June 2, 2026
Grok 对比 Llama 翻译:哪个AI模型表现更好?
两种截然不同的理念开始一项翻译任务。
Grok 由 xAI 构建,实时连接来自网络和 X 的实时数据,并针对快速变化的语言进行了优化 — 流行俚语、时事、以及每周都在变化的文化参考。Llama 由 Meta 构建,向世界开源发布,并设计为可在您自己的基础设施上下载、修改和部署,且每代币成本为零。
它们都包含在 MachineTranslation.com 的 24 模型共识系统中。他们都翻译。它们确实适合不同类型的翻译工作。
本文将介绍它们各自擅长什么、各自的不足之处,以及当您在相同内容上对它们进行并排测试时会发生什么。
本文中
- 什么是 Grok 以及它如何处理翻译?
- 什么是 Llama 以及它如何处理翻译?
- Grok 对比 Llama:翻译质量比较
- Llama 在翻译方面比 Grok 更好吗?
- 哪一个更适合文档翻译?
- 我可以在本地运行 Llama 进行翻译吗?
- MachineTranslation.com 如何同时使用 Grok 和 Llama
- 常见问题
Grok 是什么,它是如何处理翻译的?

Grok 由埃隆·马斯克创立的人工智能公司 xAI 开发,并结合了通用网络数据和来自 X(前身为 Twitter)的实时内容进行训练。当前版本是 Grok 3 和 Grok 4,分别于2025年2月和7月发布。Grok在架构上与大多数AI模型不同之处在于实时数据访问——它可以在推理过程中从当前的网页内容和X平台获取信息,而不是依赖固定的训练快照。
对于翻译而言,这以一种特定而狭窄的方式很重要。Grok 尤其擅长翻译提及快速变化的时事、流行术语、网络俚语和文化典故的内容。如果你需要翻译一篇关于最近新闻报道、产品发布公告或三周前出现的流行语的社交媒体帖子,Grok 的实时数据访问能力赋予它去年数据训练的模型根本不具备的上下文。
这是一个真正的优势。它也是一个相当具体的模型。
除了时间敏感内容,Grok 在翻译方面表现得像大多数前沿大型语言模型一样:在主要语言对上表现出色,在低资源语言上表现较弱,并且受到所有单一模型系统共有的相同结构性限制——没有机制来验证其自身的输出。
消费者可以通过 X Premium+(每月 22 美元)或 SuperGrok(每月 30 美元)访问 Grok,也可以通过 xAI 的 API 访问,大约每百万输入 token 0.20 美元。它无法自托管。无法在自定义数据上进行微调。
Llama 是什么?它如何处理翻译?
Llama 是 Meta 的开源权重 AI 模型系列。当前一代 (Llama 4 Maverick 和 Llama 4 Scout) 于2025年发布,在能力和语言覆盖范围两方面都比Llama 3有了显著的飞跃。Llama 4 支持 200多种语言,并且是多模态的,这意味着它能够同时处理图像和文本。这种多模态能力对于翻译来说具有实际相关性:带有嵌入图像的文档、扫描的PDF文件以及带有文本标签的图表,Llama 4都可以以纯文本模型无法做到的方式进行处理。
Llama的显著特点在于您能用它做什么。由于模型权重在商业用途许可下公开可用,拥有适当基础设施的团队可以下载 Llama,在自己的服务器上运行它,在特定领域数据上进行微调,并处理敏感内容,而无需将任何内容发送到外部 API。对于数据驻留是合规性要求的法律、医疗和金融翻译工作流程,这不是可有可无的——它是唯一可接受的选择。
Llama 在标准内容上的翻译输出表现强劲,但并非业内顶尖。Intento 的 2025 年翻译自动化现状报告评估了 Llama 4 Maverick 和 Llama 4 Scout 在 11 种语言对中的表现,结果发现这两种模型在任何单一语言对评估中均未进入前 14 名解决方案之列。这是一个诚实的基准,可以说明:Llama 表现不错,但像 GPT-4.1、Claude Opus 4 和 Gemini 2.5 Pro 这样的模型在 Intento 评估的配对上胜过它。Llama 获得其地位在于它的开源灵活性、语言广度以及适用于高吞吐量工作流的成本结构。
Grok 与 Llama 对比:翻译质量比较
