May 22, 2026
Claude vs DeepL สำหรับการแปล: อันไหนดีกว่ากันแน่?
นี่คือจุดเริ่มต้นที่ซื่อสัตย์: Claude และ DeepL ไม่ได้แข่งขันกันเพื่อผู้ใช้กลุ่มเดียวกันจริงๆ
DeepL ถูกสร้างขึ้นเพื่อการแปล มันได้ทำการปรับปรุงสิ่งหนึ่ง (การแปลงข้อความจากภาษาหนึ่งเป็นอีกภาษาหนึ่งด้วยความคล่องแคล่วเป็นธรรมชาติ) ตั้งแต่ปี 2017 Claude เป็นแบบจำลองการให้เหตุผลอเนกประสงค์ที่พัฒนาโดย Anthropic ซึ่งแปลได้ดีเป็นพิเศษ โดยเฉพาะอย่างยิ่งเมื่อเนื้อหามีความยาว ซับซ้อน หรือต้องมีการตีความตามบริบทอย่างลึกซึ้ง
คำถาม Claude vs DeepL มีความสำคัญสำหรับผู้ที่กำลังตัดสินใจว่าจะจัดการงานแปลอย่างมืออาชีพอย่างไร และต้องการคำตอบที่ชัดเจน ไม่ใช่การเปรียบเทียบทางการตลาด นั่นคือสิ่งที่บทความนี้มีเป้าหมายที่จะเป็น
ในบทความนี้
- แต่ละเครื่องมือถูกสร้างขึ้นมาเพื่อทำอะไร
- Claude และ DeepL เปรียบเทียบกันในเรื่องความแม่นยำอย่างไร
- DeepL มีข้อได้เปรียบที่แท้จริงตรงไหน
- Claude นำหน้าตรงไหน
- การครอบคลุมภาษาและการจัดการเอกสาร
- ราคา: สิ่งที่คุณจ่ายจริง ๆ
- คุณควรใช้แบบไหน
- จะเกิดอะไรขึ้นเมื่อคุณเรียกใช้ทั้งสองอย่างพร้อมกัน
- คำถามที่พบบ่อย
แต่ละเครื่องมือถูกสร้างขึ้นมาเพื่อทำอะไร
Claude: โมเดลการให้เหตุผลที่ใช้สำหรับการแปล

Claude พัฒนาโดย Anthropic และเป็นโมเดลภาษาขนาดใหญ่ที่ออกแบบมาสำหรับการให้เหตุผล การวิเคราะห์ และการสร้างสรรค์ในงานต่างๆ การแปลเป็นหนึ่งในงานเหล่านั้น และปรากฏว่า Claude ทำได้ดีทีเดียว โดยเฉพาะอย่างยิ่งสำหรับเนื้อหาที่บริบทโดยรอบเป็นตัวกำหนดความหมาย: เอกสารทางกฎหมาย, ข้อความวรรณกรรม, ข้อมูลจำเพาะทางเทคนิค และสิ่งใดก็ตามที่ไม่สามารถเข้าใจประโยคเดียวได้โดยลำพัง
ตระกูล Claude 4 ปัจจุบัน (Claude Opus 4 และ Claude Sonnet 4) มีหน้าต่างบริบท 200,000 โทเค็น ซึ่งเปลี่ยนแปลงสิ่งที่เป็นไปได้ในการแปล เครื่องมือแปลเอกสารที่ทำงานทีละส่วนจะพลาดการพึ่งพาอาศัยกันระหว่างประโยค ความไม่สอดคล้องกันในชื่อตัวละครหรือศัพท์เฉพาะ และการเปลี่ยนโทนเสียงในแต่ละบท โคลดไม่มีปัญหานั้น เมื่อคุณป้อนสัญญาฉบับเต็มให้ มันจะมองเห็นสัญญาฉบับทั้งหมด
