May 14, 2026
Claude contre DeepL pour la traduction : Lequel est vraiment le meilleur?
Voici le point de départ honnête : Claude et DeepL ne sont pas vraiment en concurrence pour le même utilisateur.
DeepL a été conçu pour la traduction. Ça raffine une chose (convertir du texte d'une langue à une autre avec une fluidité naturelle) depuis 2017. Claude est un modèle de raisonnement polyvalent développé par Anthropic qui traduit exceptionnellement bien, surtout lorsque le contenu est long, complexe ou nécessite une interprétation contextuelle approfondie.
La question « Claude contre DeepL » est importante pour les personnes qui décident réellement comment gérer le travail de traduction professionnelle et qui veulent une réponse claire, et non une comparaison marketing. C'est ce que cet article vise à être.
Dans cet article
- Ce pour quoi chaque outil a été conçu
- Comment Claude et DeepL se comparent-ils en termes de précision ?
- Où DeepL a un véritable avantage
- Où Claude prend de l'avance
- Couverture linguistique et gestion des documents
- Tarification : Ce que vous payez réellement
- Lequel devriez-vous utiliser?
- Que se passe-t-il lorsque vous exécutez les deux en même temps
- Questions fréquemment posées
Ce pour quoi chaque outil a été conçu
Claude : un modèle de raisonnement utilisé pour la traduction

Claude est développé par Anthropic et est, à la base, un grand modèle linguistique conçu pour le raisonnement, l'analyse et la génération dans un large éventail de tâches. La traduction est une de ces tâches, et il s'avère que Claude est très bon dans ce domaine — particulièrement pour le contenu où le contexte environnant détermine le sens : documents juridiques, textes littéraires, spécifications techniques et tout ce où une seule phrase ne peut pas être comprise isolément.
La famille actuelle Claude 4 (Claude Opus 4 et Claude Sonnet 4) dispose d'une fenêtre contextuelle de 200 000 jetons, ce qui change ce qui est possible en traduction. Un traducteur de documents qui travaille segment par segment manque les dépendances entre les phrases, les incohérences dans les noms de personnages ou la terminologie, et les changements de ton d'un chapitre à l'autre. Claude n'a pas ce problème. Quand on lui donne un contrat complet, il voit tout le contrat.
Selon l'étude « State of Translation Automation 2025 » de Intento, Claude Opus 4 et Claude Sonnet 3.7 se classent parmi les solutions à agent unique les plus performantes pour les paires de langues anglais-allemand, anglais-néerlandais, anglais-italien, anglais-japonais et anglais-coréen, tant dans l'évaluation automatisée que dans l'évaluation LQA humaine.
DeepL : un outil conçu spécifiquement pour la traduction

DeepL fait une chose et l'a optimisée sans relâche. Son moteur de traduction automatique neuronal est entraîné spécifiquement sur des données pertinentes pour la traduction, et cette spécialisation se manifeste dans son résultat : Les traductions de DeepL sonnent constamment plus naturelles pour les paires de langues européennes que la plupart des concurrents. La formulation est idiomatique, la grammaire est impeccable et le registre correspond généralement bien à la source.
Dans le test interne de MachineTranslation.com portant sur 5 000 mots de contenu technique et marketing mixte, DeepL a obtenu un score de précision de 94,2 % — le plus élevé de tous les moteurs autonomes testés, et décrit dans le test comme « le roi du flux ». Pour les paires de langues européennes en particulier, ça sonne le plus humain.
DeepL a également lancé DeepL nouvelle génération en 2024, un grand modèle linguistique (GML) conçu pour la traduction qui améliore le modèle classique pour les textes plus longs, et que l'évaluation 2025 d'Intento place parmi les solutions en temps réel les plus performantes pour plusieurs paires de langues, dont l'anglais vers l'espagnol, le français, l'italien, le néerlandais, le coréen et le portugais.
