June 10, 2026
GPT-4.1 vs DeepSeek V3: Tarkkuus, hallusinointi ja käännöksen suorituskyky verrattuna
Kysymys, jota useimmat käännöstiimit hiljaa pohtivat vuoden 2026 puolivälissä, ei ole pitäisikö meidän käyttää tekoälyä?, se päätös on jo tehty. Todellinen kysymys on, mihin tekoälymalliin standardisoidaan ja onko vastaus sama jokaiselle kieliparille, jokaiselle asiakirjatyypille ja jokaiselle budjetille.
GPT-4.1 ja DeepSeek V3 ovat nousseet kahdeksi useimmin arvioiduksi vaihtoehdoksi ammattimaisissa käännöstyönkuluissa. Ne edustavat todella erilaisia filosofioita: toinen on tiukasti hallittu, kaupallisesti hiottu API OpenAI:lta; toinen on avoimen painon, MIT-lisensoitu malli kiinalaiselta tutkimuslaboratoriolta, joka hiljaa päihitti useita omia kilpailijoita WMT24-vertailuarvoissa. Kumpikaan ei ole yleisesti parempi. Tapaus kunkin riippuu siitä, mitä käännät, kenelle ja millaisissa rajoituksissa.
Tämä artikkeli erittelee molemmat mallit ulottuvuuksien mukaan, jotka ovat tärkeimpiä kääntäjille, lokalisointipäälliköille ja yritysostajille: tarkkuus todellisissa kielipareissa, hallusinointikäyttäytyminen, rajoitettujen tehtävien, kuten sanaston noudattamisen, käsittely ja molempien skaalautuvan käytön kokonaiskustannukset.
Sisällysluettelo
- Miksi tämä vertailu on tärkeä juuri nyt
- Mitä kumpikin malli todella on
- Head-to-head: Käännöksen tarkkuus ja vertailusuorituskyky
- Mikä malli hallusinoi enemmän ja milloin?
- Mikä malli käsittelee rajoitettua käännöstä paremmin?
- Kustannukset ja käyttöönotto: Mitä muutoksia skaalautuu
- Kuinka testata molempia malleja sitoutumatta kumpaankaan
- Minkä mallin valitset käännöstyönkulkuusi?
- Usein kysytyt kysymykset
- Aiheeseen liittyvät vertailut
Miksi tämä vertailu on tärkeä juuri nyt
Käännösten ostajat ovat historiallisesti arvioineet konekäännöstä kapealla akselilla: BLEU-pistemäärä verrattuna hintaan. LLM:t rikkovat tuon kehyksen kokonaan. GPT-4.1 ja DeepSeek V3 eivät ole perinteisessä mielessä konekäännösmoottoreita (MT) – ne ovat yleiskäyttöisiä malleja, joilla on vahvat monikieliset ominaisuudet, ja niiden suorituskyky käännöstehtävissä vaihtelee arkkitehtuurin, koulutusdatan ja kehotustavan mukaan.
Tämä vaihtelu on arviointiongelman ydin. Paikannuspäällikkö, joka testaa molempia malleja englanti→espanja-markkinointiteksteillä, saattaa nähdä lähes identtisen laadun. Sama johtaja, joka testaa arabia→englanti -kielisiä oikeudellisia asiakirjoja, todennäköisesti havaitsee merkittävän eron – mutta kumpi malli on parempi, riippuu siitä, sisältääkö asiakirja nimettyjä entiteettejä, teknistä jargonia tai kulttuurisia viittauksia, jotka vaativat maailmantietoa pelkän mallintunnistuksen sijaan.
Panokset ovat myös epäsymmetriset. DeepSeek V3 on huomattavasti halvempaa ajaa, erityisesti itse isännöitynä. GPT-4.1:llä on merkittävä lisäkustannus. Jos molemmat mallit tuottavat hyväksyttävää laatua omassa työkuormassasi, kustannusero voi määrittää, onko tekoälykäännöstyönkulku taloudellisesti kannattava laajassa mittakaavassa.