จากข้อมูลของ Intento's State of Translation Automation 2025 Claude Opus 4 และ Claude Sonnet 3.7 จัดอยู่ในกลุ่มโซลูชันตัวแทนเดี่ยวที่มีประสิทธิภาพดีที่สุดในคู่ภาษาอังกฤษเป็นเยอรมัน อังกฤษเป็นดัตช์ อังกฤษเป็นอิตาลี อังกฤษเป็นญี่ปุ่น และอังกฤษเป็นเกาหลี ทั้งในการประเมิน LQA แบบอัตโนมัติและแบบมนุษย์
DeepL: เครื่องมือที่สร้างขึ้นโดยเฉพาะสำหรับการแปล

DeepL ทำสิ่งหนึ่งและได้ปรับปรุงอย่างไม่หยุดหย่อนเพื่อสิ่งนั้น เครื่องมือแปลภาษาด้วยระบบประสาทนี้ได้รับการฝึกฝนโดยเฉพาะกับข้อมูลที่เกี่ยวข้องกับการแปล และความเชี่ยวชาญพิเศษนั้นแสดงให้เห็นในผลลัพธ์: การแปลของ DeepL ฟังดูเป็นธรรมชาติกว่าคู่แข่งส่วนใหญ่สำหรับภาษาในยุโรป สำนวนสละสลวย ไวยากรณ์ถูกต้อง และระดับภาษาโดยทั่วไปสอดคล้องกับต้นฉบับ
ในการวัดผลภายในของ MachineTranslation.com ที่มีคำศัพท์หลากหลาย 5,000 คำ ทั้งเนื้อหาทางเทคนิคและการตลาด DeepL ทำคะแนนความแม่นยำได้ 94.2% — สูงที่สุดในบรรดาเครื่องมือแปลภาษาแบบสแตนด์อโลนที่ทดสอบ และถูกอธิบายไว้ในการวัดผลว่าเป็น ราชาแห่งการไหลลื่น สำหรับคู่ภาษาในยุโรปโดยเฉพาะ จะฟังดูเหมือนมนุษย์มากที่สุด
DeepL ยังเปิดตัว DeepL next-gen ในปี 2024 ซึ่งเป็น LLM ที่สร้างขึ้นเพื่อการแปลโดยเฉพาะ ซึ่งปรับปรุงจากรุ่นคลาสสิกสำหรับข้อความที่ยาวขึ้น และซึ่ง การประเมินของ Intento ปี 2025 จัดอยู่ในกลุ่มโซลูชันแบบเรียลไทม์ที่มีประสิทธิภาพสูงสุดในหลายคู่ภาษา รวมถึง อังกฤษเป็นสเปน ฝรั่งเศส อิตาลี ดัตช์ เกาหลี และโปรตุเกส
ข้อแลกเปลี่ยนสำหรับความเชี่ยวชาญพิเศษนั้น: DeepL รองรับ 33 ภาษา ซึ่งถือว่าแคบ และมันเป็นระบบแบบจำลองเดียว — ผลลัพธ์ที่คุณได้รับคือการตีความของ DeepL โดยไม่มีสัญญาณตรวจสอบข้าม และไม่มีทางรู้ว่าเมื่อใดที่มันได้ทำการเลือกที่คุณอาจไม่เห็นด้วย
Claude และ DeepL เปรียบเทียบกันในเรื่องความแม่นยำอย่างไร
คำตอบขึ้นอยู่กับสิ่งที่คุณกำลังแปลและเป็นภาษาใด
คู่ภาษาในยุโรป
