June 10, 2026
GPT-4.1 vs DeepSeek V3: Precisió, al·lucinació i rendiment de la traducció comparats
La pregunta que la majoria dels equips de traducció es fan en silenci a mitjans de 2026 no és hauríem d'utilitzar IA?, aquesta decisió ja s'ha pres. La veritable pregunta és en quin model d'IA estandarditzar, i si la resposta és la mateixa per a cada parell d'idiomes, cada tipus de document i cada pressupost.
GPT-4.1 i DeepSeek V3 han sorgit com les dues opcions avaluades amb més freqüència per als fluxos de treball de traducció professional. Representen filosofies genuïnament diferents: una és una API d'OpenAI polida comercialment i estrictament governada; l'altra és un model de pes obert amb llicència MIT d'un laboratori de recerca xinès que va superar discretament diversos competidors propietaris en els punts de referència WMT24. Cap dels dos és universalment millor. El cas de cadascun depèn del que estiguis traduint, per a qui i sota quines restriccions.
Aquest article desglossa tots dos models segons les dimensions que més importen als traductors, als gestors de localització i als compradors empresarials: precisió en parells d'idiomes reals, comportament d'al·lucinació, gestió de tasques restringides com l'adhesió al glossari i el cost total d'execució de qualsevol a escala.
Taula de continguts
- Per què aquesta comparació és important ara mateix
- Què és realment cada model
- Cara a cara: Precisió de la traducció i rendiment de referència
- Quin model al·lucina més, i quan?
- Quin model gestiona millor la traducció restringida?
- Cost i desplegament: Quins canvis hi ha a gran escala
- Com provar ambdós models sense comprometent-se amb cap
- Quin model heu de triar per al vostre flux de treball de traducció?
- Preguntes freqüents
- Comparacions relacionades
Per què aquesta comparació és important ara mateix
Els compradors de traduccions han avaluat històricament la traducció automàtica en un eix estret: Puntuació BLEU versus preu. Els LLM trenquen aquest marc completament. GPT-4.1 i DeepSeek V3 no són motors de traducció automàtica (TA) en el sentit tradicional: són models d'ús general amb fortes capacitats multilingües, i el seu rendiment en tasques de traducció varia segons l'arquitectura, les dades d'entrenament i la manera com els demaneu.
Aquesta variabilitat és el nucli del problema d'avaluació. Un gestor de localització que prova tots dos models en textos de màrqueting d'anglès a espanyol pot veure una qualitat de sortida gairebé idèntica. El mateix gestor que prova documents legals àrab→anglès probablement veurà una bretxa significativa, però quin model surt guanyant depèn de si el document conté entitats anomenades, argot tècnic o referències culturals que requereixen coneixements del món en lloc de coincidència de patrons.
Les apostes també són asimètriques. DeepSeek V3 és molt més barat d'executar, especialment autoallotjat. GPT-4.1 comporta un cost addicional significatiu. Si tots dos models ofereixen una qualitat acceptable en el vostre flux de treball específic, la diferència de cost pot determinar si un flux de treball de traducció d'IA és econòmicament viable a gran escala.
Què és realment cada model
GPT-4.1: El vaixell insígnia d'OpenAI ajustat a instruccions
Publicat a l'abril de 2025, GPT-4.1 és el model d'OpenAI que s'adhereix més a les instruccions fins ara. Les seves millores principals respecte a GPT-4o no són la fluïdesa de traducció bruta (ja era fort en això), sinó la precisió a seguir instruccions complexes i multipartides. Per als fluxos de treball de traducció, això és especialment important en tasques restringides: aplicar un glossari del client, preservar el format del document en textos llargs, mantenir un registre específic o adherir-se a una llista de no traduir.
GPT-4.1 admet una finestra de context d'un milió de tokens, cosa que significa que pot processar documents de la llargada d'un llibre en una sola trucada. En tasques de sortida estructurada (generació de memòries de traducció en JSON, producció de puntuacions de qualitat a nivell de segment juntament amb la traducció, formatació de taules bilingües), és demostrablement més fiable que els seus predecessors. La contrapartida és el cost: GPT-4.1 se situa en una categoria de preu superior a la majoria d'alternatives, inclòs DeepSeek V3.
DeepSeek V3: El desafiant de codi obert
DeepSeek V3 (la versió de producció actual és DeepSeek-V3-0324) és un model de 685 mil milions de paràmetres construït sobre una arquitectura Mixture-of-Experts, el que significa que només un subconjunt dels seus paràmetres s'activa per a qualsevol entrada donada, cosa que manté els costos d'inferència baixos malgrat l'enorme nombre total de paràmetres. Es publica sota la llicència MIT, cosa que significa que les organitzacions poden allotjar-lo elles mateixes, ajustar-lo i desplegar-lo comercialment sense tarifes per token a un tercer.
El rendiment de traducció del model va atreure una atenció significativa després del WMT24, on va obtenir puntuacions fortes de BLEU i COMET en parells de llengües xinès↔anglès, àrab i coreà, superant en diversos casos GPT-4o. Per a equips que treballen intensament amb parelles d'idiomes asiàtics o de l'Orient Mitjà, DeepSeek V3 no és una elecció de compromís. És genuïnament competitiu a una fracció del cost.
Cara a cara: Precisió de la traducció i rendiment de referència Dimensió GPT-4.1 DeepSeek
| V3 Finestra de | context 1.000.000 | de tokens ~64.000 |
|---|---|---|
| tokens (estàndard) Arquitectura Transformer | dens Mestratge d'experts | (685 mil milions de paràmetres) Llicència Propietari Codi |
| obert (MIT) Auto-allotjament No | disponible Disponible WMT24 | Xinès↔Anglès Fort Molt fort, va superar GPT-4o |
| en diversos | parells Traducció | àrab WMT24 Competitiu Fort, |
| especialment en | text especialitzat Seguiment | d'instruccions El |
| millor de la seva categoria | enfront | de GPT-4o Bo; menys consistent en indicacions complexes |
| de diversos passos Sortida | estructurada Molt | fiable Fiable; lleuger canvi de format en |
| sortides llargues Tendència | a l'al·lucinació Reduït | enfront de GPT-4o Ocasional en parells de baixos recursos Cost |
| relatiu de l'API Més | alt Significativament | més baix Sobre la precisió general de la |
| traducció per a parells | d'idiomes d'alts | recursos (anglès, francès, |
| espanyol, alemany, | xinès, | japonès), tots |
dos models ofereixen un nivell que els traductors professionals descriuen com a llest per a la post-edició. La diferència entre ells en fluïdesa i adequació per si sola no és prou gran per impulsar una decisió de compra per a la majoria dels equips.
Les diferències significatives sorgeixen en tres escenaris específics: llengües de baixos recursos, tasques restringides i tipus de documents propensos a la al·lucinació.
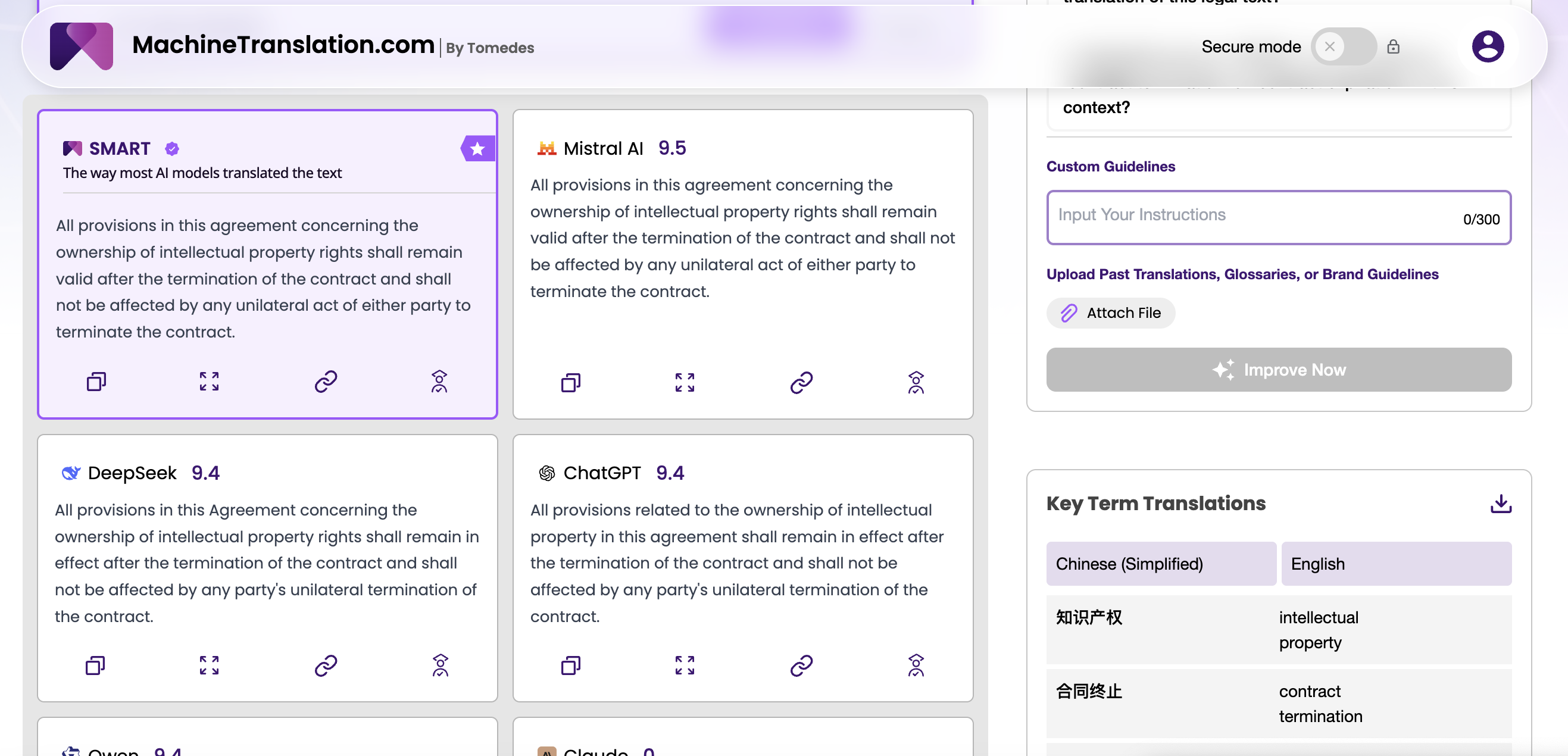
Quin model al·lucina més i quan?
La al·lucinació en la traducció no és el mateix que la al·lucinació en la generació d'ús general. El model treballa a partir d'un text font, no s'inventa fets del no-res. L'al·lucinació aquí es manifesta com a contingut afegit que no es troba a la font, clàusules omeses o entitats anomenades substituïdes. En una traducció legal o mèdica, qualsevol d'aquests errors pot tenir conseqüències greus.
GPT-4.1 mostra una taxa d'al·lucinació mesurablement inferior a GPT-4o, especialment en documents llargs on els models anteriors d'OpenAI començaven a desviar-se de la font en segments posteriors. La combinació d'una finestra de context d'un milió de tokens i una millora en el seguiment d'instruccions significa que GPT-4.1 manté la fidelitat a la font durant més temps sense necessitat d'estratègies especials de prompt. Per als compradors empresarials que processen presentacions reguladores, documentació de productes o contractes, aquesta és una millora significativa de la fiabilitat.
El perfil d'al·lucinació de DeepSeek V3 és diferent en caràcter. En parelles d'idiomes ben suportades (xinès, anglès, àrab), generalment és fiable. El risc augmenta en parelles de baixos recursos: Coreà→Swahili, Àrab→Vietnamita, o qualsevol parella on una llengua estigui subrepresentada en el corpus d'entrenament. En aquests casos, s'ha observat que DeepSeek V3 genera contingut plausible però no admès per la font, especialment quan la font conté entitats anomenades ambigües o terminologia específica del domini.
La implicació pràctica: si la vostra cartera de parelles lingüístiques es concentra en llengües d'alts recursos, el risc d'al·lucinació de DeepSeek V3 és gestionable amb processos estàndard de QA. Si esteu executant traduccions a gran escala en parells de baixos recursos, la fiabilitat addicional de GPT-4.1 pot justificar el cost addicional.
💬 El que veiem constantment a la plataforma és que la diferència entre GPT-4.1 i DeepSeek V3 en la fabricació de mentides no es tracta del volum, sinó d'on passa. En contingut anglès, francès o espanyol, la majoria de traductors professionals no notarien una diferència significativa en fiabilitat. Els problemes amb DeepSeek V3 tendeixen a aparèixer en documents coreans o àrabs que contenen noms propis desconeguts o terminologia molt específica del domini. GPT-4.1 gestiona aquests casos extrems de manera més conservadora, és menys probable que ompli un buit amb alguna cosa que soni plausible.
— Lingüista a MachineTranslation.com
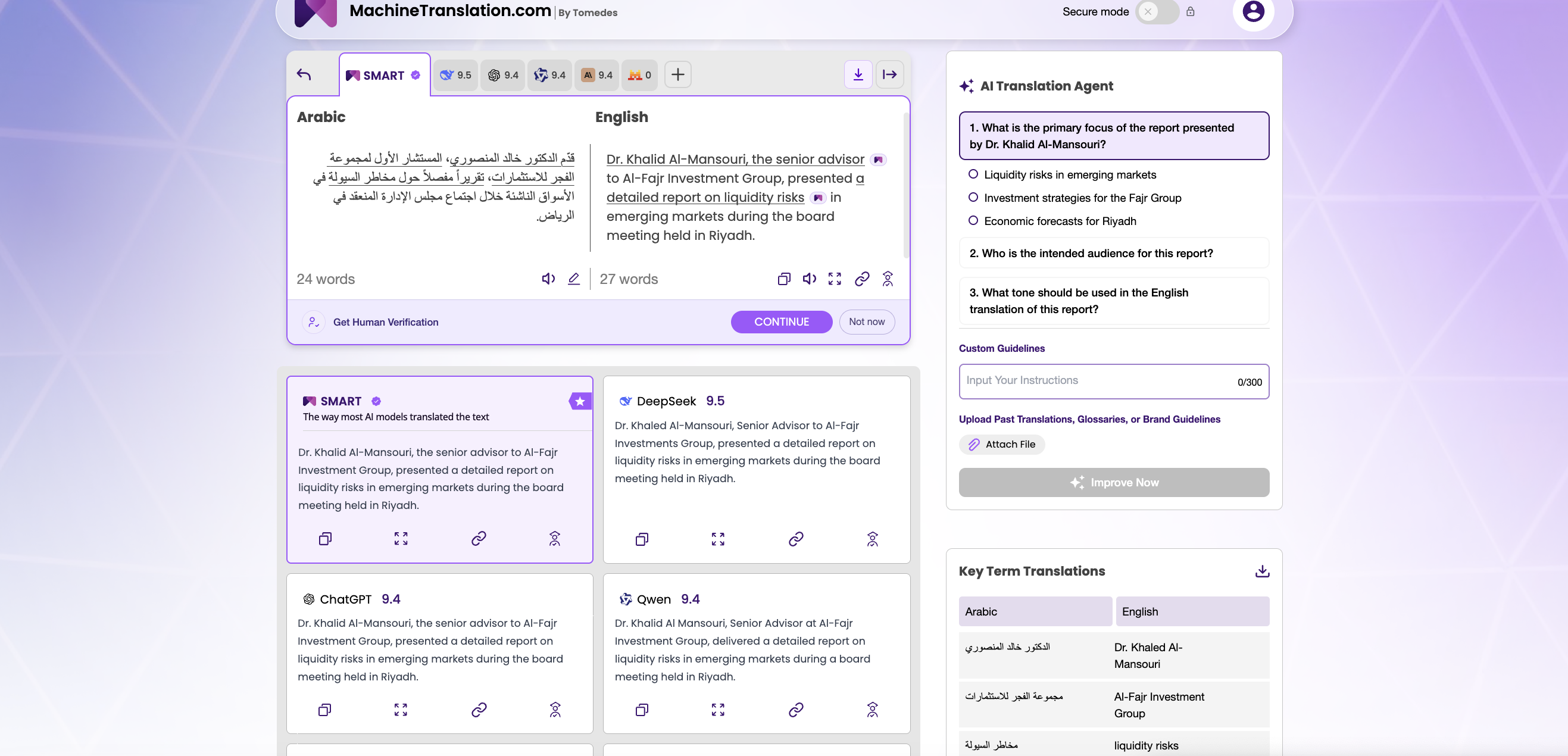
Quin model gestiona millor la traducció restringida?
La traducció restringida (on el model ha de respectar un glossari, mantenir un registre de marca, evitar traduir certs termes o preservar l'estructura del document com capçaleres i notes a peu de pàgina) és on els avantatges arquitectònics de GPT-4.1 es tornen més tangibles.
Quan proporciones un prompt de sistema amb un glossari de 200 termes i instrueixes al model que assenyali qualsevol segment d'origen on no es pugui trobar una concordança exacta, GPT-4.1 segueix aquestes instruccions amb una consistència que els models anteriors no podien mantenir més enllà d'uns pocs centenars de tokens. En una finestra de context d'un milió de tokens, això significa que podeu traduir un manual tècnic de 400 pàgines amb una restricció de terminologia complexa en una sola trucada i esperar una aplicació coherent del glossari al llarg de tot el document.
DeepSeek V3 gestiona adequadament les restriccions senzilles: instruccions de no traduir termes únics, preferències bàsiques de registre, regles de format simples. On s'hi queda curt és en conjunts d'instruccions complexos i compostos. A mesura que augmenta el nombre de restriccions simultànies, DeepSeek V3 comença a prioritzar algunes instruccions sobre altres de maneres difícils de predir sense provar. Per als equips de localització que gestionen guies d'estil de diversos nivells i grans memòries de traducció, aquesta inconsistència crea una sobrecàrrega de QA posterior que compensa parcialment l'avantatge de cost del model.
Per a la traducció pura i sense restriccions de contingut estàndard (comunicacions generals de negocis, textos de màrqueting, descripcions de productes de comerç electrònic), la bretxa de gestió de restriccions entre els dos models és en gran part irrellevant. La diferència és més important per als equips que executen fluxos de treball de nivell empresarial, on la traducció és un pas en un procés de localització de diverses etapes.
💬 Vam executar tots dos models contra el mateix glossari en un conjunt de documents legals, unes 120.000 paraules en vuit parells d'idiomes. GPT-4.1 va respectar les restriccions terminològiques gairebé perfectament. DeepSeek V3 estava perto, mas ocasionalmente substituía um termo preferido por um sinônimo próximo que nossos clientes nos haviam pedido especificamente para evitar. Amb aquest volum, gairebé no és suficient. Per contingut no restringit, utilitzem DeepSeek V3 i els estalvis de costos són significatius. Per a qualsevol cosa amb un glossari aprovat pel client, encara estem executant GPT-4.1.
— Gerent de localització a MachineTranslation.com
Cost i desplegament: Quins canvis a escala
El cost és on els dos models divergeixen més bruscament, i on l'avaluació ha de tenir en compte més que el preu per token.
GPT-4.1 té un preu de nivell premium. Per a les organitzacions que processen milions de paraules al mes a través de l'API d'OpenAI, aquest cost s'acumula ràpidament. El model no està disponible per a auto-allotjament, cosa que significa que cada testimoni comporta una tarifa d'API que no es pot reduir mitjançant inversió en infraestructura.
El perfil de costos de DeepSeek V3 és fonamentalment diferent. Via l'API DeepSeek, és significativament més barat per testimoni que GPT-4.1. Auto-allotjat, l'economia canvia encara més: les organitzacions amb infraestructura de GPU poden executar DeepSeek V3 a un cost determinat principalment per la computació en lloc de llicències per testimoni. Per a operacions de traducció d'alt volum (catàlegs de comerç electrònic globals, fluxos de contingut multilingüe, processament de documents normatius), la diferència pot representar centenars de milers de dòlars anualment a escala empresarial.
La llicència de codi obert de DeepSeek V3 també és important per als sectors sensibles a les dades. Les organitzacions legals, financeres i sanitàries que no poden enviar documents de clients a API externes poden desplegar DeepSeek V3 a les seves instal·lacions. GPT-4.1 no ofereix cap opció equivalent.
La regla de decisió és relativament clara: si la vostra càrrega de treball és d'alt volum, les vostres parelles de llenguatge estan ben suportades i les vostres polítiques de governança de dades permeten serveis d'API o desplegament local, DeepSeek V3 ofereix una qualitat competitiva a un cost materialment inferior. Si la vostra càrrega de treball implica traducció restringida, fidelitat de documents llargs o parells de llengües de baixos recursos, la fiabilitat de GPT-4.1 pot valdre la pena el preu.
Com provar ambdós models sense comprometís amb cap d'ells
L'obstacle pràctic per a la selecció de models per a la majoria dels equips de localització no és entendre els punts de referència, sinó la fricció de configurar integracions API independents amb ambdós models, dissenyar condicions de prova comparables i realitzar una avaluació significativa del vostre propi contingut.
MachineTranslation.com elimina aquest obstacle. La plataforma executa GPT-4.1 i DeepSeek V3 de forma paral·lela, donant als traductors professionals i als gestors de localització la possibilitat de presentar el mateix text d'origen a tots dos models simultàniament i comparar els resultats en temps real, sense una clau API separada, sense un procés de contractació i sense comprometre's amb cap dels dos models.
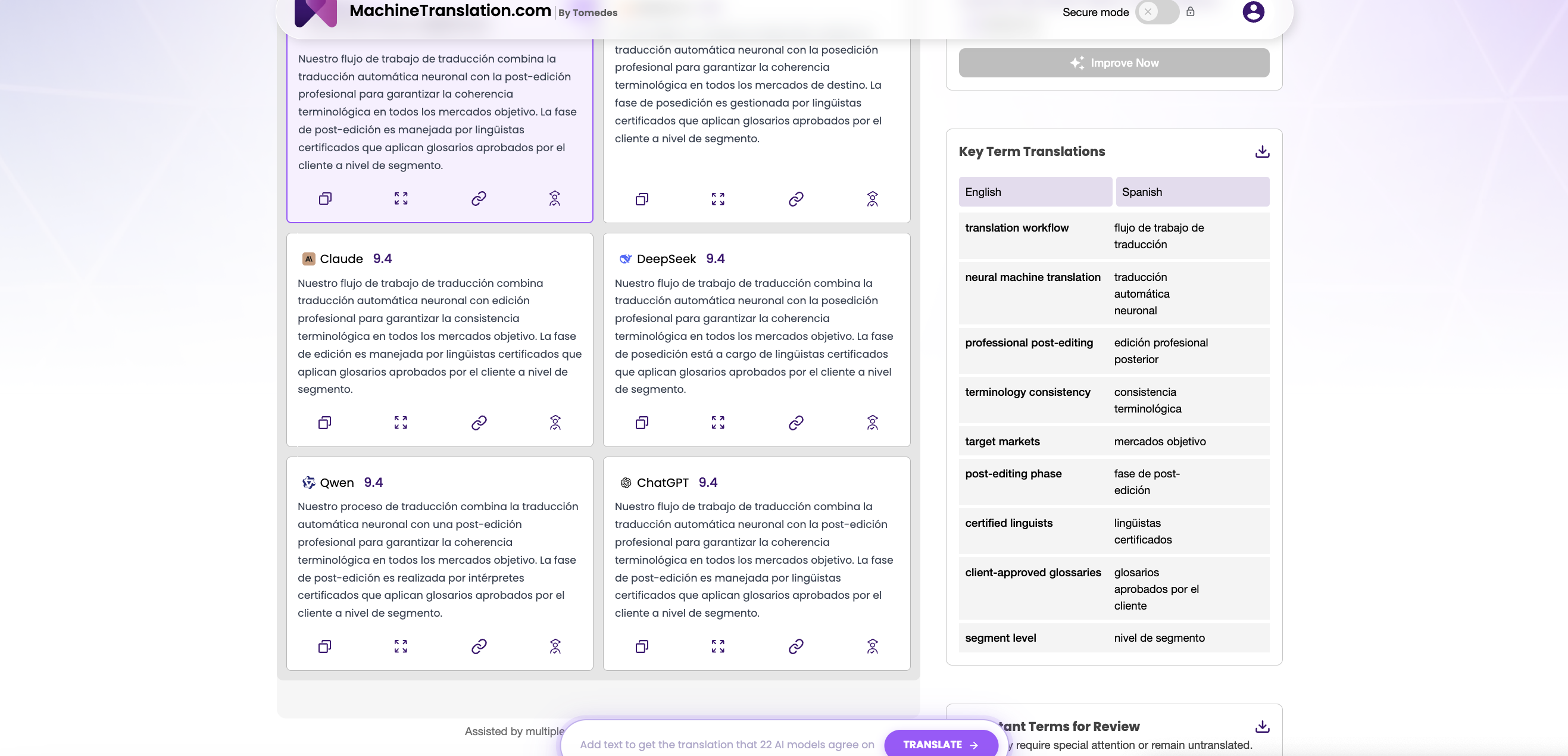
Això és important perquè el rendiment de referència a nivell de conjunt de dades no sempre prediu el rendiment del vostre contingut específic. Un model que obté puntuacions COMET fortes en notícies xineses→angleses del WMT24 pot tenir un rendiment inferior en la terminologia o domini específic de la vostra empresa. L'única avaluació que és rellevant per a la presa de decisions és una realitzada sobre els vostres propis documents, amb les vostres pròpies restriccions, en els vostres propis parells d'idiomes.
La postura de MachineTranslation.com com a plataforma neutral multimodèl significa que no té cap incentiu comercial per afavorir ni GPT-4.1 ni DeepSeek V3. El paper de la plataforma és proporcionar-vos les dades de comparació perquè prengueu aquesta decisió vosaltres mateixos, i després executar el model que seleccioneu a escala de producció un cop finalitzada l'avaluació. Tot i que, per descomptat, també us proporciona la traducció que la majoria dels models d'IA coincideixen com la millor traducció per defecte.
Per als equips que també avaluïn en el nivell de models d'OpenAI, com GPT-4.1 es compara amb altres models d'OpenAI (incloent GPT-4.5 i GPT-4o) proporciona un context útil abans de comprometre's amb una versió del model. I per als equips que van avaluar com DeepSeek V3 es compara amb GPT-4o a principis del 2025, aquest article cobreix què ha canviat amb el llançament de GPT-4.1.
Quin model heu de triar per al vostre flux de treball de traducció?
En lloc d'una única recomanació, el següent marc reflecteix la lògica de decisió que la majoria dels equips de traducció professionals trobaran útil:
-
Comenceu amb els vostres parells de llengües. Si la vostra cartera està concentrada en xinès↔anglès, àrab o coreà, el rendiment de DeepSeek V3 a WMT24 el converteix en la primera prova natural. Si esteu treballant principalment en llengües europees amb terminologia restringida, GPT-4.1 és probable que produeixi resultats més coherents des del primer dia.
-
Avalua la complexitat de les teves restriccions. Els vincles de nivell únic (un glossari, un registre) són gestionats adequadament per qualsevol dels dos models. Restriccions de diversos nivells (glossari + format + llista de no traduir + puntuació QA), GPT-4.1 és més fiable actualment.
-
Avalueu el vostre volum en relació amb la diferència de costos. Sota les 500.000 paraules al mes, la diferència absoluta del cost de l'API pot no afectar materialment el vostre pressupost. Més enllà d'aquest llindar, l'avantatge de cost de DeepSeek V3 és cada cop més difícil d'ignorar.
-
Tingues en compte els teus requisits de governança de dades. Si els documents no poden sortir de la vostra infraestructura, DeepSeek V3 autoallotjat és actualment l'única opció viable de les dues.
-
Executeu l'avaluació al vostre contingut, no als punts de referència. Utilitza MachineTranslation.com per enviar mostres representatives de la teva càrrega de treball real a ambdós models i avalua els resultats segons els teus propis criteris de qualitat abans de comprometre't.
Per a una visió més àmplia d'on es troben aquests models en el panorama actual de la traducció automàtica, les millors eines de traducció automàtica del 2026 cobreixen tot el camp competitiu, incloent com els LLM es comparen amb la infraestructura de traducció dissenyada específicament.
Preguntes freqüents
1. És GPT-4.1 millor que DeepSeek V3 per a la traducció?
Cap dels dos models és universalment millor. GPT-4.1 supera DeepSeek V3 en tasques de traducció restringides, fidelitat de documents llargs i parells de llengües de baixos recursos on el risc d'al·lucinació és més alt. DeepSeek V3 iguala o supera a GPT-4.1 en varios puntos de referencia de WMT24 (particularmente xinès↔anglès, àrab i coreà) i és significativament més barat d'executar a gran escala o autoallotjat.
2. DeepSeek V3 al·lucina més que GPT-4.1?
En parells d'idiomes amb molts recursos, la diferència d'al·lucinació és relativament petita. La bretxa s'amplia en parells de baixos recursos i contingut específic del domini amb entitats anomenades rares, on DeepSeek V3 ha mostrat taxes més altes d'addicions o substitucions no compatibles amb la font. GPT-4.1 demostra una reducció de les al·lucinacions en comparació amb GPT-4o, especialment en documents més llargs.
3. Puc utilitzar DeepSeek V3 comercialment?
Sí. DeepSeek V3 es llança sota la llicència MIT, que permet l'ús comercial, incloent-hi el *fine-tuning* i l'*self-hosting*. Les organitzacions que no poden enviar documents a API externes poden desplegar DeepSeek V3 a la seva pròpia infraestructura. GPT-4.1 requereix l'ús de l'API d'OpenAI segons els termes del servei d'OpenAI i no està disponible per a auto-allotjament.
4. Quin model és millor per a la traducció de xinès a anglès?
DeepSeek V3 té un avantatge en xinès↔anglès basant-se en els resultats del benchmark WMT24. Tanmateix, per a la traducció de xinès a anglès que implica terminologia restringida, precisió legal o format complex, la capacitat de seguir instruccions de GPT-4.1 el fa més fiable en fluxos de treball de producció on un traductor humà post-editarà la sortida.
5. Puc provar GPT-4.1 i DeepSeek V3 de forma comparada abans de triar?
Sí — MachineTranslation.com executa tots dos models simultàniament (i més de 20) i et permet comparar els resultats amb el teu propi contingut en temps real, sense comptes d'API separats ni un procés de contractació.
6. Com es compara DeepSeek V3 amb Claude per a la traducció?
Per als equips que també estan avaluant el model d'Anthropic, la comparació Claude vs DeepSeek V3 cobreix les diferències clau en arquitectura, precisió i opcions de desplegament en escenaris rellevants per a la traducció.