Mitä kukin malli todella on
GPT-4.1: OpenAI:n ohjeisiin mukautettu lippulaiva
Huhtikuussa 2025 julkaistu GPT-4.1 on OpenAI:n tähän mennessä parhaiten ohjeita noudattava malli. Sen otsikon parannukset GPT-4o:hon verrattuna eivät ole raakaa käännöstaitoa (siinä se oli jo vahva), vaan tarkkuutta monimutkaisten, moniosaisen ohjeiden noudattamisessa. Käännöstyönkuluissa tämä on erityisen tärkeää rajoitetuissa tehtävissä: asiakassanakirjan soveltaminen, asiakirjan muotoilun säilyttäminen pitkissä teksteissä, tietyn rekisterin ylläpitäminen tai käännös kiellettyjen sanojen luettelon noudattaminen.
GPT-4.1 tukee miljoonan tokenin konteksti-ikkunaa, mikä tarkoittaa, että se voi käsitellä kirjan mittaisia asiakirjoja yhdellä kutsulla. Strukturoiduissa tulostustehtävissä (käännöspohjien luominen JSON-muodossa, segmenttikohtaisten laatupisteiden tuottaminen käännöksen rinnalla, kaksikielisten taulukoiden muotoilu) se on osoittautunut luotettavammaksi kuin edeltäjänsä. Kustannus on kompromissi: GPT-4.1 on kalliimmassa hintaluokassa kuin useimmat vaihtoehdot, mukaan lukien DeepSeek V3.
DeepSeek V3: Avoimen lähdekoodin haastaja
DeepSeek V3 (nykyinen tuotantoversio on DeepSeek-V3-0324) on 685 miljardin parametrin malli, joka perustuu Mixture-of-Experts-arkkitehtuuriin — mikä tarkoittaa, että vain osa sen parametreista aktivoituu kullekin syötteelle, mikä pitää päättelykustannukset alhaisina valtavasta kokonaisparametrimäärästä huolimatta. Se julkaistaan MIT-lisenssillä, mikä tarkoittaa, että organisaatiot voivat itse isännöidä sitä, hienosäätää sitä ja ottaa sen kaupallisesti käyttöön ilman kolmannelle osapuolelle maksettavia token-kohtaisia maksuja.
Mallin käännöskyky herätti merkittävää huomiota WMT24-kilpailun jälkeen, jossa se saavutti vahvat BLEU- ja COMET-pisteet kiina↔englanti, arabia ja korea kielipareilla – useissa tapauksissa se suoriutui paremmin kuin GPT-4o. Tiimeille, jotka työskentelevät paljon aasialaisissa tai Lähi-idän kielipareissa, DeepSeek V3 ei ole kompromissivalinta. Se on todella kilpailukykyinen murto-osalla kustannuksista.
Suoraan verrattuna: Käännöksen tarkkuus ja vertailusuorituskyky Dimension GPT-4.1 DeepSeek V3 Konteksti-ikkuna 1
| 000 000 tokenia ~64 | 000 tokenia | (standardi) Arkkitehtuuri Tiivis |
|---|---|---|
| muuntaja Mixture-of-Experts | (685B parametria) Lisenssi Oma Avoin | lähdekoodi (MIT) Itsenäinen isännöinti Ei |
| saatavilla Saatavilla WMT24 | Kiina↔Englanti Vahva Erittäin | vahva, päihitti GPT-4o:n useissa pareissa WMT24 |
| Arabialainen | käännös Kilpailukykyinen Vahva, | erityisesti erikoistuneessa |
| tekstissä Ohjeiden | noudattaminen Luokkansa | paras verrattuna |
| GPT-4o:hon Hyvä; epäjohdonmukaisempi | monimutkaisissa | monivaiheisissa kehotteissa Jäsennelty tuloste Erittäin |
| luotettava Luotettava; pieni | muotoilun ajautuminen | pitkissä tulosteissa Hallusinaatiotaipumus Vähentynyt |
| verrattuna GPT-4o:hon Satunnainen | vähäresurssisissa | pareissa Suhteellinen API-kustannus Korkeampi Merkittävästi |
| alhaisempi Yleisen | käännöstarkkuuden | osalta korkean resurssin kielipareissa |
| (englanti, ranska, | espanja, | saksa, kiina, japani), |
| molemmat | mallit | suoriutuvat |
tasolla, jota ammattikääntäjät kuvaavat jälkieditoitavaksi. Niiden välinen ero sujuvuudessa ja riittävyydessä ei yksinään ole riittävän suuri useimpien tiimien ostopäätöksen ajamiseksi.