สำหรับคู่ภาษาหลักในยุโรป (เยอรมัน, ฝรั่งเศส, สเปน, อิตาลี, ดัตช์, โปรตุเกส) DeepL รุ่นใหม่มีความสามารถในการแข่งขันอย่างแท้จริง การประเมินคุณภาพการแปลภาษา (LQA) โดยมนุษย์ของ Intento ในปี 2025 จัดให้อยู่ในกลุ่มชั้นนำสำหรับคู่ภาษาหกคู่จากทั้งหมดสิบเอ็ดคู่ที่ได้รับการประเมิน ผลลัพธ์ฟังดูเป็นธรรมชาติ, เป็นสำนวน, และเป็นทางการอย่างเหมาะสมโดยไม่ต้องมีการกระตุ้นวิศวกรรมใดๆ จากผู้ใช้
Claude Opus 4 และ Sonnet 3.7 ยังปรากฏอยู่ในระดับบนสุดสำหรับคู่เหล่านี้หลายคู่ โดยเฉพาะอย่างยิ่งภาษาอังกฤษเป็นภาษาเยอรมันและภาษาอังกฤษเป็นภาษาดัตช์ ซึ่งการใช้เหตุผลตามบริบทของ Claude ช่วยให้จัดการกับความซับซ้อนทางสัณฐานวิทยาและการตกลงของกรณีในข้อความที่ยาวขึ้นได้
ความแตกต่างในทางปฏิบัติในระดับนี้: สำหรับเนื้อหามาตรฐานสั้นๆ (คำอธิบายผลิตภัณฑ์, ช่องแบบฟอร์ม, สำเนา UI) ข้อได้เปรียบด้านความเร็วของ DeepL มีความสำคัญและคุณภาพของมันสม่ำเสมอ สำหรับเนื้อหาที่ยาวและซับซ้อนกว่า หน้าต่างบริบทและความลึกของการใช้เหตุผลของ Claude จะสร้างผลลัพธ์ที่แข็งแกร่งกว่าอย่างเห็นได้ชัด
การจัดการเอกสารและบริบทที่ยาว
นี่คือจุดที่การเปรียบเทียบเริ่มไม่ใกล้เคียงกัน
จากการติดตามในการวิเคราะห์ภายในของ MachineTranslation.com ข้อผิดพลาดที่ยังคงมีอยู่ในระบบการแปลด้วย AI สมัยใหม่เกือบทั้งหมดเป็นเรื่องของความหมาย: โทนเสียงผิด, ระดับภาษาผิด, คำศัพท์ผิด, การพลาดการพึ่งพาอาศัยกันระหว่างประโยค นี่ไม่ใช่ข้อผิดพลาดที่การแปลทีละส่วนจะจับได้ ข้อผิดพลาดเหล่านี้จะปรากฏขึ้นเมื่อคุณอ่านเอกสารฉบับเต็มและสังเกตว่าตำแหน่งของตัวละครเปลี่ยนไปหลังจากผ่านไปสามหน้า หรือคำศัพท์ที่กำหนดไว้ถูกแปลความหมายแตกต่างกันในสองอนุประโยค
หน้าต่างบริบท 200,000 โทเค็นของ Claude หมายความว่าสามารถเก็บข้อตกลงทางกฎหมายทั้งหมด คู่มือทางเทคนิค หรือบทวรรณกรรมไว้ในหน่วยความจำการทำงานและสร้างการแปลที่สอดคล้องกันภายในเอกสารทั้งหมดได้ คุณสมบัติการแปลเอกสารของ DeepL ประมวลผลเนื้อหาเป็นส่วนๆ ซึ่งโดยทั่วไปแล้วใช้ได้ดีสำหรับเอกสารที่มีโครงสร้าง แต่สามารถนำเสนอการเปลี่ยนแปลงที่ Claude หลีกเลี่ยงโดยการออกแบบ
