May 14, 2026
Claude vs DeepL 翻译对比:哪个更好?
诚实的起点是:Claude 和 DeepL 实际上并没有在争夺相同的用户。
DeepL 是为翻译而构建的。自 2017 年以来,它一直在精炼一件事(以自然流畅的方式将文本从一种语言转换为另一种语言)。Claude 是 Anthropic 开发的通用推理模型,恰好翻译得非常好,尤其是在内容冗长、复杂或需要深度语境理解的情况下。
“Claude vs DeepL”这个问题对于那些真正决定如何处理专业翻译工作并希望得到一个清晰明确答案(而不是营销比较)的人来说很重要。本文旨在阐述以下内容。
本文将探讨以下内容:
- 每个工具的构建目的
- Claude 和 DeepL 在准确性方面如何比较?
- DeepL 真正具有优势的地方
- Claude 领先的地方
- 语言覆盖范围和文档处理
- 定价:你实际支付的费用
- 应该使用哪一个?
- 同时运行两者会发生什么
- 常见问题解答
每个工具的用途
Claude:用于翻译的推理模型

Claude 由 Anthropic 开发,其核心是一个大型语言模型,旨在跨越广泛的任务进行推理、分析和生成。翻译是一项任务,事实证明 Claude 非常擅长这项任务——尤其是在上下文决定含义的内容方面:法律文件、文学文本、技术规范,以及任何无法孤立理解的句子。
目前的 Claude 4 系列(Claude Opus 4 和 Claude Sonnet 4)具有 200,000 个 token 的上下文窗口,这改变了翻译的可能性。逐段工作的文档翻译器会遗漏句子间的依赖关系、角色名称或术语中的不一致性,以及章节间的语气变化。克劳德没有这个问题。当你给它输入一份完整的合同,它会看到整个合同。
根据Intento的《2025年翻译自动化现状》,Claude Opus 4 和 Claude Sonnet 3.7 在英语到德语、英语到荷兰语、英语到意大利语、英语到日语和英语到韩语的语言对中,在自动化和人工LQA评估中,均名列表现最佳的单代理解决方案之列。
DeepL:一个专门为翻译而构建的工具

DeepL只做一件事,并为此进行了不懈的优化。它的神经机器翻译引擎经过专门针对翻译相关数据的训练,这种专业性体现在其输出中:DeepL 翻译在欧洲语言对上的表现通常比大多数竞争对手更自然。措辞地道,语法清晰,而且文风通常与原文相符。
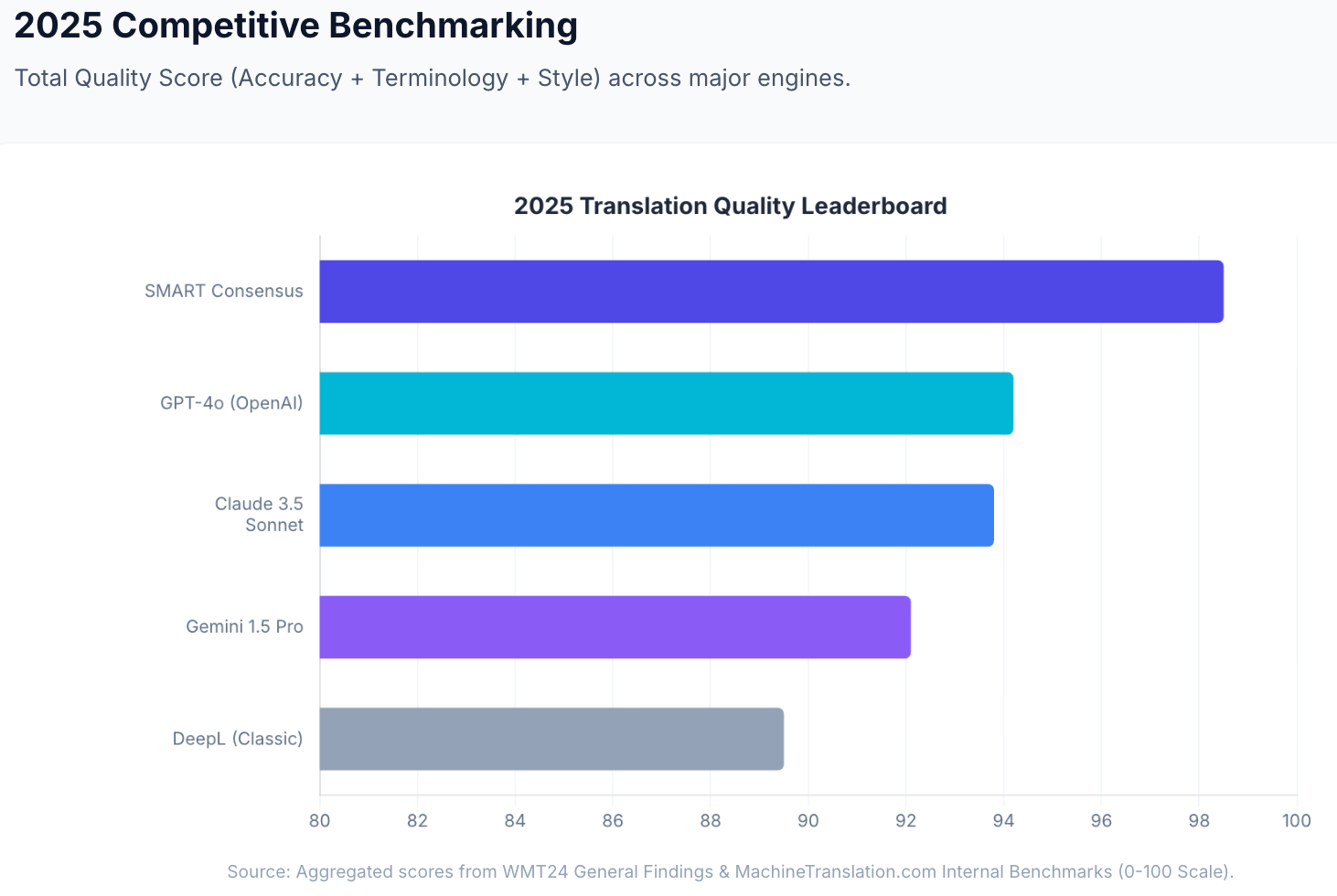
在 MachineTranslation.com 针对 5,000 字混合技术和营销内容的内部基准测试中,DeepL 的准确率达到 94.2%——在所有接受测试的独立引擎中最高,并在基准测试中被描述为“流畅之王”。对于欧洲语言对而言,它的声音听起来最像人类。
DeepL 还在 2024 年推出了 DeepL next-gen,这是一个专门为翻译而构建的 LLM,它在经典模型的基础上进行了改进,适用于更长的文本,并且 Intento 的 2025 年评估 将其列为在包括英语到西班牙语、法语、意大利语、荷兰语、韩语和葡萄牙语在内的多种语言对中表现最佳的实时解决方案之一。
