June 10, 2026
GPT-4.1 对 DeepSeek V3:准确性、幻觉和翻译性能比较
到2026年中期,大多数翻译团队都在默默地问一个问题,而不是“我们应该使用人工智能吗?”,这个决定已经做出了。真正的问题在于应该标准化哪个AI模型,以及这个答案是否对每种语言对、每种文档类型和每种预算都相同。
GPT-4.1和DeepSeek V3已成为专业翻译工作流程中最常评估的两个选项。它们代表着截然不同的理念:一个是OpenAI精心打造、商业化程度高的API;另一个是中国研究实验室推出的开源、MIT许可的模型,在WMT24基准测试中悄然超越了数个专有竞争对手。两者都没有绝对的优势。每个案例的适用性取决于您要翻译的内容、翻译对象以及翻译的限制条件。
本文将从对翻译人员、本地化经理和企业买家最重要的维度对这两种模型进行细分:在真实语言对上的准确性、幻觉行为、处理术语表遵守等约束性任务的能力,以及大规模运行任一模型的总成本。
目录
- 为什么现在进行此比较很重要
- 每种模型实际是什么
- 正面交锋:翻译准确性和基准性能
- 哪个模型更容易产生幻觉,以及何时会产生幻觉?
- 哪个模型在受限翻译方面表现更好?
- 成本和部署:规模化后会有哪些变化?
- 如何在不承诺任何一方的情况下测试这两种模型?
- 在您的翻译工作流程中应该选择哪种模型?
- 常见问题解答
- 相关比较
为什么这次比较现在很重要?
翻译买家历来在狭窄的轴线上评估机器翻译:BLEU分数与价格的比较。大型语言模型彻底打破了这一框架。GPT-4.1 和 DeepSeek V3 并非传统意义上的机器翻译(MT)引擎——它们是具有强大多语言能力的通用模型,其在翻译任务上的表现因架构、训练数据以及提示方式的不同而异。
这种可变性是评估问题的关键。一位本地化经理在测试两种模型处理英语到西班牙语的营销文案时,可能会看到几乎相同的输出质量。同样的经理测试阿拉伯语→英语法律文件可能会看到一个有意义的差距——但哪个模型表现更好取决于文件是否包含需要世界知识而非模式匹配的命名实体、技术术语或文化参考。
风险也是不对称的。DeepSeek V3 运行成本要低几个数量级,尤其是自托管时。GPT-4.1 的成本溢价相当高。如果两个模型在您的特定工作负载上都能提供可接受的质量,那么成本差异将决定人工智能翻译工作流在规模化上是否具有经济可行性。
每个模型实际是什么