เนื้อหาทางเทคนิคและเฉพาะด้าน
เครื่องมือทั้งสองจัดการกับเนื้อหาทางเทคนิคทั่วไปได้ค่อนข้างดี สำหรับโดเมนเฉพาะทาง (กฎหมาย, การแพทย์, การเงิน) ผลลัพธ์ขึ้นอยู่กับว่าเนื้อหาต้นฉบับตรงกับข้อมูลการฝึกอบรมของแต่ละเครื่องมือได้ดีเพียงใด
DeepL อนุญาตให้ใส่พจนานุกรมศัพท์เฉพาะในแผน API แบบชำระเงิน ซึ่งช่วยรักษาความสอดคล้องกันของคำศัพท์ Claude ที่ใช้ผ่าน API หรือในพรอมต์ที่มีโครงสร้างดี สามารถดูดซับพจนานุกรมฉบับเต็มเป็นบริบทและนำไปใช้ได้ตลอด แนวทางใดก็ไม่ได้ดีกว่าอย่างชัดเจน ทั้งคู่ต้องมีการตั้งค่าจากผู้ใช้
DeepL มีข้อได้เปรียบที่แท้จริง
ความเป็นธรรมชาติและความคล่องแคล่วสำหรับคู่ภาษาในยุโรป เมื่อการแปลต้องฟังดูเหมือนเขียนโดยเจ้าของภาษา (สำเนาการตลาด การสื่อสารแบรนด์ เนื้อหาที่ผู้บริโภคเข้าถึง) ผลลัพธ์ของ DeepL นั้นเป็นธรรมชาติที่สุดเสมอ Claude แปลได้อย่างถูกต้อง แต่ผลลัพธ์ของ DeepL โดยเฉพาะอย่างยิ่งสำหรับคู่ภาษาในสหภาพยุโรป อ่านได้สำนวนมากกว่า
ความเร็ว DeepL เป็นเครื่องมือ NMT ที่ปรับให้เหมาะสมสำหรับปริมาณงาน สำหรับเวิร์กโฟลว์ที่มีปริมาณมากและต้องใช้เวลาอย่างรวดเร็ว จะเร็วกว่า Claude อย่างมาก ซึ่งทำงานด้วยความเร็ว LLM
การรวมเวิร์กโฟลว์ DeepL มีระบบนิเวศที่เติบโตเต็มที่: ปลั๊กอินเครื่องมือ CAT, API ที่มีเอกสารประกอบอย่างดี, การจัดการพจนานุกรมศัพท์, และการตั้งค่าโทนเสียง (ทางการ/ไม่เป็นทางการ) มันเข้ากันได้กับขั้นตอนการทำงานของนักแปลมืออาชีพในแบบที่ Claude ซึ่งเป็นโมเดลอเนกประสงค์ทำไม่ได้โดยธรรมชาติ
ผลลัพธ์ที่สอดคล้องกันสำหรับเนื้อหามาตรฐาน สำหรับเนื้อหาที่งานแปลถูกกำหนดไว้อย่างดีและผลลัพธ์เพียงแค่ต้องถูกต้องอย่างน่าเชื่อถือ DeepL จะขจัดตัวแปรออกไป คุณรู้คร่าวๆ ว่าคุณจะได้อะไร
ที่ Claude นำหน้า
เอกสารที่ยาวและซับซ้อนตามบริบท สัญญา 40 หน้า บทวรรณกรรม หรือข้อกำหนดทางเทคนิคหลายส่วน — Claude ประมวลผลทั้งหมดในครั้งเดียวและรักษาความสอดคล้องกันตลอดทั้งฉบับในแบบที่การแปลทีละส่วนไม่สามารถทำซ้ำได้