Merkitykselliset erot ilmenevät kolmessa erityistilanteessa: vähäresurssiset kielet, rajoitetut tehtävät ja hallusinaatioille alttiit dokumenttityypit.
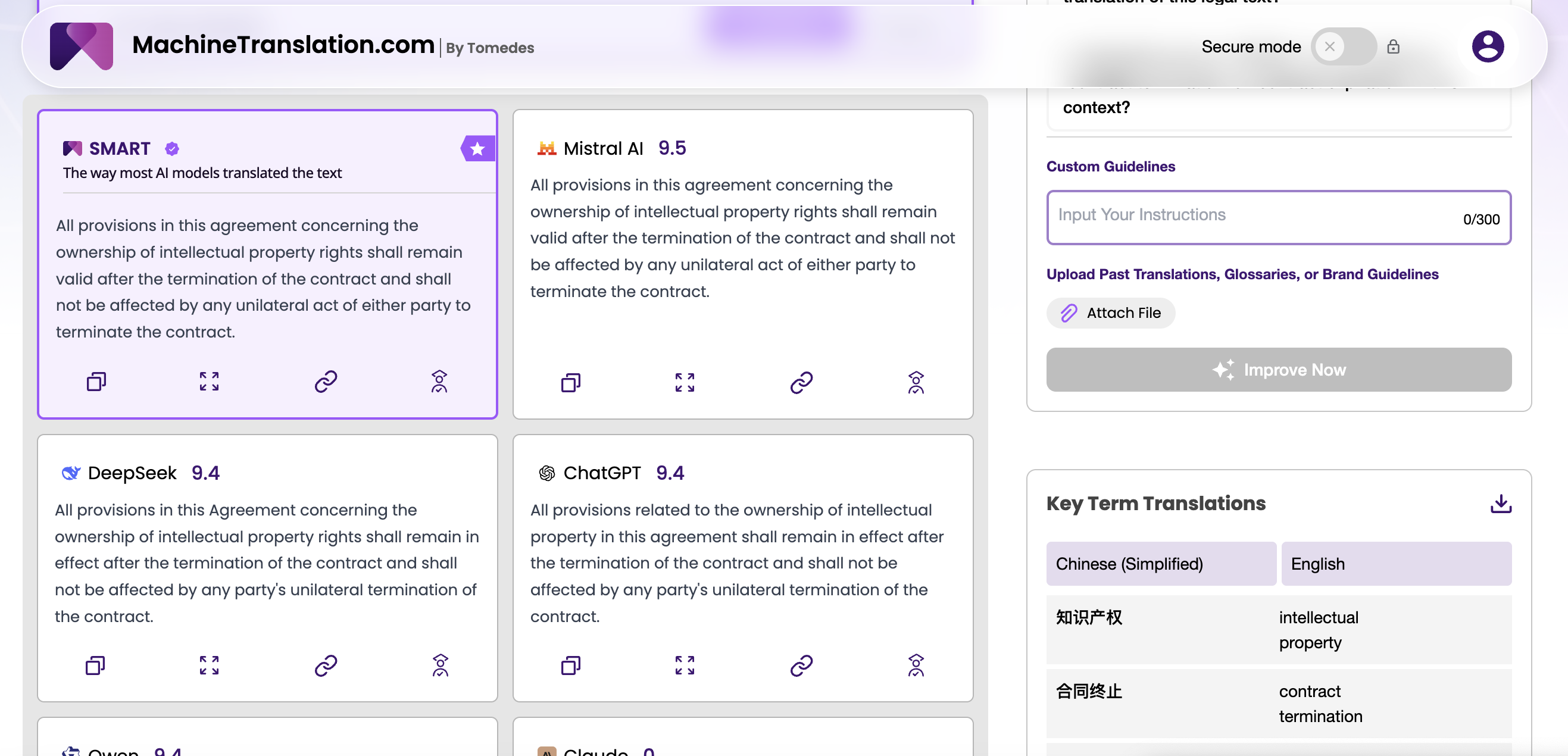
Kumpi malli hallusinoi enemmän ja milloin?
Käännöksen hallusinaatio ei ole sama asia kuin yleiskäyttöisen generoinnin hallusinaatio. Malli toimii lähdetekstin perusteella, se ei keksi faktoja tyhjästä. Hallusinaatio ilmenee tässä lisättynä sisältönä, jota ei ole lähteessä, pois jätettyinä lausekkeina tai korvattuina nimettyinä entiteetteinä. Laillisessa tai lääketieteellisessä käännöksessä mikä tahansa näistä virheistä voi johtaa vakaviin seurauksiin.
GPT-4.1:llä on mitattavasti alhaisempi hallusinaatiotaajuus kuin GPT-4o:lla, erityisesti pitkissä asiakirjoissa, joissa aiemmat OpenAI-mallit alkoivat poiketa lähteestä myöhemmissä osissa. Miljoonan tokenin konteksti-ikkunan ja parannetun ohjeiden noudattamisen yhdistelmä tarkoittaa, että GPT-4.1 säilyttää uskollisuuden lähteelle pidempään ilman erityisiä kehotestrategioita. Yritysten ostajille, jotka käsittelevät sääntelyilmoituksia, tuotedokumentaatiota tai sopimuksia, tämä on merkittävä luotettavuuden parannus.
DeepSeek V3:n harhaluuloprofiili on luonteeltaan erilainen. Hyvin tuetuilla kielipareilla (kiina, englanti, arabia) se on yleensä luotettava. Riski kasvaa vähäresurssisten parien kohdalla: Korea→Swahili, Arabia→Vietnam, tai mikä tahansa pari, jossa yksi kieli on aliedustettuna koulutuskorpuksessa. Näissä tapauksissa DeepSeek V3:n on havaittu tuottavan uskottavalta kuulostavaa, mutta lähteestä tukematonta sisältöä, erityisesti silloin, kun lähde sisältää epäselviä nimettyjä entiteettejä tai toimialakohtaista terminologiaa.
Käytännön seuraus: jos kieliparivalikoimasi keskittyy korkean resurssin kieliin, DeepSeek V3:n hallusinaatioriski on hallittavissa tavallisilla QA-prosesseilla. Jos suoritat käännöksiä suuressa mittakaavassa vähävaraisten kieliparien välillä, GPT-4.1:n lisääntynyt luotettavuus voi oikeuttaa korkeamman hinnan.
💬 Se, mitä näemme jatkuvasti alustalla, on se, että GPT-4.1:n ja DeepSeek V3:n välinen ero harha-aistimuksissa ei liity määrään, vaan siihen, missä se tapahtuu. Englanniksi, ranskaksi tai espanjaksi tuotetun sisällön luotettavuudessa useimmat ammattikääntäjät eivät huomaisi merkittävää eroa. DeepSeek V3:n ongelmat ilmenevät yleensä korealaisissa tai arabialaisissa asiakirjoissa, jotka sisältävät vieraita erisnimiä tai erittäin alakohtaista terminologiaa. GPT-4.1 käsittelee näitä reunatapauksia konservatiivisemmin, ja se täyttää aukkoja harvemmin uskottavalta kuulostavalla sisällöllä.
— Kääntäjä MachineTranslation.comista
Kumpi malli käsittelee rajoitettua käännöstä paremmin?
Rajoitettu käännös (jossa mallin on noudatettava sanastoa, ylläpidettävä brändin rekisteriä, vältettävä tiettyjen termien kääntämistä tai säilytettävä asiakirjan rakenne, kuten otsikot ja alaviitteet) on alue, jolla GPT-4.1:n arkkitehtuurin edut tulevat selkeimmin esiin.
Kun annat järjestelmän kehotteen, jossa on 200 termin sanasto, ja ohjeistat mallia merkitsemään kaikki lähdesegmentit, joille ei löydy tarkkaa vastaavuutta, GPT-4.1 noudattaa näitä ohjeita johdonmukaisesti, jota aiemmat mallit eivät pystyneet ylläpitämään muutaman sadan tokenin jälkeen. Miljoonan tokenin konteksti-ikkunassa tämä tarkoittaa, että voit kääntää 400-sivuisen teknisen käyttöoppaan, jossa on monimutkainen termistörajoitus, yhdellä kutsulla ja odottaa johdonmukaista sanaston soveltamista koko tekstissä.
DeepSeek V3 käsittelee suoraviivaiset rajoitukset riittävästi – yksittäisten termien käännöskielto-ohjeet, perusrekisteriasetukset, yksinkertaiset muotoilusäännöt. Siinä, missä se suoriutuu huonosti, ovat monimutkaiset, yhdistetyt käskysarjat. Kun samanaikaisten rajoitusten määrä kasvaa, DeepSeek V3 alkaa priorisoida joitakin ohjeita toisten yli tavoilla, joita on vaikea ennustaa testaamatta. Lokalisaatiotiimeille, jotka hallinnoivat monitasoisia tyylioppaita ja suuria käännösmuisteja, tämä epäjohdonmukaisuus luo jälkikäteen laadunvarmistuksen lisäkustannuksia, jotka osittain kumoavat mallin kustannusedun.
Puhtaassa, rajoittamattomassa standardisisällön käännöksessä (yleinen yritysviestintä, markkinointitekstit, verkkokaupan tuotekuvaukset) kahden mallin välinen rajoitusten käsittelyn ero on suurelta osin merkityksetön. Ero on merkittävin yritystason työnkulkuja käyttäville tiimeille, joissa käännös on yksi vaihe monivaiheisessa lokalisointiprosessissa.
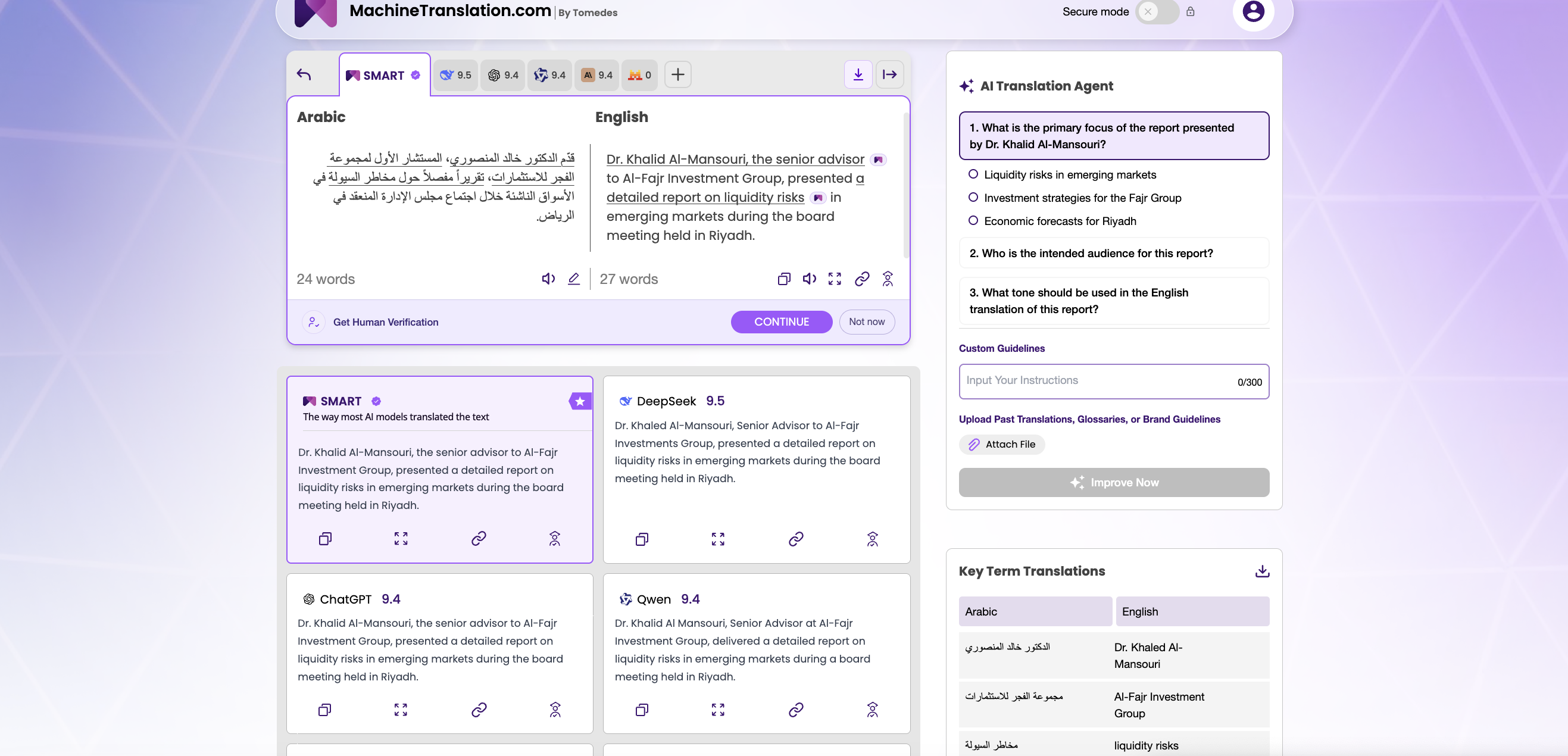
💬 Ajoimme molempia malleja samalla sanastolla lakiasiakirjoihin, noin 120 000 sanaa kahdeksassa kieliparissa. GPT-4.1 noudatti terminologiarajoituksia lähes täydellisesti. DeepSeek V3 oli lähellä, mutta se korvasi toisinaan suositellun termin lähes synonyymillä, jota asiakkaamme olivat nimenomaisesti pyytäneet meitä välttämään. Sillä äänenvoimakkuudella melkein ei riitä. Rajoittamattomalle sisällölle käytämme DeepSeek V3:a, ja säästöt ovat merkittäviä. Kaikkien asiakkaan hyväksymien sanastojen osalta käytämme edelleen GPT-4.1:tä.
— Lokalisointipäällikkö osoitteessa MachineTranslation.com
Kustannukset ja käyttöönotto: Mitä muutoksia mittakaavassa
Kustannukset ovat siellä, missä kaksi mallia eroavat jyrkimmin ja missä arvioinnissa on otettava huomioon enemmän kuin token-kohtainen hinnoittelu.
GPT-4.1 on hinnoiteltu premium-tasolle. Organisaatioille, jotka käsittelevät miljoonia sanoja kuukaudessa OpenAI API:n kautta, tuo kustannus kasvaa nopeasti. Malli ei ole saatavilla itse isännöitäväksi, mikä tarkoittaa, että jokainen token sisältää API-maksun, jota ei voida pienentää infrastruktuuri-investoinneilla.
DeepSeek V3:n kustannusprofiili on pohjimmiltaan erilainen. DeepSeek API:n kautta se on huomattavasti halvempaa tokenia kohden kuin GPT-4.1. Itse isännöitynä talous muuttuu entisestään: organisaatiot, joilla on GPU-infrastruktuuri, voivat ajaa DeepSeek V3:a kustannuksella, jonka määrää ensisijaisesti laskentateho eikä token-kohtainen lisensointi. Suurivolyymisissä käännöstoiminnoissa (globaalit verkkokauppojen luettelot, monikieliset sisältöputket, sääntelyasiakirjojen käsittely) ero voi merkitä satojatuhansia dollareita vuodessa yritystasolla.
DeepSeek V3:n avoimen lähdekoodin lisenssillä on merkitystä myös dataintensiivisillä aloilla. Lakialan, rahoitusalan ja terveydenhuollon organisaatiot, jotka eivät voi lähettää asiakasasiakirjoja ulkoisiin API-rajapintoihin, voivat ottaa DeepSeek V3:n käyttöön paikallisesti. GPT-4.1 ei tarjoa vastaavaa vaihtoehtoa.
Päätöksentekosääntö on suhteellisen selkeä: jos työmääräsi on suuri, kieliparisi ovat hyvin tuettuja ja tietosuojakäytäntösi sallivat API-palvelut tai paikallisen käyttöönoton, DeepSeek V3 tarjoaa kilpailukykyistä laatua huomattavasti alhaisemmalla hinnalla. Jos työmääräsi sisältää rajoitettua käännöstä, pitkien asiakirjojen uskollisuutta tai vähäresurssisia kielipareja, GPT-4.1:n luotettavuus voi olla lisämaksun arvoinen.
Kuinka testata molempia malleja sitoutumatta kumpaankaan
Useimpien lokalisointitiimien käytännön este mallin valinnalle ei ole vertailuarvojen ymmärtäminen – se on kitka, joka liittyy molempien mallien itsenäisten API-integraatioiden määrittämiseen, vertailukelpoisten testiolosuhteiden suunnitteluun ja merkityksellisen arvioinnin suorittamiseen omalla sisällöllä.
MachineTranslation.com poistaa tämän esteen. Alustalla GPT-4.1 ja DeepSeek V3 toimivat rinnakkain, mikä antaa ammattikääntäjille ja lokalisointipäälliköille mahdollisuuden syöttää sama lähdeteksti molemmille malleille samanaikaisesti ja vertailla tuotoksia reaaliajassa — ilman erillistä API-avainta, ilman hankintaprosessia ja sitoutumatta kumpaankaan malliin.
Tämä on tärkeää, koska suorituskyky vertailutesteissä aineistotasolla ei aina ennusta suorituskykyä juuri sinun sisällölläsi. Malli, joka saavuttaa korkeat COMET-pisteet WMT24 kiina→englanti -uutisteksteissä, voi suoriutua heikosti yrityksesi erityisterminologiassa tai -toimialueella. Ainoa arviointi, joka on päätöksenteon kannalta merkityksellinen, on sellainen, joka tehdään omilla asiakirjoilla, omilla rajoituksilla ja omilla kielipareilla.
MachineTranslation.comin asema neutraalina monimallialustana tarkoittaa, ettei sillä ole kaupallista kannustinta suosia GPT-4.1:tä tai DeepSeek V3:a. Alustan rooli on antaa sinulle vertailutiedot, jotta voit tehdä päätöksen itse, ja sen jälkeen ajaa valitsemaasi mallia tuotantotasolla, kun arviointi on valmis. Vaikka tietysti se antaa myös käännöksen, jonka useimmat tekoälymallit hyväksyvät oletusarvoisesti parhaaksi käännökseksi.
Tiimeille, jotka arvioivat myös OpenAI-mallien tasoa, GPT-4.1:n vertailu muihin OpenAI-malleihin (mukaan lukien GPT-4.5 ja GPT-4o) tarjoaa hyödyllistä taustatietoa ennen malliversion valitsemista. Ja tiimeille, jotka arvioivat, miten DeepSeek V3 vertautuu GPT-4o:hon vuoden 2025 alkupuolella, tämä artikkeli käsittelee sitä, mikä on muuttunut GPT-4.1:n julkaisun myötä.
Kumpi malli kannattaa valita käännöstyönkulkuun?
Yhden suosituksen sijaan seuraava kehys heijastaa päätöksentekologiikkaa, josta useimmat ammattimaiset käännöstiimit löytävät hyötyä:
-
Aloita kielipareistasi. Jos salkkusi on keskittynyt kiinaan↔englantiin, arabiaan tai koreaan, DeepSeek V3:n WMT24-suorituskyky tekee siitä luonnollisen ensimmäisen testin. Jos työskentelet pääasiassa eurooppalaisten kielten parissa ja käytät rajattua terminologiaa, GPT-4.1 tuottaa todennäköisesti johdonmukaisempaa tulosta heti ensimmäisestä päivästä lähtien.
-
Arvioi rajoitteidesi monimutkaisuus. Yksitasoiset rajoitukset (yksi sanasto, yksi rekisteri) käsitellään riittävästi kummallakin mallilla. Monitasoiset rajoitukset (sanasto + muoto + älä käännä -luettelo + QA-pisteytys), GPT-4.1 on tällä hetkellä luotettavampi.
-
Kartoita volyymisi kustannuseroa vastaan. Alle 500 000 sanaa kuukaudessa absoluuttinen API-kustannusero ei välttämättä vaikuta merkittävästi budjettiisi. Sen kynnyksen ylittyessä DeepSeek V3:n kustannusetua on yhä vaikeampi sivuuttaa.
-
Ota huomioon tietojenhallintavaatimuksesi. Jos asiakirjat eivät voi poistua infrastruktuuristasi, DeepSeek V3 itse isännöitynä on tällä hetkellä ainoa toimiva vaihtoehto näistä kahdesta.
-
Suorita arviointi omalla sisällölläsi, älä vertailuaineistoilla. Käytä MachineTranslation.com-sivustoa lähettääksesi edustavia näytteitä todellisesta työkuormastasi molempiin malleihin ja arvioidaksesi tuloksia omien laatuvaatimustesi perusteella ennen sitoutumista.
Saadaksesi laajemman kuvan siitä, missä nämä mallit sijoittuvat nykyisessä tekoälykäännöskentässä, 2026 parhaat tekoälykäännöstyökalut kattaa koko kilpailukentän, mukaan lukien sen, miten suuret kielimallit (LLM) vertautuvat tarkoitukseen rakennettuun käännösinfrastruktuuriin.
Usein kysytyt kysymykset
1. Onko GPT-4.1 parempi kuin DeepSeek V3 kääntämisessä?
Kumpikaan malli ei ole yleisesti parempi. GPT-4.1 päihittää DeepSeek V3:n rajoitetuissa käännöstehtävissä, pitkien asiakirjojen uskollisuudessa ja vähäresurssisissa kielipareissa, joissa hallusinointiriski on suurempi. DeepSeek V3 vastaa tai ylittää GPT-4.1:n suorituskyvyn useissa WMT24-vertailuarvoissa (erityisesti kiina↔englanti, arabia ja korea) ja on huomattavasti halvempi ajaa suuressa mittakaavassa tai itse isännöitynä.
2. Hallusinoiko DeepSeek V3 enemmän kuin GPT-4.1?
Resurssirikkailla kielipareilla hallusinaatioero on suhteellisen pieni. Kuilu levenee vähäresurssisten parien ja harvinaisia nimettyjä entiteettejä sisältävän toimialakohtaisen sisällön kohdalla, jossa DeepSeek V3 on osoittanut korkeampia lähdetukeen kuulumattomien lisäysten tai korvausten määriä. GPT-4.1 osoittaa vähentyneitä hallusinaatioita verrattuna GPT-4o:hon, erityisesti pidemmissä asiakirjoissa.
3. Voinko käyttää DeepSeek V3 kaupallisesti?
Kyllä. DeepSeek V3 julkaistaan MIT-lisenssillä, joka sallii kaupallisen käytön, mukaan lukien hienosäädön ja itseisännöinnin. Organisaatiot, jotka eivät voi lähettää asiakirjoja ulkoisiin API-rajapintoihin, voivat ottaa DeepSeek V3:n käyttöön omassa infrastruktuurissaan. GPT-4.1 edellyttää OpenAI API:n käyttöä OpenAI:n käyttöehtojen mukaisesti, eikä sitä ole saatavilla itse isännöitäväksi.
4. Mikä malli on parempi kiina-englanti-käännöksessä?
DeepSeek V3:lla on etulyöntiasema kiina↔englanti-käännöksessä WMT24-vertailutulosten perusteella. Kuitenkin kiina→englanti-käännöksissä, jotka sisältävät rajoitettua terminologiaa, oikeudellista tarkkuutta tai monimutkaista muotoilua, GPT-4.1:n ohjeiden noudattamiskyky tekee siitä luotettavamman tuotantotyönkuluissa, joissa ihmiskääntäjä jälkikäteen muokkaa tulosta.
5. Voinko testata GPT-4.1:tä ja DeepSeek V3:a rinnakkain ennen valintaa?
Kyllä — MachineTranslation.com ajaa molempia malleja samanaikaisesti (ja yli 20 muuta) ja antaa sinun vertailla tuloksia omalla sisällölläsi reaaliajassa, ilman erillisiä API-tilejä tai hankintaprosessia.
6. Miten DeepSeek V3 vertautuu Claudeen käännöksissä?
Tiimeille, jotka myös arvioivat Anthropicin mallia, Claude vs DeepSeek V3 -vertailu kattaa keskeiset erot arkkitehtuurissa, tarkkuudessa ja käyttöönotto-optioissa käännöksiin liittyvissä skenaarioissa.