当 MachineTranslation.com 使用相同的 500 字英语到西班牙语营销文本测试 Grok 和 Llama 时,Grok 的质量得分为 10 分中的 8.1 分,Llama 得分为 7.9 分。对于同一段翻译成日文的文本,Grok 得分为 7.4,Llama 得分为 7.6——这是一个小小的逆转,反映了 Llama 4 在亚洲语言方面更强的多语言训练数据深度。两种模型在西班牙语文本上的一致性率为74%;在日语文本上,这一比例降至61%,这表明,特别是在日语方面,两种模型对源文本的很大一部分解释不同。
这一一致性数据值得我们深思。当 Grok 和 Llama 在翻译上达成一致时,你可以将这种趋同解读为一种置信信号——两个架构不同、在不同数据上训练的模型,却得出相同的结果。当它们出现分歧时,正如它们在该测试中39%的日语句子中表现的那样,这种分歧是一个信号:该段落要么包含真正的解释性歧义,要么其中一个模型做出了另一个模型不会做出的选择。
| Grok (Grok 4) | Llama (Llama 4 Maverick) | |
|---|---|---|
| 实时数据访问 | 是 | 否 |
| 可自托管 | 否 | 是 |
| 可微调 | 否 | 是 |
| 语言 | 40+ | 200+ |
| 多模态(图像/文档) | 有限 | 是 |
| API成本 | ~$0.20/百万输入令牌 | 免费(自托管) |
| 最佳内容类型 | 热门/社交/新闻 | 大批量、领域特定 |
| MachineTranslation.com 质量得分 (英-西) | 8.1/10 | 7.9/10 |
| MachineTranslation.com 质量得分 (英-日) | 7.4/10 | 7.6/10 |
没有一个模型占据主导地位。差异是真实存在的,但在标准内容上并不显著。用例决定了哪一个实际上更有用 — 对于大多数专业翻译工作流程来说,两者单独都不是正确的答案。
Llama 比 Grok 更适合翻译吗?
不能一概而论。答案几乎完全取决于内容类型和工作流程。
Grok 在原始材料具有时效性时具有优势。如果源文本中出现一个在最近几个月进入日常用语的短语(例如政治口号、文化迷因,或快速发展行业中新近创造的技术术语),Grok 的实时网络访问使其更有可能在目标语言中准确地呈现它。Llama 的训练数据有截止日期;Grok 则没有。
当优先考虑控制、成本或语言广度时,Llama 具有优势。对于在内部处理大量文档、在私有基础设施上运行经过微调的领域模型,或者使用Grok大约40种语言覆盖范围之外的语言进行工作的团队来说,Llama是更实用的工具。它的200多种语言支持和多模态能力使其在结构化企业工作流程中更具通用性。
对于主要语言对的标准内容的专业翻译质量而言,两者之间的差距很小,以至于其他因素(集成、成本、基础设施)比质量差距更重要。
哪一个更适合文档翻译?
在大多数情况下,Llama。
Llama 4 的多模态能力是处理复杂文档的决定性因素。嵌入图表的PDF文件、扫描合同、图像密集的演示文稿以及混合媒体文件,都需要一个能够同时处理视觉和文本信息的模型。Grok 的多模态能力在当前版本中更为有限,并且它并非为企业翻译所需的文档处理工作流而设计。
除了格式处理之外,自托管选项对于包含敏感内容的文档至关重要。一个翻译机密合并文件的法律团队不能将该文本发送到外部API。处理患者记录的医疗保健提供者需要本地部署的翻译。Llama 4 本地运行满足这两项要求。Grok,它独家通过 xAI 的云基础设施运行,则不会。
对于需要全文一致性的长文档,正如 MachineTranslation.com 的内部分析所示,以碎片形式处理的文档与作为整体处理的文档相比,术语不一致率高出 28%。Grok 和 Llama 作为大型语言模型,都能很好地处理完整文档的上下文,但对于非常长的文档(法律协议、年度报告、技术手册),通过 MachineTranslation.com 的 24 模型共识运行,可以捕捉到任何单一模型在处理 40,000 字文档时可能引入的偏差。
我可以在本地运行 Llama 进行翻译吗?