ความแตกต่างและความเหมาะสม Claude 3.5 Sonnet ทำคะแนนได้ 93.8 จาก 100 ในเกณฑ์มาตรฐานคุณภาพภายในของ MachineTranslation.com โดยทำได้ดีเป็นพิเศษกับเนื้อหาที่น้ำเสียงมีความสำคัญ: การแปลเสียงของแบรนด์ การสื่อสารกับผู้มีส่วนได้ส่วนเสีย และการติดต่อทางวิชาชีพที่ ถูกต้องทางเทคนิค ไม่เพียงพอ
ความกว้างของหลายภาษา Claude รองรับภาษาได้หลากหลายกว่า 33 ภาษาของ DeepL สำหรับทีมที่ทำงานนอกเหนือจากขอบเขตหลักของ DeepL ในยุโรป Claude จะเติมเต็มช่องว่างได้อย่างแท้จริง
การให้เหตุผลเกี่ยวกับข้อความ หากคุณไม่ได้แค่แปล แต่ยังขอให้แบบจำลองปรับเนื้อหาให้เข้ากับผู้ชมที่แตกต่างกัน ปรับระดับภาษา หรือระบุวลีที่ไม่เหมาะสมทางวัฒนธรรม Claude จะทำสิ่งนี้เป็นส่วนหนึ่งของงานเดียวกัน DeepL แปลภาษาให้ คลอดยังคิดด้วย
การครอบคลุมภาษาและการจัดการเอกสาร
| Claude (Opus 4 / Sonnet 4) | DeepL (Classic + next-gen) | |
|---|---|---|
| ภาษาที่รองรับ | หลากหลายภาษา (100+) | 33 ภาษา |
| หน้าต่างบริบท | สูงสุด 200,000 โทเค็น | ทีละส่วน |
| รูปแบบเอกสาร | ผ่าน API หรือการอัปโหลดไฟล์ | PDF, DOCX, PPTX, XLSX |
| การรักษารูปแบบ | มีจำกัด | แข็งแกร่ง (รักษารูปแบบดั้งเดิม) |
| ขนาดไฟล์ | ขึ้นอยู่กับจำนวนโทเค็น | สูงสุด 30MB ในแผนที่สูงกว่า |
| การสนับสนุนพจนานุกรม | ผ่านพรอมต์ / API | คุณสมบัติพจนานุกรมดั้งเดิม |
| การรวมเครื่องมือ CAT | ไม่มี | ใช่ (รองรับเครื่องมือ CAT หลัก) |
หมายเหตุเชิงปฏิบัติเกี่ยวกับเอกสาร: DeepL คงรูปแบบต้นฉบับเมื่อแปลไฟล์ DOCX และ PDF ซึ่งมีประโยชน์อย่างแท้จริงสำหรับเอกสารทางธุรกิจที่การจัดรูปแบบใหม่หลังการแปลนั้นใช้เวลานาน การแปลเอกสารของ Claude ผ่าน API ไม่ได้คงรูปแบบเดิมไว้ ซึ่งเป็นสิ่งสำคัญสำหรับทุกอย่างที่จะเผยแพร่โดยตรงโดยไม่ต้องดำเนินการหลังการประมวลผล
ราคา: สิ่งที่คุณจ่ายจริง ๆ
Claude (ผ่าน Anthropic API):
- Claude Sonnet 4: $3.00 ต่อหนึ่งล้านโทเค็นอินพุต / $15.00 ต่อหนึ่งล้านโทเค็นเอาต์พุต