这种专业化的权衡是:DeepL 支持 33 种语言,这很狭窄。这是一个单模型系统——你收到的输出是 DeepL 的解释,没有交叉检查信号,也无法知道它何时做出了你可能不同意的选择。
Claude 和 DeepL 在准确性方面如何比较?
答案很大程度上取决于你翻译的内容以及翻译成哪种语言。
欧洲语言对
对于核心欧洲语言对(德语、法语、西班牙语、意大利语、荷兰语、葡萄牙语),DeepL next-gen 确实具有竞争力。Intento 在 2025 年的人工语言质量评估中,在评估的 11 对语言对中,有 6 对语言对名列前茅。输出听起来自然、地道,且恰当正式,无需用户进行任何提示工程。
Claude Opus 4 和 Sonnet 3.7 在其中几个配对中也名列前茅,尤其是在英语到德语和英语到荷兰语的翻译中,Claude 的上下文推理能力帮助它处理形态复杂性和长文本中的格一致性。
在这个水平上的实际差异:对于简短、标准的内容(产品描述、表单字段、用户界面文案),DeepL 的速度优势很重要,而且它的质量也很稳定。对于更长、更复杂的内容,Claude 的上下文窗口和推理深度会产生明显更强的输出。
长文档和上下文处理
这里的比较就不那么接近了。
根据 MachineTranslation.com 的内部分析{10},现代 AI 翻译中 remaining 的错误几乎完全是语义上的:语调错误、文体错误、术语错误、句子间依赖关系缺失。这些不是逐段翻译能捕捉到的错误。这些错误只有在您阅读完整文档时才会浮出水面,您会注意到一个角色的头衔在三页后发生了变化,或者一个已定义的术语在两个从句中被以不同的方式呈现。
Claude 的 200,000 个 token 上下文窗口意味着它可以在其工作内存中容纳整个法律协议、技术手册或文学章节,并生成在整个文档中内部一致的翻译。DeepL 的文档翻译功能逐节处理内容,这对于结构化文档通常效果很好,但可能会引入 Claude 故意避免的那种漂移。
技术和特定领域内容
这两个工具都能很好地处理一般的技术内容。对于高度专业化的领域(法律、医疗、金融),结果取决于源内容与每个工具的训练数据的匹配程度。
DeepL 允许在付费 API 计划中注入术语表,这有助于保持术语一致性。Claude,通过 API 使用或在结构良好的提示中使用时,可以吸收完整的术语表作为上下文,并在整个过程中应用它。两种方法都没有绝对的优势;两者都需要用户进行设置工作。DeepL 真正具有优势的地方在于欧洲语言对的自然度和流畅度。当翻译需要听起来像是由母语人士撰写时(营销文案、品牌传播、面向消费者的内容),DeepL 的输出始终是最自然的。Claude 翻译准确,但 DeepL 的输出,尤其是对于欧盟语言对,读起来更地道。
速度。 DeepL 是一个为吞吐量优化的 NMT 引擎。对于高容量、时间敏感的工作流程,它比以 LLM 速度运行的 Claude 快得多。
工作流程集成。 DeepL 拥有成熟的生态系统:CAT 工具插件、文档齐全的 API、术语表管理和语气设置(正式/非正式)。它以 Claude 这样的通用模型无法原生实现的方式融入专业翻译人员的工作流程中。
标准内容的输出保持一致性。 对于翻译任务定义明确且输出只需要可靠正确的内容,DeepL 减少了变量。你大致知道你将得到什么。
Claude 的优势在于
冗长、上下文复杂的文档。 一份 40 页的合同、一章文学作品、一份多部分的 技术规范——Claude 一次性处理整个文档,并保持其一致性,而逐段翻译无法做到这一点。
细微差别和语域。 Claude 3.5 Sonnet 在 MachineTranslation.com 的内部质量基准测试中得分 93.8 分(满分 100 分),在语气至关重要的内容方面表现出色:品牌声音翻译、利益相关者沟通以及“技术上正确”是不够的专业通信。
多语言广度。 Claude 支持比 DeepL 的 33 种语言更广泛的语言。对于在 DeepL 核心欧洲覆盖范围之外工作的团队来说,Claude 填补了一个真正的空白。
关于文本的推理。 如果您不仅仅是翻译,还要求模型为不同的受众调整内容、调整语域或标记文化上不合适的短语,Claude 会在同一任务中完成这些。DeepL 翻译。Claude 也认为。
语言覆盖范围和文档处理
| Claude (Opus 4 / Sonnet 4) | DeepL (Classic + next-gen) | |
|---|---|---|
| 支持的语言 | 广泛的多语言支持(100+) | 33 种语言 |
| 上下文窗口 | 最多 200,000 个 token | 逐段 |
| 文档格式 | 通过 API 或文件上传 | PDF、DOCX、PPTX、XLSX |
| 版面保留 | 有限 | 强大(保留原始格式) |
| 文件大小 | 取决于 token 数量 | 在高级套餐中最多 30MB |
| 术语表支持 | 通过提示/API | 原生术语表功能 |
| CAT 工具集成 | 否 | 是(支持主要的 CAT 工具) |
关于文档的一个实用说明:DeepL 在翻译 DOCX 和 PDF 文件时会保留原始格式,这对于翻译后需要重新排版的商务文档来说,确实非常有用。Claude 通过 API 进行的文档翻译无法以相同方式保留布局,这对于任何无需后期处理即可直接分发的内容都至关重要。
定价:你实际支付的费用
Claude (通过 Anthropic API):
- Claude Sonnet 4:每百万输入tokens 3.00 美元 / 每百万输出tokens 15.00 美元
- Claude Opus 4:每百万输入tokens 15.00 美元 / 每百万输出tokens 75.00 美元
- 通过 Claude.ai:免费套餐,有使用限制;专业版每月 20 美元
DeepL:
- 免费:字符数有限,每月 3 份不可编辑的文档翻译
- 入门:约 10.49 美元/用户/月
- 高级:约 34.49 美元/用户/月
- 终极:约 68.99 美元/用户/月
- API 专业版:每百万字符 25 美元
对于大多数个人专业用户来说,DeepL 的订阅定价更可预测。对于 API 密集型工作流程,比较取决于数量:Claude 的按令牌定价与 DeepL 的按字符模式的规模不同,在高容量下,差异可能取决于平均文档长度和翻译方向。
您应该使用哪一个?
选择取决于您要翻译的内容,而不是哪个工具客观上更好。
| 用例 | 更好的选择 |
|---|---|
| 营销文案、面向消费者的欧盟内容 | DeepL |
| 需要一致性的长篇法律或技术文档 | Claude |
| UI 字符串、大批量产品描述 | DeepL |
| 文学或品牌声音翻译 | Claude |
| DeepL 之外的 33 种受支持语言 | Claude |
| 与 CAT 工具或 TMS 集成的流程 | DeepL |
| 需要保留格式的内容 | DeepL |
| 复杂的多语言推理或改编 | Claude |
| 快速、大批量标准翻译 | DeepL |
| 敏感内容,其中上下文细微差别最为重要 | Claude |
没有永久的答案。一个将产品目录翻译成法语的团队和一个将法律意见翻译成日语的团队需要不同的默认设置。
当您同时运行两者时会发生什么?
有人认为,Claude 与 DeepL 的对比并不是最有用的框架。两者都是具有不同优势的强大工具。更有用的问题是:如何兼得两者之长?
当你在同一篇源文本上运行 Claude 和 DeepL 并比较输出结果时,差异会告诉你一些关于内容的信息。两个均值之间的高度一致意味着翻译相对明确。分歧揭示了真正存在解释性选择的地方——哪个词,哪个语域,哪个惯用语的表达方式。
这就是 MachineTranslation.com 的 SMART 系统在实践中所做的。它同时运行 22 个 AI 模型(包括 Claude 和 DeepL),并呈现大多数模型趋于一致的输出,以及每个模型的质量评分。汇聚是信号:当 Claude 和 DeepL(以及其他 20 个模型)给出相同的翻译时,该翻译正确的概率在结构上高于单独信任任何一个模型。
在 MachineTranslation.com 的内部基准测试中,这种共识方法实现了 98.5 分(满分 100 分)的聚合质量得分——相比之下,Claude 3.5 Sonnet 为 93.8 分,DeepL Classic 为 94.2 分,作为独立引擎。区别并非微不足道:这是信任一个模型的解读与了解大多数模型达成共识之间的差距。对于许多翻译任务,Claude 或 DeepL 都能很好地为您服务。对于那些出错会造成严重后果的内容,看到他们达成一致的地方比单独看任何一方都更有价值。
常见问题解答
1.Claude 在翻译方面比 DeepL 更好吗?
这取决于内容类型。DeepL 更擅长短篇幅、大批量欧洲语言翻译,在这种情况下,流畅度和速度是首要考虑因素。Claude 更擅长处理长篇文档、需要跨多页保持术语一致的复杂内容,以及 DeepL 33 种语言覆盖范围之外的语言对。对于大多数专业工作流程而言,诚实的回答是它们在不同方面都很强大。
2.哪一个比较准确:Claude 还是 DeepL?
在 MachineTranslation.com 内部针对 5,000 个词的混合技术和营销内容的基准测试中,DeepL 的准确率为 94.2%,Claude 3.5 Sonnet 的准确率为 93.8%。在那个水平上,对于大多数内容来说,差异在实践上没有意义。Claude 的独特之处在于处理上下文一致性至关重要的较长文档,而 DeepL 逐段处理可能会导致术语漂移。
3.DeepL 支持的语言数量是否与 Claude 一样多?
否。DeepL 支持 33 种语言,尤其擅长欧洲语言对。Claude 处理的语言范围更广,包括 DeepL 训练重点之外的不太常见的语言对。对于 DeepL 列表中没有的任何语言,Claude 是更强大的选择。
4.我可以一起使用 Claude 和 DeepL 吗?
不能直接在任何一个工具中使用。MachineTranslation.com 同时运行 Claude 和 DeepL,作为其 22 模型系统的一部分,向您展示每个模型的输出和质量评分,并呈现大多数模型都同意的翻译结果。对于希望在不管理单独集成的情况下比较两者的用户来说,这是一种查看每个工具如何处理相同内容的实用方法。
5.对于法律文件,DeepL 或 Claude 哪个更好?
对于需要内部一致性的长篇法律文件(定义术语使用一致,始终保持正式语域,条款之间的交叉引用),Claude 的上下文窗口是一个有意义的优势。对于标准条款或简短协议等较短的法律文本,DeepL 的输出通常流畅且快速。对于涉及高风险的法律翻译,错误会带来法律责任,无论哪个 AI 工具生成草稿,人工校对仍然是合适的最后一步。
6.DeepL 的定价与 Claude 相比如何?
DeepL 的订阅计划起价约为 10.49 美元/用户/月,供专业使用。Claude 通过 API 按 token 定价:Sonnet 4 每百万输入 token 3.00 美元,Opus 4 每百万输入 token 15.00 美元。对于进行适度翻译量的个人用户来说,DeepL 的订阅通常更可预测。对于高容量的 API 工作流程,成本比较取决于文档长度和数量,并且在所有用例中,两者都不是始终更便宜的。