June 10, 2026
GPT-4.1 c. DeepSeek V3 : Précision, hallucination et performance de traduction comparées
La question que la plupart des équipes de traduction se posent discrètement à la mi-2026 n'est pas « devrions-nous utiliser l'IA ? », cette décision a déjà été prise. La vraie question est de savoir sur quel modèle d'IA se standardiser, et si la réponse est la même pour chaque paire de langues, chaque type de document et chaque budget.
GPT-4.1 et DeepSeek V3 sont apparus comme les deux options les plus fréquemment évaluées pour les flux de travail de traduction professionnelle. Ils représentent des philosophies véritablement différentes : l'une est une API d'OpenAI, strictement réglementée et commercialement peaufinée ; l'autre est un modèle à poids ouverts, sous licence MIT, provenant d'un laboratoire de recherche chinois qui a discrètement surpassé plusieurs concurrents propriétaires sur les points de référence WMT24. Aucun n'est universellement meilleur. Le cas de chacun dépend de ce que vous traduisez, pour qui et sous quelles contraintes.
Cet article décompose les deux modèles selon les dimensions les plus importantes pour les traducteurs, les gestionnaires de localisation et les acheteurs d'entreprise : la précision sur les paires de langues réelles, le comportement d'hallucination, la gestion des tâches contraintes comme le respect de la terminologie, et le coût total de l'exécution de l'un ou l'autre à grande échelle.
Table des matières
- Pourquoi cette comparaison est importante maintenant
- Ce que chaque modèle est réellement
- Comparaison directe : Précision de la traduction et performance de référence
- Quel modèle hallucine le plus, et quand ?
- Quel modèle gère mieux la traduction contrainte ?
- Coût et déploiement : Quels changements à grande échelle
- Comment tester les deux modèles sans s'engager envers l'un ou l'autre
- Quel modèle devriez-vous choisir pour votre flux de traduction?
- Questions fréquemment posées
- Comparaisons connexes
Pourquoi cette comparaison est importante maintenant
Les acheteurs de traduction ont historiquement évalué la traduction automatique sur un axe étroit : Score BLEU par rapport au prix. Les LLM brisent complètement ce cadre. GPT-4.1 et DeepSeek V3 ne sont pas des moteurs de traduction automatique (TA) au sens traditionnel du terme — ce sont des modèles à usage général dotés de solides capacités multilingues, et leurs performances sur les tâches de traduction varient selon l'architecture, les données d'entraînement et la manière dont vous les sollicitez.
Cette variabilité est au cœur du problème d'évaluation. Un gestionnaire de localisation testant les deux modèles sur des textes marketing anglais vers espagnol pourrait observer une qualité de sortie quasi identique. Le même gestionnaire testant des documents juridiques de l'arabe vers l'anglais verra probablement un écart significatif — mais le modèle qui s'en sortira le mieux dépendra de la présence d'entités nommées, de jargon technique ou de références culturelles nécessitant une connaissance du monde plutôt qu'une simple reconnaissance de formes.
Les enjeux sont également asymétriques. DeepSeek V3 coûte beaucoup moins cher à exécuter, surtout en auto-hébergement. GPT-4.1 entraîne une prime de coût importante. Si les deux modèles offrent une qualité acceptable pour votre charge de travail spécifique, la différence de coût peut déterminer si un flux de travail de traduction IA est économiquement viable à grande échelle.
Ce que chaque modèle est réellement
GPT-4.1 : Le modèle phare d'OpenAI réglé sur les instructions
Lancé en avril 2025, GPT-4.1 est le modèle d'OpenAI le plus fidèle aux instructions à ce jour. Ses améliorations notables par rapport à GPT-4o ne résident pas dans la fluidité brute de la traduction (il excellait déjà dans ce domaine), mais dans la précision à suivre des instructions complexes et en plusieurs parties. Pour les flux de travail de traduction, cela est particulièrement important dans les tâches contraintes : appliquer un glossaire client, préserver la mise en forme du document sur de longs textes, maintenir un registre spécifique ou respecter une liste de non-traduction.
GPT-4.1 prend en charge une fenêtre contextuelle d'un million de jetons, ce qui signifie qu'il peut traiter des documents de la longueur d'un livre en un seul appel. Sur les tâches de sortie structurée (génération de mémoires de traduction en JSON, production de scores de qualité au niveau du segment accompagnant la traduction, mise en forme de tableaux bilingues), il est démontrablement plus fiable que ses prédécesseurs. Le compromis est le coût : GPT-4.1 se situe dans une catégorie de prix plus élevée que la plupart des alternatives, y compris DeepSeek V3.