- Claude Opus 4: $15.00 ต่อหนึ่งล้านโทเค็นอินพุต / $75.00 ต่อหนึ่งล้านโทเค็นเอาต์พุต
- ผ่าน Claude.ai: มีให้บริการแบบฟรีพร้อมขีดจำกัดการใช้งาน แผน Pro ราคา $20/เดือน
DeepL:
- ฟรี: จำกัดจำนวนอักขระ แปลเอกสารที่ไม่สามารถแก้ไขได้ 3 ฉบับต่อเดือน
- Starter: ~ $10.49/ผู้ใช้/เดือน
- Advanced: ~ $34.49/ผู้ใช้/เดือน
- Ultimate: ~ $68.99/ผู้ใช้/เดือน
- API Pro: $25 ต่ออักขระหนึ่งล้านตัว
สำหรับผู้ใช้มืออาชีพส่วนใหญ่ แผนการสมัครสมาชิกของ DeepL นั้นคาดการณ์ได้มากกว่า สำหรับเวิร์กโฟลว์ที่เน้น API การเปรียบเทียบขึ้นอยู่กับปริมาณ: ราคาต่อโทเค็นของ Claude ปรับขนาดแตกต่างจากโมเดลต่ออักขระของ DeepL และเมื่อปริมาณมาก ความแตกต่างสามารถเป็นได้ทั้งสองทางขึ้นอยู่กับความยาวเฉลี่ยของเอกสารและทิศทางการแปล
คุณควรใช้ตัวเลือกใด
การเลือกขึ้นอยู่กับสิ่งที่คุณกำลังแปล ไม่ใช่เครื่องมือใดดีกว่าอย่างเป็นกลาง
| กรณีการใช้งาน | ตัวเลือกที่ดีกว่า |
|---|---|
| สำเนาการตลาด เนื้อหา EU ที่ผู้บริโภคเข้าถึงได้ | DeepL |
| เอกสารทางกฎหมายหรือทางเทคนิคขนาดยาวที่ต้องการความสอดคล้อง | Claude |
| สตริง UI คำอธิบายผลิตภัณฑ์ในปริมาณมาก | DeepL |
| การแปลด้วยน้ำเสียงวรรณกรรมหรือแบรนด์ | Claude |
| ภาษาภายนอก 33 ภาษาที่ DeepL รองรับ | Claude |
| เวิร์กโฟลว์ด้วยเครื่องมือ CAT หรือการรวม TMS | DeepL |
| เนื้อหาที่ต้องการการรักษาการจัดรูปแบบ | DeepL |
| การใช้เหตุผลหรือการปรับตัวแบบหลายภาษาที่ซับซ้อน | Claude |
| การแปลมาตรฐานปริมาณมากอย่างรวดเร็ว | DeepL |
| เนื้อหาที่ละเอียดอ่อนซึ่งความแตกต่างของบริบทมีความสำคัญที่สุด | Claude |
ไม่มีคำตอบใดเป็นแบบถาวร ทีมที่แปลแคตตาล็อกผลิตภัณฑ์เป็นภาษาฝรั่งเศส และทีมที่แปลความเห็นทางกฎหมายเป็นภาษาญี่ปุ่นต้องการค่าเริ่มต้นที่แตกต่างกัน
จะเกิดอะไรขึ้นเมื่อคุณเรียกใช้ทั้งสองอย่างพร้อมกัน
มีข้อโต้แย้งว่าคำถามเกี่ยวกับ Claude เทียบกับ DeepL ไม่ใช่กรอบการทำงานที่เป็นประโยชน์มากที่สุด ทั้งคู่เป็นเครื่องมือที่แข็งแกร่งที่มีจุดแข็งแตกต่างกัน คำถามที่มีประโยชน์กว่าคือ: คุณจะได้รับสิ่งที่ดีที่สุดจากทั้งสองอย่างได้อย่างไร