GPT-4.1:OpenAI 的指令微调旗舰模型
GPT-4.1 于 2025 年 4 月发布,是 OpenAI 迄今为止最遵循指令的模型。它在GPT-4o之上的主要改进并非原始翻译的流畅性(这方面它已经很强了),而是遵循复杂、多部分指令的精确性。对于翻译工作流,这在约束性任务中尤为重要:应用客户术语表、在长文本中保留文档格式、维持特定语域或遵守“请勿翻译”列表。
GPT-4.1 支持一百万个 token 的上下文窗口,这意味着它可以一次性处理书籍长度的文档。在结构化输出任务(生成 JSON 格式的翻译记忆库、在翻译旁边生成句子级别质量分数、格式化双语表格)方面,它比前代产品更加可靠。权衡是成本:GPT-4.1 的价格高于大多数替代品,包括 DeepSeek
V3。开源的挑战者
DeepSeek V3(当前生产版本为DeepSeek-V3-0324)是一个拥有6850亿参数的模型,它构建在混合专家(Mixture-of-Experts)架构之上——这意味着对于任何给定的输入,只有一部分参数会被激活,这使得尽管总参数量巨大,推理成本却保持较低。它是在MIT许可下发布的,这意味着组织可以自行托管、微调并商业部署它,而无需向第三方支付按令牌收费。
在WMT24之后,该模型的翻译性能引起了广泛关注,在中文↔英语、阿拉伯语和韩语语言对上取得了优异的BLEU和COMET分数——在某些情况下甚至优于GPT-4o。对于大量使用亚洲或中东语言对的团队来说,DeepSeek V3 不是一个妥协的选择。它以极低的成本真正具有竞争力。
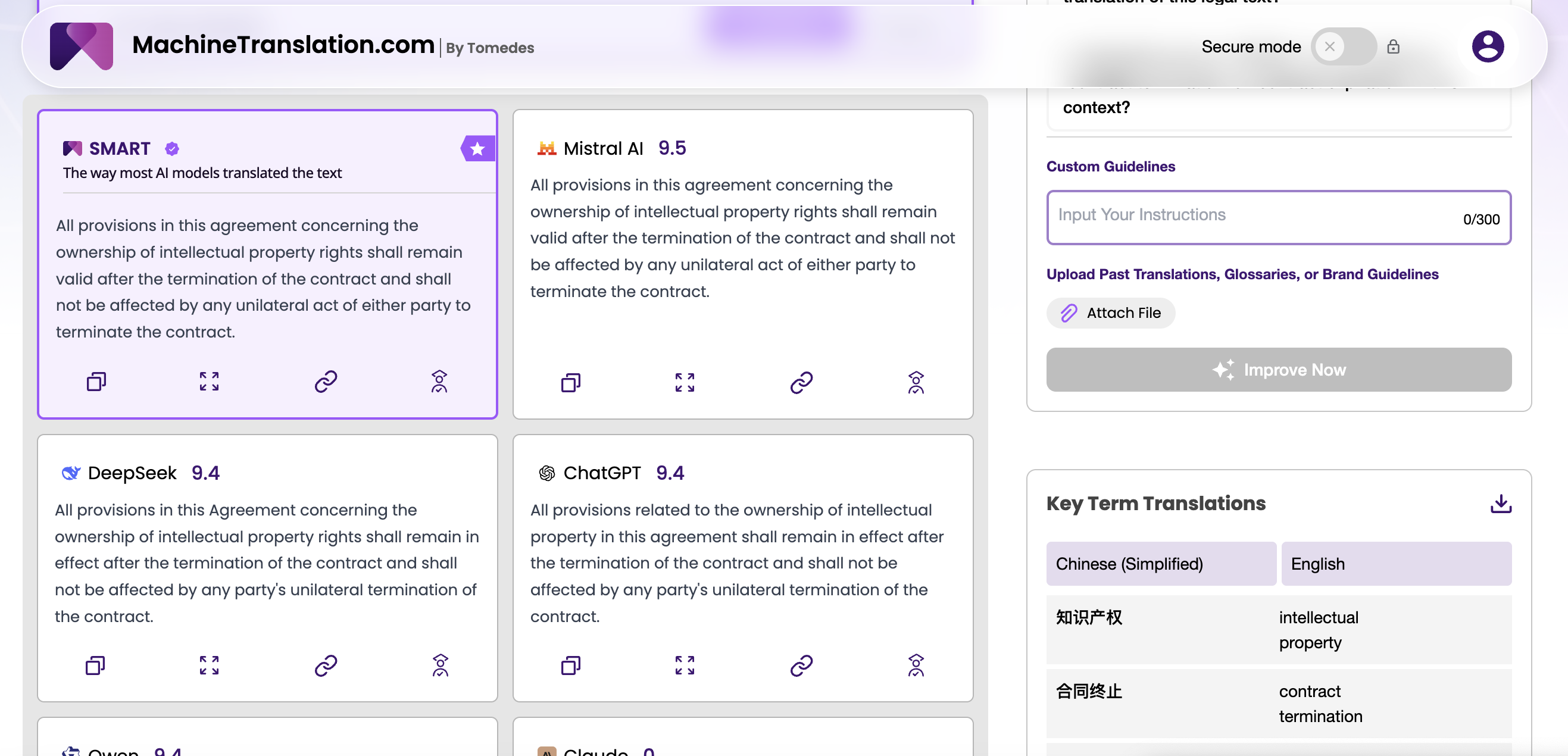
正面交锋:翻译准确性和基准性能
| 维度 | GPT-4.1 | DeepSeek V3 |
|---|---|---|
| 上下文窗口 | 1,000,000 词元 | ~64,000 词元(标准) |
| 架构 | 密集Transformer | 专家混合(685B 参数) |
| 许可证 | 专有 | 开源(MIT) |
| 自托管 | 不可用 | 可用 |
| WMT24 中↔英 | 强 | 非常强,在多个对上表现优于 GPT-4o |
| WMT24 阿拉伯语翻译 | 有竞争力 | 强,尤其是在专业文本上 |
| 指令遵循 | 与 GPT-4o 相比,同类最佳 | 良好;在复杂的多步提示上一致性较差 |
| 结构化输出 | 高度可靠 | 可靠;长输出上存在轻微的格式漂移 |
| 幻觉倾向 | 与 GPT-4o 相比有所减少 | 在低资源对上偶尔出现 |
| 相对 API 成本 | 较高 | 显著较低 |
在高资源语言对(英语、法语、西班牙语、德语、中文、日语)上的一般翻译准确性方面,两种模型都达到了专业译员所说的“译后编辑就绪”的水平。仅就流畅度和充分性而言,它们之间的差距不足以促使大多数团队做出购买决定。
有意义的差异出现在三种特定场景中:低资源语言、受限任务和易产生幻觉的文档类型。
哪个模型更容易产生幻觉,以及在何时产生?
翻译中的幻觉与通用生成中的幻觉不同。该模型是根据源文本工作的,它不是凭空捏造事实。幻觉在此表现为添加了源文本中不存在的内容、遗漏子句或替换命名实体。在法律或医疗翻译中,任何这些错误都可能导致严重后果。GPT-4.1 的幻觉率明显低于 GPT-4o,尤其是在长文档方面,早期 OpenAI
模型在后期部分会开始偏离原文。一百万个token的上下文窗口和改进的指令遵循能力的结合,意味着GPT-4.1能够更长时间地保持对源文本的忠实度,而无需特殊的提示策略。对于处理监管文件、产品文档或合同的企业买家来说,这是一个有意义的可靠性升级。
DeepSeek V3 的幻觉特征有所不同。对于支持良好的语言对(中文、英文、阿拉伯文),它通常是可靠的。低资源语对的风险会增加:韩语→斯瓦希里语、阿拉伯语→越南语,或任何一种语言在训练语料库中代表性不足的组合。在这些情况下,已观察到 DeepSeek V3 会生成听起来合理但不受源支持的内容,尤其是在源包含模糊的命名实体或特定领域术语时。
实际影响:如果您的语言对组合集中在高资源语言上,则可以通过标准的问答流程来管理 DeepSeek V3 的幻觉风险。如果您在低资源语言对上大规模运行翻译,GPT-4.1 的额外可靠性可能值得其溢价。
💬 “我们在平台上持续看到的是,GPT-4.1 和 DeepSeek V3 在幻觉方面的差距不在于数量,而在于发生的地点。”在英语、法语或西班牙语内容上,大多数专业译者不会注意到可靠性上有实质性差异。DeepSeek V3 的问题往往出现在包含不熟悉专有名词或高度领域特定术语的韩语或阿拉伯语文档上。GPT-4.1 更保守地处理这些边缘情况,它不太可能用听起来合理的东西来填补空白。”
— MachineTranslation.com 上的语言学家
哪个模型在受限翻译方面表现更好?
受限翻译(模型必须遵守术语表、保持品牌语域、避免翻译某些术语或保留文档结构,如标题和脚注)是 GPT-4.1 的架构优势最显而易见的地方。
当您提供一个包含 200 个术语的术语表的系统提示,并指示模型标记任何找不到精确匹配的源片段时,GPT-4.1 会以早期模型在几百个 token 之外无法维持的一致性来遵循这些指令。在一个一百万token的上下文窗口中,这意味着您可以在一次调用中翻译一本包含复杂术语约束的400页技术手册,并期望在整个过程中都能一致地应用术语表。
DeepSeek V3能够充分处理简单的约束——单术语禁止翻译指令、基本寄存器偏好、简单的格式规则。它表现不佳的地方在于复杂的复合指令集。随着同时约束数量的增加,DeepSeek V3 开始以难以通过测试预测的方式优先处理某些指令。对于管理多级样式指南和大型翻译内存的本地化团队来说,这种不一致会在下游产生质量保证开销,部分抵消了模型的成本优势。
对于标准内容的纯粹、无约束的翻译(一般商务沟通、营销文案、电子商务产品描述),两种模型在约束处理方面的差距在很大程度上是无关紧要的。差异对于运行企业级工作流的团队来说最为重要,在这些工作流中,翻译是多阶段本地化流程中的一个环节。
💬 “我们将两种模型应用于同一份词汇表,处理了约 12 万字的法律文件集,涉及八种语言对。GPT-4.1 几乎完美地遵守了术语限制。DeepSeek V3 表现接近,但有时会将客户明确要求避免的词语替换成近义词。在这个音量下,“差不多”是不够的。对于不受限制的内容,我们使用 DeepSeek V3,并且节省了大量成本。对于任何带有客户批准的词汇表的项目,我们仍然运行 GPT-4。1。”
— MachineTranslation.com 上的本地化经理
成本和部署:规模上的变化
成本是两种模型分歧最大的地方,也是评估必须考虑每令牌定价以外因素的地方。
GPT-4.1 定价为高端级别。对于每月通过 OpenAI API 处理数百万字词的组织来说,成本会迅速累积。该模型不支持自托管,这意味着每个 token 都需要支付 API 费用,而无法通过基础设施投资来降低成本。
DeepSeek V3 的成本模型则截然不同。通过 DeepSeek API,每个 token 的成本远低于 GPT-4.1。自托管,经济效益进一步转变:拥有 GPU 基础设施的组织可以以主要由计算成本而非按令牌计费许可决定的价格运行 DeepSeek V3。对于大批量翻译操作(例如全球电子商务目录、多语言内容管道、监管文件处理),在企业规模下,这种差异每年可能节省数十万美元。
DeepSeek V3 的开源许可证对于数据敏感型行业也很重要。无法将客户文件发送到外部 API 的法律、金融和医疗保健组织可以在本地部署 DeepSeek V3。GPT-4.1 没有提供同等的选项。
决策规则相对清晰:如果您的工作负载量大,语言对支持良好,并且您的数据治理政策允许使用 API 服务或本地部署,那么 DeepSeek V3 可以以显著更低的成本提供具有竞争力的质量。如果您的工作负载涉及约束性翻译、长文档保真度或低资源语言对,GPT-4.1 的可靠性可能值得您支付额外费用。
如何在不承诺任何一方的情况下测试这两种模型
对于大多数本地化团队而言,模型选择的实际障碍不在于不理解基准测试——而在于为两种模型设置独立的 API 集成、设计可比的测试条件以及在您自己的内容上运行有意义的评估所带来的摩擦。
MachineTranslation.com 消除了这一障碍。该平台同时运行 GPT-4.1 和 DeepSeek V3,使专业译者和本地化经理能够将相同的源文本同时提交给两个模型,并实时比较输出——无需单独的 API
密钥,无需采购流程,也无需承诺使用任一模型。这很重要,因为数据集级别的基准测试性能并不总是能预测其在您特定内容上的表现。在 WMT24 中文→英文新闻文本上获得高 COMET 分数的模型,在您公司的特定术语或领域上表现可能不佳。唯一具有决策相关性的评估是在您自己的文档、您自己的约束条件和您自己的语言对上进行的。
MachineTranslation.com 将自己定位为一个中立的多模型平台,这意味着它没有商业动机偏袒 GPT-4.1 或 DeepSeek V3。该平台的角色是为您提供比较数据,以便您自己做出决定,并在评估完成后以生产规模运行您选择的任何模型。当然,它还会提供大多数 AI 模型都同意的最优默认翻译。
对于也在评估 OpenAI 模型层级的团队来说,GPT-4.1 与其他 OpenAI 模型(包括 GPT-4.5 和 GPT-4o)的比较,在确定模型版本之前提供了有用的背景信息。 而对于在2025年初评估过DeepSeek
V3与GPT-4o的团队来说,本文将介绍GPT-4.1发布后有哪些变化。您应该为您的翻译工作流选择哪个模型?与其给出单一的建议,不如以下框架反映了大多数专业翻译团队会发现有用的决策逻辑:从您的语言对开始。
-
如果您的投资组合集中在中国↔英语、阿拉伯语或韩语,DeepSeek V3 在 WMT24 上的表现使其成为自然的首选测试。如果您主要使用术语受限的欧洲语言,GPT-4.1 可能会从一开始就产生更一致的输出。
-
评估您的约束复杂性。单层约束(一个词汇表,一个登记册)可以被任一模型充分处理。多级约束(词汇表+格式+不翻译列表+QA评分),GPT-4.1目前更可靠。
-
根据成本差异调整您的销量。每月低于 500,000 字,绝对的 API 成本差异可能不会对您的预算产生实质性影响。超过这个阈值,DeepSeek V3 的成本优势将越来越难以忽视。
-
考虑您的数据治理要求。如果文档无法离开您的基础设施,DeepSeek V3 自托管是目前两个选项中唯一可行的选择。
-
在您自己的内容上运行评估,而不是在基准测试上。使用MachineTranslation.com提交实际工作负载中的代表性样本给两个模型,并在承诺之前根据您自己的质量标准对输出进行评分。
为了更全面地了解这些模型在当前人工智能翻译领域中的地位,2026年最佳人工智能翻译工具涵盖了完整的竞争领域,包括大型语言模型与专用翻译基础设施的比较。
常见问题解答
1.GPT-4.1 比 DeepSeek V3 更适合翻译吗?
没有一个模型在所有方面都更好。GPT-4.1 在受限翻译任务、长文档保真度和低资源语言对(幻觉风险较高)方面优于 DeepSeek V3。DeepSeek V3 在多项 WMT24 基准测试(特别是中文↔英文、阿拉伯文和韩文)上表现与 GPT-4.1 相当或更优,并且在大规模运行或自托管时成本显著更低。
2.DeepSeek V3 比 GPT-4.1 更容易产生幻觉吗?
在高资源语言对上,幻觉差异相对较小。在低资源语对和包含稀有命名实体的领域特定内容方面,差距正在扩大,DeepSeek V3 在这些方面显示出更高的源不支持的添加或替换率。GPT-4.1 与 GPT-4o 相比,幻觉有所减少,尤其是在处理长文档时。
3.我可以在商业上使用 DeepSeek V3 吗?
可以。DeepSeek V3 在 MIT 许可下发布,该许可允许商业用途,包括微调和自托管。无法将文档发送到外部 API 的组织可以在其自己的基础设施上部署 DeepSeek V3。GPT-4.1 需要在使用 OpenAI 服务条款下使用 OpenAI API,并且无法自行托管。
4。哪种模型更适合中文到英文的翻译?
根据 WMT24 基准测试结果,DeepSeek V3 在中文↔英文方面具有优势。然而,对于涉及约束术语、法律精确性或复杂格式的中文到英文翻译,GPT-4.1
的指令遵循能力使其在人工译后编辑输出的生产工作流程中更加可靠。我可以在选择之前并排测试 GPT-4.1 和 DeepSeek V3 吗?
可以 — MachineTranslation.com 同时运行这两个模型(以及 20 多个模型),并允许您实时比较自己内容上的输出,无需单独的 API 帐户或采购流程。
6.DeepSeek V3 与 Claude 在翻译方面有何区别?
对于也在评估 Anthropic 模型的团队来说,Claude 与 DeepSeek V3 的比较涵盖了在与翻译相关的场景下,架构、准确性和部署选项的关键差异。