DeepSeek V3 : Le concurrent open-source
DeepSeek V3 (la version de production actuelle est DeepSeek-V3-0324) est un modèle de 685 milliards de paramètres construit sur une architecture Mixture-of-Experts — ce qui signifie qu'un sous-ensemble de ses paramètres s'active pour toute entrée donnée, ce qui maintient les coûts d'inférence bas malgré le nombre énorme de paramètres totaux. Il est publié sous la licence MIT, ce qui signifie que les organisations peuvent l'auto-héberger, l'affiner et le déployer commercialement sans frais par jeton à un tiers.
Les performances de traduction du modèle ont attiré une attention considérable après le WMT24, où il a obtenu d'excellents scores BLEU et COMET sur les paires de langues chinois↔anglais, arabe et coréen — surpassant dans plusieurs cas GPT-4o. Pour les équipes qui travaillent intensivement avec des paires de langues asiatiques ou moyen-orientales, DeepSeek V3 n'est pas un choix de compromis. C'est vraiment compétitif pour une fraction du coût.
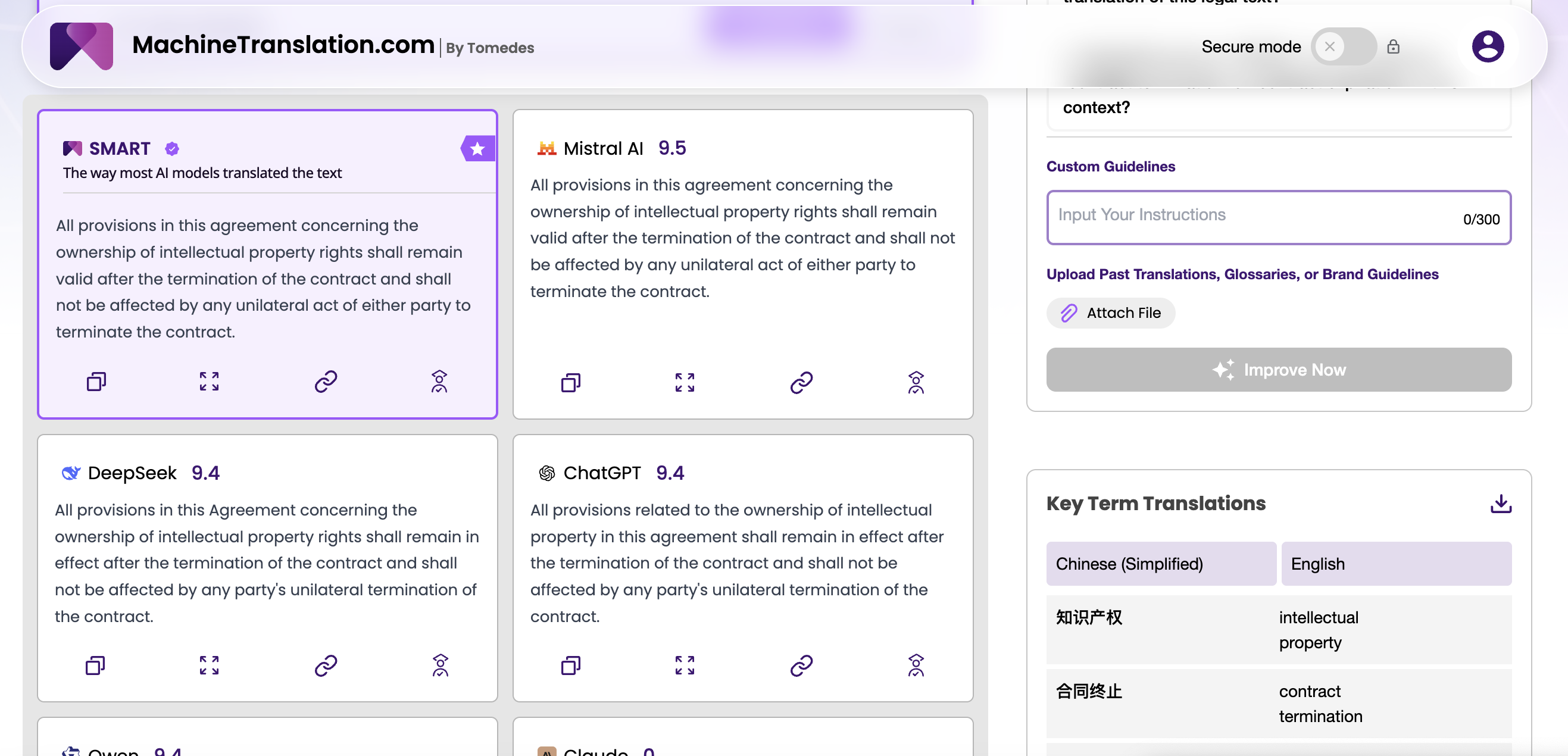
Comparaison directe : Précision de la traduction et performance de référence
| Dimension | GPT-4.1 | DeepSeek V3 |
|---|---|---|
| Fenêtre de contexte | 1 000 000 jetons | ~64 000 jetons (standard) |
| Architecture | Transformeur dense | Mélange d'experts (685 G de paramètres) |
| Licence | Propriétaire | Open-source (MIT) |
| Auto-hébergement | Non disponible | Disponible |
| Chinois↔Anglais WMT24 | Solide | Très solide, a surpassé GPT-4o sur plusieurs paires |
| Traduction arabe WMT24 | Compétitif | Solide, surtout sur texte spécialisé |
| Suivi d'instructions | Le meilleur de sa catégorie par rapport à GPT-4o | Bon; moins cohérent sur les invites complexes en plusieurs étapes |
| Sortie structurée | Très fiable | Fiable; légère dérive de formatage sur les sorties longues |
| Tendance à l'hallucination | Réduite par rapport à GPT-4o | Occasionnelle sur les paires à faible volume |
| Coût relatif de l'API | Plus élevé | Significativement plus bas |
Sur la précision générale de la traduction pour les paires de langues à volume élevé (anglais, français, espagnol, allemand, chinois, japonais), les deux modèles offrent un niveau que les traducteurs professionnels décrivent comme « prêt pour la post-édition ». L'écart entre eux en matière de fluidité et d'adéquation à lui seul n'est pas assez important pour motiver une décision d'achat pour la plupart des équipes.