เมื่อคุณเรียกใช้ Claude และ DeepL บนข้อความต้นฉบับเดียวกันและเปรียบเทียบผลลัพธ์ ความแตกต่างจะบอกคุณบางอย่างเกี่ยวกับเนื้อหา ความสอดคล้องกันสูงระหว่างค่าเฉลี่ยทั้งสองหมายความว่าการแปลมีความชัดเจนค่อนข้างมาก การแตกต่างเผยให้เห็นว่าการตีความที่แท้จริงมีอยู่ตรงไหน — คำไหน, ระดับภาษาไหน, การแปลสำนวนแบบไหน
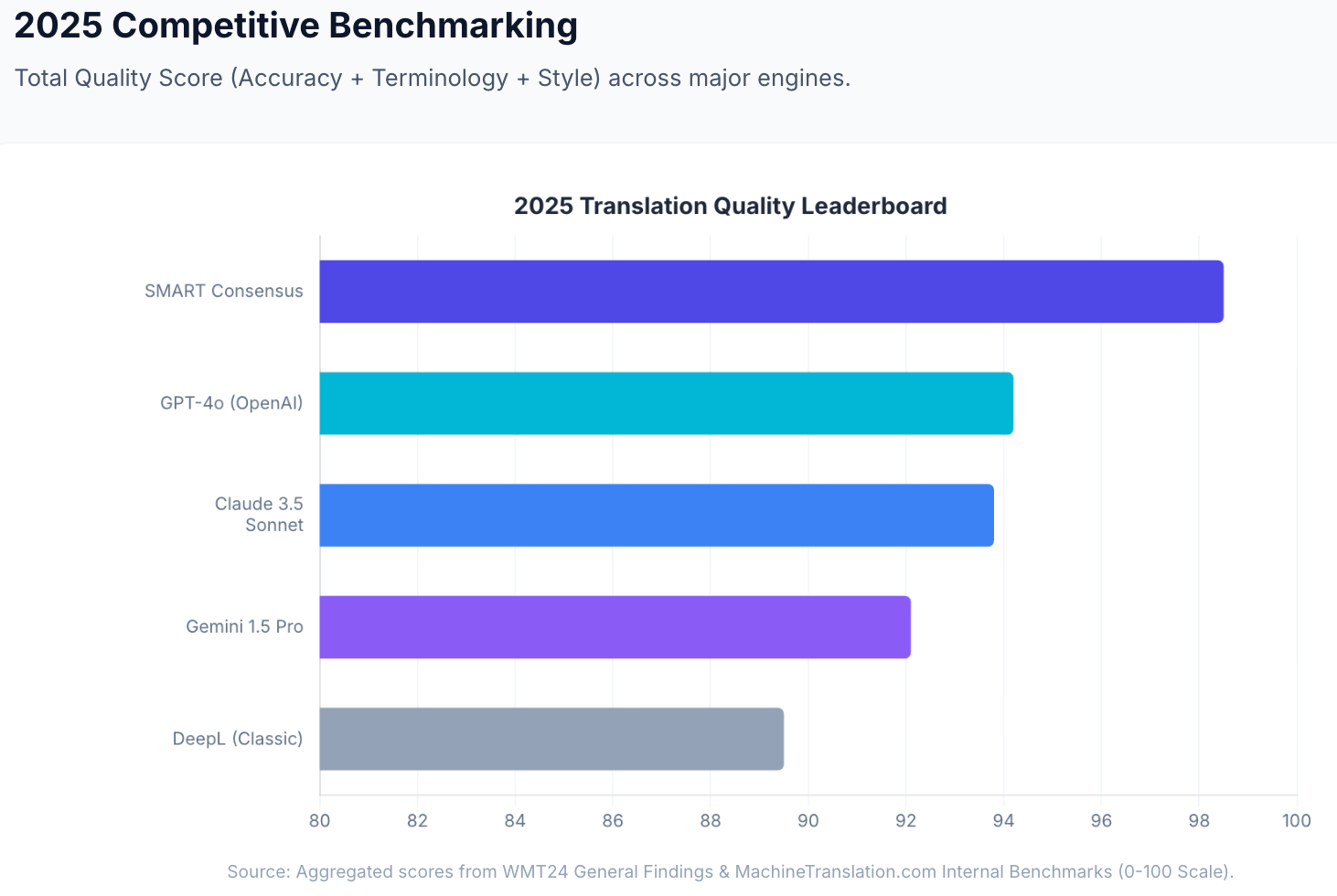
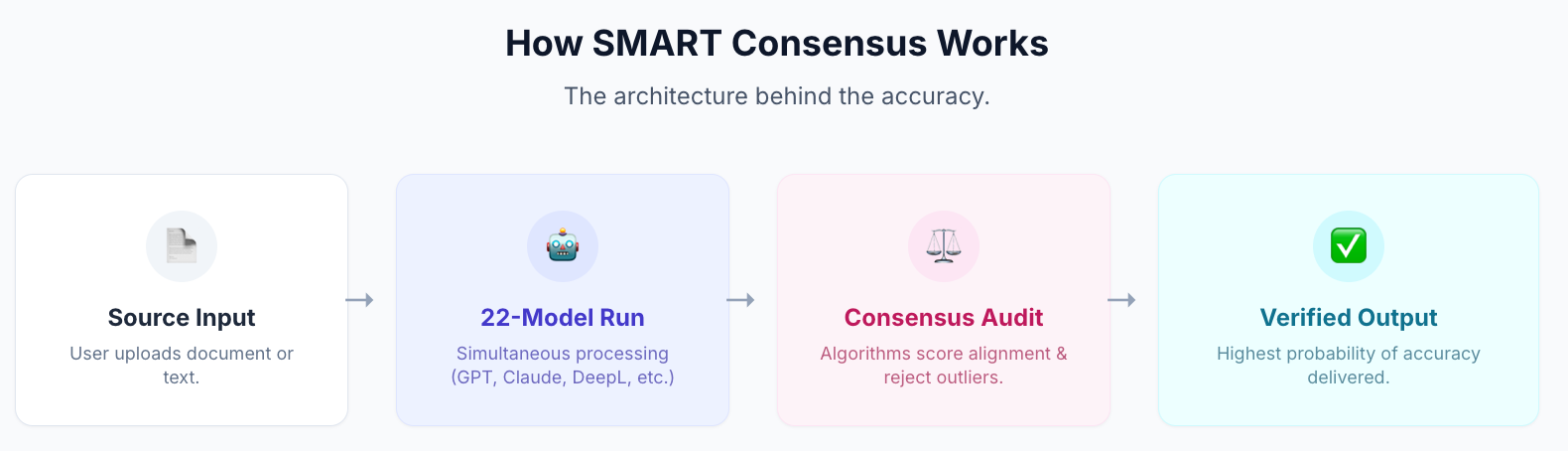
นี่คือสิ่งที่ระบบ SMART ของ MachineTranslation.com ทำในทางปฏิบัติ มันรันโมเดล AI พร้อมกัน 22 ตัว (รวมถึง Claude และ DeepL) และแสดงผลลัพธ์ที่โมเดลส่วนใหญ่เห็นพ้องกัน พร้อมกับคะแนนคุณภาพสำหรับแต่ละโมเดล การบรรจบกันคือสัญญาณ: เมื่อ Claude และ DeepL (และ 20 โมเดลอื่นๆ) แปลออกมาเหมือนกัน ความน่าจะเป็นที่การแปลนั้นถูกต้องจะสูงกว่าการเชื่อถือเพียงอย่างเดียว
ในการวัดผลภายในของ MachineTranslation.com วิธีการฉันทามตินี้ทำคะแนนคุณภาพรวมได้ 98.5 จาก 100 — เมื่อเทียบกับ Claude 3.5 Sonnet ที่ 93.8 และ DeepL Classic ที่ 94.2 ในฐานะเครื่องมือเดี่ยว ความแตกต่างไม่ได้เล็กน้อย: มันคือช่องว่างระหว่างการเชื่อถือการตีความของโมเดลหนึ่งกับการรู้ว่าโมเดลส่วนใหญ่เห็นด้วยกับอะไร
สำหรับงานแปลหลายอย่าง ไม่ว่าจะเป็น Claude หรือ DeepL ก็สามารถให้บริการคุณได้ดี สำหรับเนื้อหาที่การทำผิดพลาดมีผลกระทบที่แท้จริง การดูว่าพวกเขามีความเห็นตรงกันนั้นมีค่ามากกว่าการดูเพียงอย่างเดียว
คำถามที่พบบ่อย
1. Claude ดีกว่า DeepL สำหรับการแปลหรือไม่
ขึ้นอยู่กับประเภทของเนื้อหา DeepL ดีกว่าสำหรับการแปลภาษาในยุโรปแบบสั้นๆ จำนวนมาก โดยที่ความคล่องแคล่วและความรวดเร็วเป็นสิ่งสำคัญ Claude ดีกว่าสำหรับเอกสารขนาดยาว เนื้อหาซับซ้อนที่ต้องการคำศัพท์ที่สอดคล้องกันในหลายหน้า และคู่ภาษาที่อยู่นอกเหนือขอบเขต 33 ภาษาของ DeepL สำหรับเวิร์กโฟลว์ระดับมืออาชีพส่วนใหญ่ คำตอบที่ตรงไปตรงมาคือพวกมันแข็งแกร่งในรูปแบบที่แตกต่างกัน
2. อันไหนแม่นยำกว่ากัน: Claude หรือ DeepL?