是的,对于某些特定用例,这正是正确的方法。
Meta 在商业使用许可下公开发布 Llama 模型权重。拥有运行大型AI模型基础设施的团队可以下载Llama 4 Maverick或Scout,并在本地完全运行它。这意味着没有数据发送到任何外部服务器,不会产生每令牌API成本,并且模型可以根据专有术语、客户特定词汇表或领域特定并行数据进行微调。
实际要求很高:Llama 4 Maverick 是一个大型模型,需要大量的计算资源。对于没有现有GPU基础设施的团队,自托管的经济性往往更倾向于使用云API。但对于已经在自己的硬件上运行AI工作负载的组织(企业技术、医疗保健系统、法律和金融机构)而言,自托管的Llama是能够同时满足合规性、成本和质量要求的翻译基础设施。
对于需要200多种语言多语言输出的团队,包括没有商业API能够可靠覆盖的罕见语言对,Llama的开放训练数据使其比任何封闭模型都更具适应性。
MachineTranslation.com 如何同时使用 Grok 和 Llama
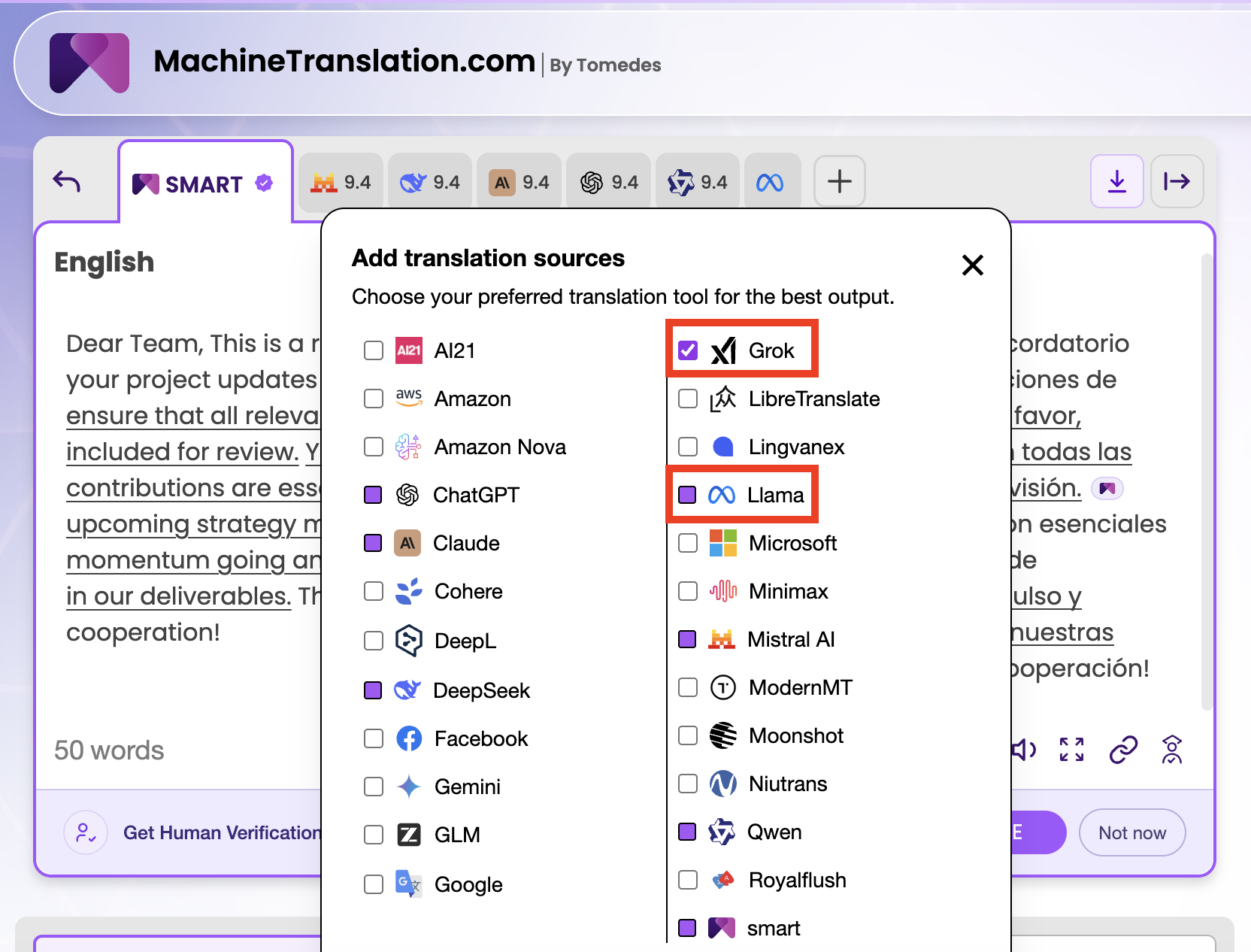
MachineTranslation.com 将 Grok 和 Llama 作为 SMART(该平台24模型共识系统)的一部分运行。当您翻译任何文本或文档时,两个模型都会产生独立的输出。SMART 随后比较所有 24 个输出,并呈现大多数模型达成一致的翻译,以及每个独立模型的质量分数。
实际结果是:您可以看到 Grok 生成了什么,Llama 生成了什么,以及 24 个模型的共识是什么。如果 Grok 和 Llama 在相同的英译西文本上分别得分为 8.1 和 7.9,并且 SMART 共识得分为 9.4,那么这个差距就说明了一些有意义的事情。共识输出整合了两个模型都正确的部分,同时过滤掉了每个模型独立引入的错误。
在MachineTranslation.com的内部测试中,SMART共识方法与仅依赖任何单一模型相比,将关键翻译错误风险降低了90%。在本文的具体比较中(Grok在英译西语上得分为8.1,Llama得分为7.9),SMART共识在同一文本上得分为9.4,其中Grok和Llama在74%的句子上达成一致,共识输出解决了剩余26%句子中的分歧。
Grok和Llama都不能被盲目信任。24 模型协议是重要的信号。
您可以在 MachineTranslation.com 直接比较 Grok 和 Llama 的输出,免费,无需注册。运行两者。看看他们在哪方面达成一致。看看他们分歧在哪里。差异之处在于翻译实际上很难。
常见问题
1.Llama 在翻译方面比 Grok 更好吗?
并非普遍如此。Grok 在处理涉及近期事件、流行语言和当前文化参考等具有时效性的内容时,表现优于 Llama,这是因为 Grok 拥有实时网络访问能力,能够获取 Llama 的静态训练数据所无法比拟的上下文信息。Llama 在大批量文档工作流、必须保留在本地的合规敏感内容以及超出 Grok 大约 40 种语言覆盖范围的语言对方面,表现优于 Grok。在主要语言对的标准内容上,它们之间的质量差距很小。
2.Grok 在翻译方面与其他 AI 模型有何不同?
Grok 的主要区别在于实时数据访问。虽然大多数 AI 模型(包括 Llama)都是在具有知识截止点的固定数据集上训练的,但 Grok 可以在推理过程中从实时网络内容和 X 平台数据中获取信息。对于涉及新近创造的术语、流行文化参考或有关时事的内容的翻译,这赋予 Grok 静态模型无法复制的事实准确性优势。
3.Llama 4 在翻译方面比 Grok 更好吗?
Llama 4 Maverick 和 Llama 4 Scout 支持 200 多种语言,而 Grok 大约支持 40 种语言,并且 Llama 4 的多模态能力可以处理嵌入图像的文档和扫描的 PDF,而 Grok 无法有效处理这些内容。对于 Intento 评估的主要语言对的原始翻译质量,两种模型均未进入前14名解决方案——两者都有能力,但并非业界领先。Llama 4 的实际优势在于它的广度、它的开源灵活性以及它的自托管选项。
4.Llama 可以用于翻译吗?
是的。当前一代的 Llama 4 Maverick 和 Llama 4 Scout 支持200多种语言,并且在主要语言对上的翻译输出可与其它前沿大型语言模型相媲美。Llama 可以通过 API 使用,也可以在私有基础设施上自行托管,这使得它对于具有数据隐私或合规性要求的组织特别相关。它还可以在特定领域数据上进行微调,以提高在专业内容上的性能。
5.哪种更适合多语言内容:Grok 还是 Llama?
Llama,在语言广度上明显胜出。Llama 4 支持 200多种语言;Grok 支持大约40种。对于处理各种语言对(特别是非洲、南亚或土著语言)的团队来说,Llama 的训练数据覆盖范围要广泛得多。对于主要的欧洲和东亚语言对,两种模型表现相当。
6.MachineTranslation.com 如何同时使用 Grok 和 Llama?
Grok 和 Llama 都作为 MachineTranslation.com 的 SMART 24 模型共识系统的一部分同时运行。每次翻译都会独立地经过所有24个模型。SMART 识别多数人认同的输出,并将其作为结果交付,同时提供每个模型的质量分数。用户可以看到 Grok 的独立输出、Llama 的独立输出,以及综合了所有 24 个模型达成一致意见的共识翻译。