Le compromis pour cette spécialisation : DeepL prend en charge 33 langues, ce qui est peu. Et c'est un système à modèle unique — le résultat que vous recevez est l'interprétation de DeepL, sans signal de contre-vérification et sans moyen de savoir quand il a fait un choix avec lequel vous pourriez être en désaccord.
Comment Claude et DeepL se comparent-ils en termes de précision ?
La réponse dépend fortement de ce que vous traduisez et dans quelle langue.
Paires de langues européennes
Pour les paires de langues européennes de base (allemand, français, espagnol, italien, néerlandais, portugais), DeepL nouvelle génération est vraiment compétitif. L'évaluation de la qualité linguistique humaine (LQA) d'Intento en 2025 le place dans la catégorie supérieure pour six des onze paires de langues évaluées. La sortie semble naturelle, idiomatique et formelle de manière appropriée sans nécessiter d'ingénierie de prompt de la part de l'utilisateur.
Claude Opus 4 et Sonnet 3.7 apparaissent également dans le haut du classement pour plusieurs de ces paires, en particulier de l'anglais à l'allemand et de l'anglais au néerlandais, où le raisonnement contextuel de Claude l'aide à gérer la complexité morphologique et l'accord des cas sur des textes plus longs.
La différence pratique à ce niveau : pour le contenu court et standard (descriptions de produits, champs de formulaire, copie d'interface utilisateur), l'avantage de vitesse de DeepL est important et sa qualité est constante. Pour du contenu plus long et complexe, la fenêtre contextuelle et la profondeur de raisonnement de Claude produisent des résultats nettement plus solides.
Gestion des documents longs et du contexte
C'est là que la comparaison devient moins serrée.
Comme le montre l'analyse interne de MachineTranslation.com, les erreurs qui subsistent dans la traduction moderne par IA sont presque entièrement sémantiques : ton erroné, registre erroné, terme erroné, dépendance manquée entre les phrases. Ce ne sont pas des erreurs qu'une traduction segment par segment détecte. Ce sont des erreurs qui ne font surface que lorsque vous lisez le document complet et remarquez que le titre d'un personnage a changé après trois pages, ou qu'un terme défini a été rendu différemment dans deux clauses.
La fenêtre contextuelle de 200 000 jetons de Claude signifie qu'il peut conserver un accord juridique complet, un manuel technique ou un chapitre littéraire entier dans sa mémoire de travail et produire une traduction qui est cohérente en interne dans l'ensemble du document. La fonction de traduction de documents de DeepL traite le contenu section par section, ce qui fonctionne généralement bien pour les documents structurés, mais peut introduire le genre de dérive que Claude évite par conception.
Contenu technique et spécifique à un domaine
Les deux outils gèrent assez bien le contenu technique général. Pour les domaines hautement spécialisés (juridique, médical, financier), les résultats dépendent de la qualité de l'adaptation du contenu source aux données d'entraînement de chaque outil.
DeepL permet l'injection de glossaires sur les forfaits API payants, ce qui aide à maintenir la cohérence terminologique. Claude, utilisé via l'API ou dans une invite bien structurée, peut absorber un glossaire complet comme contexte et l'appliquer partout. Aucune des deux approches n'est définitivement meilleure ; les deux exigent un travail de configuration de la part de l'utilisateur.
Là où DeepL a un véritable avantage
: le naturel et la fluidité pour les paires de langues européennes. Lorsqu'une traduction doit sonner comme si elle avait été écrite par un locuteur natif (textes de marketing, communications de marque, contenu destiné aux consommateurs), le résultat de DeepL est constamment parmi les plus naturels disponibles. Claude traduit avec exactitude, mais la traduction de DeepL, surtout pour les paires de langues européennes, sonne plus idiomatique.
Vitesse. DeepL est un moteur de traduction automatique neuronal optimisé pour le débit. Pour les flux de travail à volume élevé et sensibles au temps, c'est beaucoup plus rapide que Claude, qui fonctionne à la vitesse des LLM.
Intégration du flux de travail. DeepL possède un écosystème mature: Plugins pour outils de TAO, une API bien documentée, gestion de glossaire et paramètres de ton (formel/informel). Ça s'intègre dans les flux de travail des traducteurs professionnels d'une manière que Claude, en tant que modèle à usage général, ne fait pas nativement.
Une sortie cohérente pour le contenu standard. Pour le contenu où la tâche de traduction est bien définie et où la sortie doit simplement être correctement fiable, DeepL élimine les variables. Vous savez à peu près ce que vous allez obtenir.
Là où Claude prend de l'avance
Des documents longs et complexes sur le plan contextuel. Un contrat de 40 pages, un chapitre littéraire, une spécification technique en plusieurs sections — Claude traite le tout en une seule fois et maintient la cohérence d'un bout à l'autre, ce que la traduction segment par segment ne peut pas reproduire.
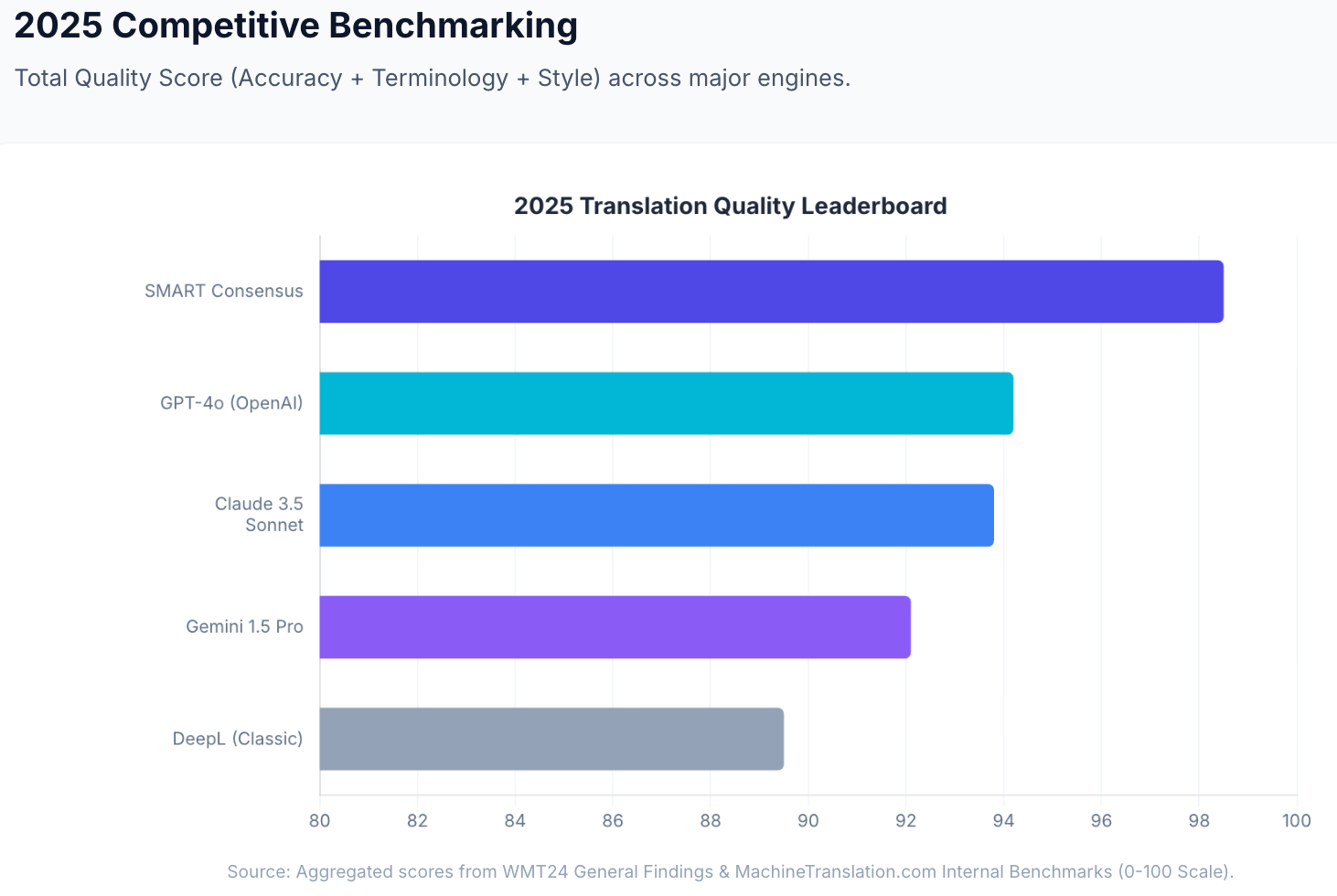
Nuances et registre. Claude 3.5 Sonnet a obtenu un score de 93,8 sur 100 dans le test de qualité interne de MachineTranslation.com, avec de bons résultats sur le contenu où le ton est important : traductions de la voix de la marque, communications avec les parties prenantes et correspondance professionnelle où « techniquement correct » ne suffit pas.
Largeur multilingue. Claude prend en charge une gamme de langues beaucoup plus large que les 33 de DeepL. Pour les équipes qui travaillent en dehors de la zone de couverture européenne principale de DeepL, Claude comble un réel manque.
Raisonnement sur le texte. Si vous ne faites pas que traduire, mais demandez aussi au modèle d'adapter le contenu pour un public différent, d'ajuster le registre ou de signaler les phrases culturellement inappropriées, Claude le fait dans le cadre de la même tâche. DeepL traduit. Claude pense aussi.
Couverture linguistique et traitement des documents
| Claude (Opus 4 / Sonnet 4) | DeepL (Classique + nouvelle génération) | |
|---|---|---|
| Langues prises en charge | Multilingue étendu (plus de 100) | 33 langues |
| Fenêtre contextuelle | Jusqu'à 200 000 jetons | Segment par segment |
| Formats de documents | Via API ou téléchargement de fichiers | PDF, DOCX, PPTX, XLSX |
| Préservation de la mise en page | Limitée | Forte (mise en forme originale préservée) |
| Taille des fichiers | Dépend du nombre de jetons | Jusqu'à 30 Mo pour les forfaits supérieurs |
| Prise en charge des glossaires | Via l'invite / API | Fonctionnalité de glossaire native |
| Intégration des outils de TAO | Non | Oui (prise en charge des principaux outils de TAO) |
Une note pratique sur les documents : DeepL conserve la mise en forme originale lors de la traduction de fichiers DOCX et PDF, ce qui est vraiment utile pour les documents d'affaires où la remise en forme après la traduction prend beaucoup de temps. La traduction de documents de Claude via l'API ne conserve pas la mise en page de la même manière, ce qui est important pour tout ce qui sera distribué directement sans post-traitement.
Tarification: Ce que vous payez réellement
Claude (via l'API Anthropic) :
- Claude Sonnet 4 : 3,00 $ par million de jetons d'entrée / 15,00 $ par million de jetons de sortie
- Claude Opus 4 : 15,00 $ par million de jetons d'entrée / 75,00 $ par million de jetons de sortie
- Via Claude.ai : Niveau gratuit disponible avec des limites d'utilisation; Forfait Pro à 20 $/mois
DeepL:
- Gratuit : nombre de caractères limité, 3 traductions de documents non modifiables par mois
- Débutant : ~10,49 $/utilisateur/mois
- Avancé : ~34,49 $/utilisateur/mois
- Ultime : ~68,99 $/utilisateur/mois
- API Pro : 25 $ par million de caractères
Pour la plupart des utilisateurs professionnels individuels, la tarification par abonnement de DeepL est plus prévisible. Pour les flux de travail qui utilisent beaucoup d'API, la comparaison dépend du volume : La tarification par jeton de Claude varie différemment de celle par caractère de DeepL, et à volume élevé, la différence peut aller dans un sens ou dans l'autre selon la longueur moyenne des documents et la direction de la traduction.
Lequel devriez-vous utiliser ?
Le choix dépend de ce que vous traduisez, et non de l'outil qui est objectivement le meilleur.
| Cas d'utilisation | Meilleur choix |
|---|---|
| Textes publicitaires, contenu européen destiné aux consommateurs | DeepL |
| Longs documents juridiques ou techniques nécessitant de la cohérence | Claude |
| Chaînes d'interface utilisateur, descriptions de produits en volume | DeepL |
| Traduction littéraire ou de la voix de la marque | Claude |
| Langues en dehors des 33 prises en charge par DeepL | Claude |
| Flux de travail avec des outils de TAO ou une intégration TMS | DeepL |
| Contenu nécessitant la préservation de la mise en forme | DeepL |
| Raisonnement ou adaptation multilingue complexe | Claude |
| Traduction standard rapide et à volume élevé | DeepL |
| Contenu sensible où la nuance contextuelle est primordiale | Claude |
Aucune réponse n'est permanente. Une équipe qui traduit un catalogue de produits en français et une équipe qui traduit un avis juridique en japonais ont besoin de paramètres par défaut différents.
Qu'arrive-t-il quand on exécute les deux en même temps
Il y a un argument selon lequel la question Claude contre DeepL n'est pas la plus utile. Les deux sont des outils puissants avec des forces différentes. La question la plus utile est : comment tirer le meilleur des deux ?
Quand vous faites tourner Claude et DeepL sur le même texte source et que vous comparez les résultats, les différences vous renseignent sur le contenu. Une forte concordance entre les deux moyennes indique que la traduction est relativement non ambiguë. La divergence révèle où existent de véritables choix interprétatifs — quel mot, quel registre, quelle traduction idiomatique.
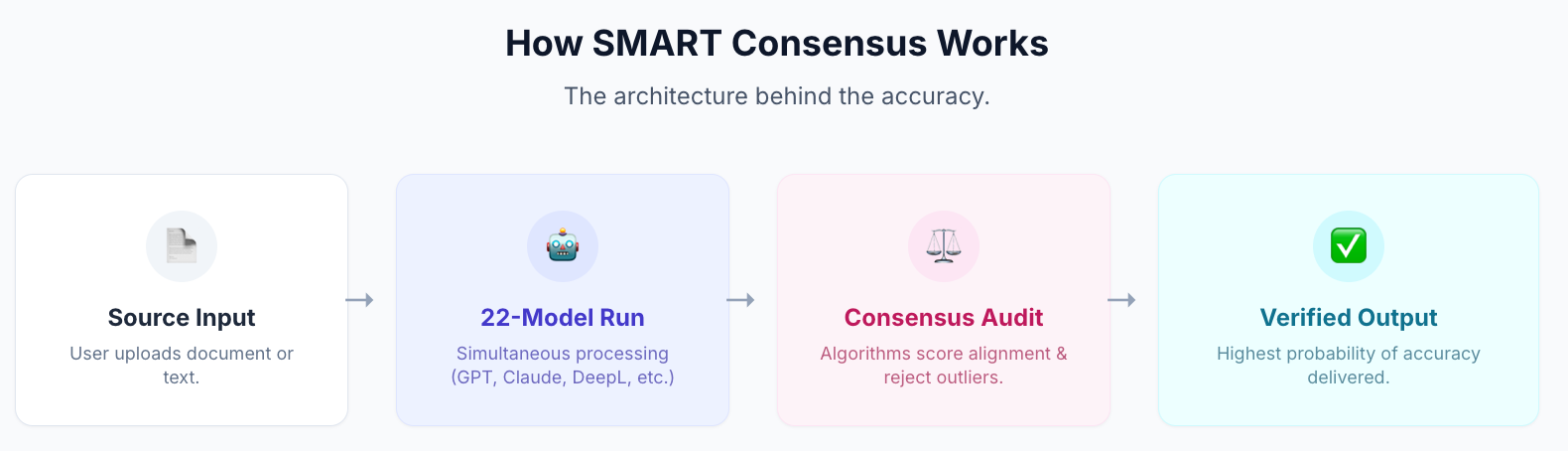
C'est ce que le système SMART de MachineTranslation.com fait en pratique. Il exécute 22 modèles d'IA simultanément (y compris Claude et DeepL) et affiche le résultat sur lequel la majorité des modèles convergent, ainsi que des scores de qualité pour chacun. La convergence est le signal : lorsque Claude et DeepL (et 20 autres modèles) aboutissent à la même traduction, la probabilité que celle-ci soit correcte est structurellement plus élevée que de se fier à l'un ou l'autre seul.
Dans les évaluations internes de MachineTranslation.com, cette approche par consensus atteint un score de qualité agrégé de 98,5 sur 100 — comparativement à Claude 3.5 Sonnet à 93,8 et DeepL Classic à 94,2 en tant que moteurs autonomes. La différence n'est pas marginale : c'est l'écart entre faire confiance à l'interprétation d'un modèle et savoir sur quoi la plupart des modèles s'entendent.
Pour de nombreuses tâches de traduction, Claude ou DeepL vous seront utiles. Pour du contenu où se tromper a de réelles conséquences, voir où ils s'entendent vaut plus que l'un ou l'autre seul.
Questions fréquemment posées
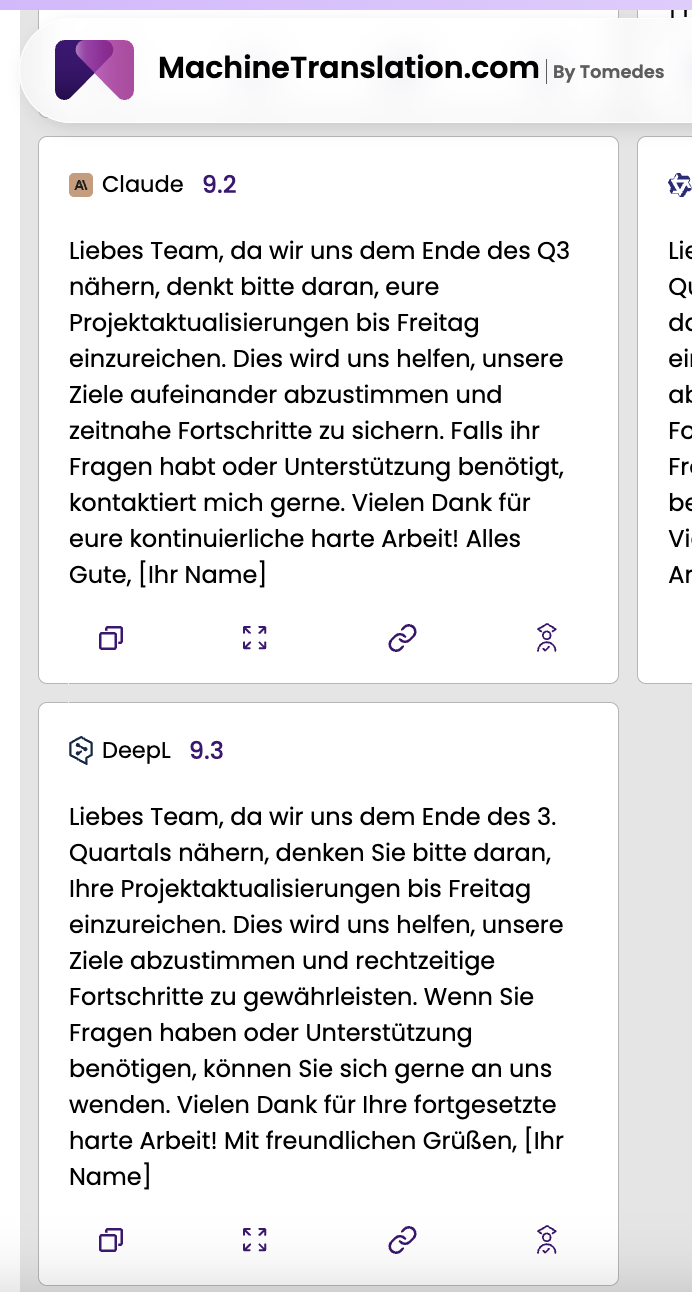
1. Est-ce que Claude est meilleur que DeepL pour la traduction ?
Ça dépend du type de contenu. DeepL est meilleur pour la traduction de langues européennes courtes et à volume élevé, où la fluidité et la rapidité sont prioritaires. Claude est meilleur pour les longs documents, le contenu complexe nécessitant une terminologie cohérente sur plusieurs pages et les paires de langues en dehors de la couverture de 33 langues de DeepL. Pour la plupart des flux de travail professionnels, la réponse honnête est qu'ils sont forts de différentes manières.
2. Lequel est le plus précis : Claude ou DeepL?
Selon le test interne de MachineTranslation.com sur 5 000 mots de contenu technique et marketing mixte, DeepL a obtenu un score de 94,2 % de précision et Claude 3.5 Sonnet, un score de 93,8 %. À ce niveau, la différence n'est pas vraiment significative pour la plupart du contenu. Ce qui distingue Claude, c'est sa capacité à gérer les documents plus longs où la cohérence du contexte est importante, et où le traitement segment par segment de DeepL peut entraîner une dérive terminologique.
3. Est-ce que DeepL prend en charge autant de langues que Claude?
Non. DeepL prend en charge 33 langues, avec une force particulière pour les paires européennes. Claude gère un éventail de langues beaucoup plus large, y compris des paires de langues moins courantes qui ne font pas partie des langues sur lesquelles DeepL s'est concentré pour son entraînement. Pour toute langue qui ne figure pas dans la liste de DeepL, Claude est l'option la plus compétente.
4. Est-ce que je peux utiliser Claude et DeepL ensemble?
Pas directement dans l'un ou l'autre outil. MachineTranslation.com utilise simultanément Claude et DeepL dans le cadre de son système à 22 modèles, vous montrant le résultat et le score de qualité pour chacun, et mettant en avant la traduction sur laquelle la majorité des modèles s'accordent. Pour les utilisateurs qui veulent comparer les deux sans gérer des intégrations séparées, c'est une façon pratique de voir comment chaque outil gère le même contenu.
5. Est-ce que DeepL ou Claude est meilleur pour les documents juridiques?
Pour les longs documents juridiques nécessitant une cohérence interne (termes définis utilisés de manière constante, registre formel maintenu tout au long, références croisées entre les clauses), la fenêtre contextuelle de Claude est un avantage significatif. Pour les textes juridiques plus courts, comme les clauses types ou les accords brefs, la traduction de DeepL est généralement fluide et rapide. Pour les traductions juridiques à enjeux élevés où les erreurs entraînent une responsabilité, la vérification humaine demeure l'étape finale appropriée, peu importe l'outil d'IA qui a produit l'ébauche.
6. Comment les prix de DeepL se comparent-ils à ceux de Claude?
Les forfaits d'abonnement de DeepL commencent à environ 10,49 $ par utilisateur par mois pour une utilisation professionnelle. Claude est tarifé par jeton via l'API : 3,00 $ par million de jetons d'entrée pour Sonnet 4 et 15,00 $ pour Opus 4. Pour les utilisateurs individuels qui font un volume modéré, l'abonnement de DeepL est généralement plus prévisible. Pour les flux de travail d'API à volume élevé, la comparaison des coûts dépend de la longueur et du volume des documents, et aucun des deux n'est systématiquement moins cher dans tous les cas d'utilisation.