ในการวัดประสิทธิภาพภายในของ MachineTranslation.com โดยใช้คำ 5,000 คำ ซึ่งเป็นเนื้อหาผสมระหว่างเทคนิคและการตลาด DeepL ทำคะแนนได้ 94.2% และ Claude 3.5 Sonnet ทำคะแนนได้ 93.8% ในระดับนั้น ความแตกต่างไม่มีความหมายในทางปฏิบัติสำหรับเนื้อหาส่วนใหญ่ สิ่งที่โคลดทำได้ดีกว่าคือเอกสารที่ยาวกว่า ซึ่งความสอดคล้องของบริบทมีความสำคัญ และการประมวลผลแบบทีละส่วนของ DeepL อาจทำให้เกิดความคลาดเคลื่อนของคำศัพท์ DeepL รองรับภาษาได้มากเท่ากับ Claude หรือไม่
3. ฉันสามารถใช้ Claude และ DeepL ร่วมกันได้หรือไม่
ไม่ได้โดยตรงภายในเครื่องมือใดเครื่องมือหนึ่ง MachineTranslation.com ทำงานทั้ง Claude และ DeepL พร้อมกันเป็นส่วนหนึ่งของระบบ 22 โมเดล โดยแสดงผลลัพธ์และคะแนนคุณภาพสำหรับแต่ละโมเดล และนำเสนอการแปลที่โมเดลส่วนใหญ่เห็นด้วย สำหรับผู้ใช้ที่ต้องการเปรียบเทียบทั้งสองอย่างโดยไม่ต้องจัดการการรวมระบบแยกต่างหาก เป็นวิธีปฏิบัติในการดูว่าเครื่องมือแต่ละอย่างจัดการกับเนื้อหาเดียวกันอย่างไร
4. DeepL หรือ Claude ดีกว่ากันสำหรับเอกสารทางกฎหมาย?
สำหรับเอกสารทางกฎหมายขนาดยาวที่ต้องการความสอดคล้องกันภายใน (คำจำกัดความที่ใช้สอดคล้องกัน, การใช้ภาษาที่เป็นทางการตลอดทั้งฉบับ, การอ้างอิงโยงระหว่างมาตรา) หน้าต่างบริบทของ Claude ถือเป็นข้อได้เปรียบที่สำคัญ สำหรับข้อความทางกฎหมายที่สั้นกว่า เช่น ข้อกำหนดมาตรฐานหรือข้อตกลงสั้นๆ ผลลัพธ์ของ DeepL มักจะคล่องแคล่วและรวดเร็ว สำหรับการแปลกฎหมายที่มีความเสี่ยงสูง ซึ่งข้อผิดพลาดนำมาซึ่งความรับผิดชอบ การตรวจสอบโดยมนุษย์ยังคงเป็นขั้นตอนสุดท้ายที่เหมาะสม ไม่ว่าเครื่องมือ AI ใดจะสร้างฉบับร่างขึ้นมาก็ตาม
5. DeepL มีราคาอย่างไรเมื่อเทียบกับ Claude?
แผนการสมัครสมาชิกของ DeepL เริ่มต้นที่ประมาณ $10.49/ผู้ใช้/เดือน สำหรับการใช้งานระดับมืออาชีพ Claude มีราคาต่อโทเค็นผ่าน API: $3.00 ต่อโทเค็นอินพุตหนึ่งล้านโทเค็นสำหรับ Sonnet 4 และ $15.00 สำหรับ Opus 4 สำหรับผู้ใช้ทั่วไปที่มีปริมาณปานกลาง การสมัครสมาชิกของ DeepL มักจะคาดการณ์ได้มากกว่า สำหรับเวิร์กโฟลว์ API ปริมาณมาก การเปรียบเทียบต้นทุนขึ้นอยู่กับความยาวและปริมาณของเอกสาร และไม่มีวิธีใดถูกกว่าอย่างสม่ำเสมอในทุกกรณีการใช้งาน

By Ofer Tirosh
Connect on LinkedInOfer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
Share: