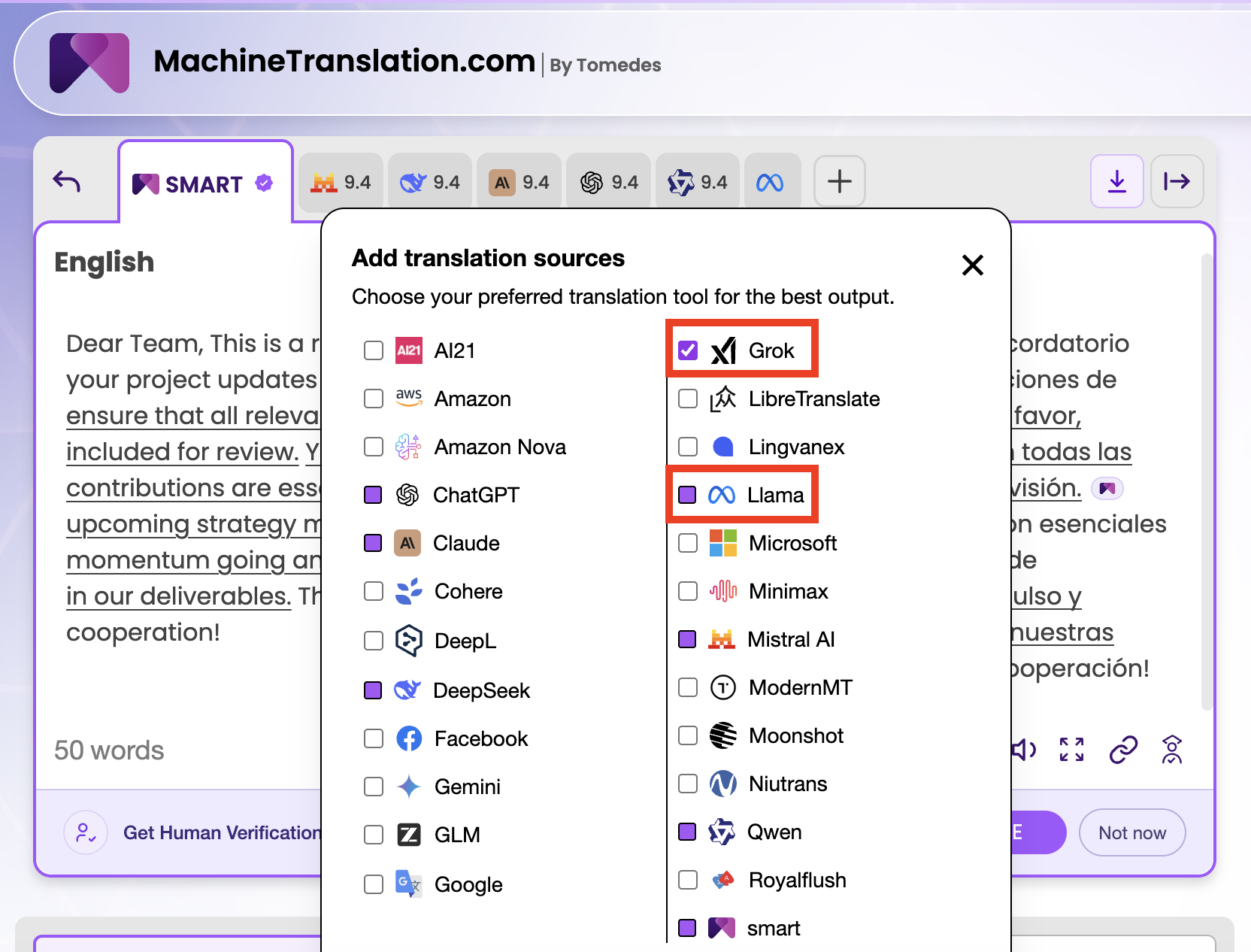
MachineTranslation.com uruchamia zarówno Grok, jak i Llama w ramach SMART, 24-modelowego systemu konsensusu platformy. Kiedy tłumaczysz dowolny tekst lub dokument, oba modele generują niezależny wynik. SMART następnie porównuje wszystkie 24 wyniki i przedstawia tłumaczenie, na które zgadza się większość modeli, wraz z wynikami jakości dla każdego pojedynczego modelu.
Praktyczny rezultat: widzisz, co wyprodukował Grok, co wyprodukowała Llama i na co zgadza się konsensus 24 modeli. Jeśli Grok i Llama uzyskują odpowiednio 8.1 i 7.9 na tym samym tekście z angielskiego na hiszpański, a konsensus SMART uzyskuje 9.4, ta różnica mówi ci coś znaczącego. Wynik konsensusu uwzględnia to, co oba modele zrobiły poprawnie, jednocześnie odfiltrowując błędy wprowadzone niezależnie przez każdy z nich.
W wewnętrznych testach na MachineTranslation.com, podejście konsensusowe SMART zmniejsza ryzyko krytycznych błędów tłumaczeniowych o 90% w porównaniu do polegania na pojedynczym modelu. Dla konkretnego porównania w tym artykule (Grok z wynikiem 8.1 i Llama z wynikiem 7.9 w tłumaczeniu z angielskiego na hiszpański), konsensus SMART dla tego samego tekstu uzyskał wynik 9.4, przy czym Grok i Llama zgodziły się co do 74% zdań, a wynik konsensusu rozwiązał rozbieżności w pozostałych 26%.
Ani Grok, ani Llama nie są ślepo ufane. Umowa na 24 modele jest sygnałem, który ma znaczenie.
Możesz porównać wyniki Groka i Lamy bezpośrednio na MachineTranslation.com, bezpłatnie, bez konieczności rejestracji. Uruchom oba. Zobacz, gdzie się zgadzają. Zobacz, gdzie się rozchodzą. Rozbieżność polegała na tym, że tłumaczenie było faktycznie trudne.
Często zadawane pytania
1. Czy Llama jest lepsza od Groka do tłumaczenia?
Nie uniwersalnie. Grok przewyższa Llamę w treściach wrażliwych na czas, obejmujących ostatnie wydarzenia, popularny język i bieżące odniesienia kulturowe, ponieważ jego dostęp do sieci w czasie rzeczywistym dostarcza mu kontekstu, któremu statyczne dane treningowe Llama nie mogą dorównać. Llama przewyższa Groka w przypadku przepływów pracy z dużą ilością dokumentów, treści wrażliwych pod kątem zgodności, które muszą pozostać lokalnie, oraz par językowych wykraczających poza około 40-językowy zakres Groka. W przypadku standardowych treści w głównych parach językowych, różnica w jakości między nimi jest niewielka.
2. Co odróżnia Groka od innych modeli AI do tłumaczenia?
Głównym wyróżnikiem Groka jest dostęp do danych w czasie rzeczywistym. Podczas gdy większość modeli AI (w tym Llama) jest trenowana na stałym zbiorze danych z odcięciem wiedzy, Grok może czerpać z treści internetowych na żywo i danych z platformy X podczas wnioskowania. W przypadku tłumaczeń obejmujących niedawno powstałą terminologię, popularne odniesienia kulturowe lub treści dotyczące bieżących wydarzeń, daje to Grokowi przewagę w zakresie dokładności faktograficznej, której modele statyczne nie są w stanie powielić.
3. Czy Llama 4 jest lepsza od Groka do tłumaczenia?
Llama 4 Maverick i Llama 4 Scout obsługują ponad 200 języków w porównaniu do około 40 Groka, a wielomodalna zdolność Llama 4 obsługuje dokumenty z osadzonymi obrazami i zeskanowane pliki PDF, których Grok nie jest w stanie przetwarzać tak skutecznie. Jeśli chodzi o surową jakość tłumaczenia dla głównych par językowych ocenionych przez Intento, żaden z modeli nie znalazł się w czołowej czternastce rozwiązań — oba są zdolne, ale nie przodują w swojej klasie. Praktyczne zalety Llama 4 to jej szeroki zakres, jej otwartoźródłowa elastyczność i możliwość samodzielnego hostowania.
4. Czy Llama może być używana do tłumaczenia?
Tak. Llama 4 Maverick i Llama 4 Scout, obecna generacja, obsługują ponad 200 języków i generują wyniki tłumaczeń porównywalne z innymi przełomowymi LLM-ami w głównych parach językowych. Llama może być używana za pośrednictwem API lub hostowana samodzielnie na prywatnej infrastrukturze, co czyni ją szczególnie istotną dla organizacji z wymogami dotyczącymi prywatności danych lub zgodności. Można go również dostroić na danych specyficznych dla domeny, aby poprawić wydajność na specjalistycznych treściach.
5. Co jest lepsze dla treści wielojęzycznych: Grok czy Llama?
Llama, ze znaczną przewagą pod względem szerokości językowej. Llama 4 obsługuje ponad 200 języków; Grok obsługuje około 40. Dla zespołów pracujących z szerokim zakresem par językowych (szczególnie w językach afrykańskich, południowoazjatyckich lub rdzennych), zasięg danych treningowych Llama jest znacznie szerszy. Dla głównych par językowych europejskich i wschodnioazjatyckich, oba modele działają porównywalnie.
6. W jaki sposób MachineTranslation.com używa Groka i Lamy razem?
Zarówno Grok, jak i Llama działają jednocześnie w ramach systemu konsensusu SMART 24-modelowego MachineTranslation.com. Każde tłumaczenie przechodzi przez wszystkie 24 modele niezależnie. SMART identyfikuje dane wyjściowe, na które zgadza się większość, i dostarcza je jako rezultat, wraz z wynikami jakości dla każdego modelu. Użytkownicy mogą zobaczyć indywidualny wynik Groka, indywidualny wynik Llamy oraz tłumaczenie konsensusowe, które syntetyzuje to, na co zgodziły się wszystkie 24 modele.