Les différences significatives apparaissent dans trois scénarios spécifiques : les langues à faibles ressources, les tâches contraintes et les types de documents sujets à l'hallucination.
Quel modèle hallucine le plus, et quand ?
L'hallucination en traduction n'est pas la même que l'hallucination dans la génération à usage général. Le modèle travaille à partir d'un texte source, il n'invente pas de faits à partir de rien. L'hallucination se manifeste ici par l'ajout de contenu qui n'est pas dans la source, l'omission de propositions ou la substitution d'entités nommées. Dans une traduction juridique ou médicale, l'une de ces erreurs peut avoir des conséquences graves.
GPT-4.1 présente un taux d'hallucination mesurablement inférieur à celui de GPT-4o, en particulier sur les longs documents où les modèles OpenAI précédents commençaient à s'éloigner de la source dans les segments ultérieurs. La combinaison d'une fenêtre contextuelle d'un million de jetons et d'une meilleure capacité à suivre les instructions signifie que GPT-4.1 conserve la fidélité à la source plus longtemps sans nécessiter de stratégies d'incitation spéciales. Pour les acheteurs d'entreprise qui traitent des déclarations réglementaires, de la documentation produit ou des contrats, il s'agit d'une amélioration significative de la fiabilité.
Le profil d'hallucination de DeepSeek V3 est différent par nature. Sur les paires de langues bien prises en charge (chinois, anglais, arabe), c'est généralement fiable. Le risque augmente sur les paires à faibles ressources : Coréen→Swahili, Arabe→Vietnamien, ou toute paire où une langue est sous-représentée dans le corpus d'entraînement. Dans ces cas, DeepSeek V3 a été observé générant du contenu plausible mais non étayé par la source, particulièrement lorsque la source contient des entités nommées ambiguës ou de la terminologie spécifique au domaine.
L'implication pratique : si votre portefeuille de paires linguistiques est concentré sur des langues à haute ressource, le risque d'hallucination de DeepSeek V3 est gérable avec les processus d'AQ standard. Si vous effectuez des traductions à grande échelle sur des paires à faibles ressources, la fiabilité accrue de GPT-4.1 peut justifier le surcoût.
💬 « Ce que nous constatons constamment sur la plateforme, c'est que l'écart entre GPT-4.1 et DeepSeek V3 en matière d'hallucinations ne concerne pas le volume, mais l'endroit où cela se produit. Sur le contenu en anglais, français ou espagnol, la plupart des traducteurs professionnels ne remarqueraient pas de différence significative en termes de fiabilité. Les problèmes avec DeepSeek V3 ont tendance à apparaître sur les documents coréens ou arabes qui contiennent des noms propres inconnus ou une terminologie très spécifique à un domaine. GPT-4.1 gère ces cas limites de manière plus conservatrice, il est moins susceptible de combler une lacune avec quelque chose qui semble plausible. — Linguiste sur MachineTranslation.com Quel modèle gère mieux la traduction contrainte ?
La traduction contrainte (où le modèle doit respecter un glossaire, maintenir un registre de marque, éviter de traduire certains termes ou préserver la structure du document comme les en-têtes et les notes de bas de page) est là où les avantages architecturaux de GPT-4.1 deviennent les plus tangibles.
Lorsque vous fournissez une invite système
avec un glossaire de 200 termes et que vous demandez au modèle de signaler tout segment source pour lequel aucune correspondance exacte ne peut être trouvée, GPT-4.1 suit
ces instructions avec une cohérence que les modèles précédents ne pouvaient pas maintenir au-delà de quelques centaines de jetons. Dans une fenêtre contextuelle d'un million de jetons, cela signifie que vous pouvez traduire un manuel technique de 400 pages avec une contrainte de terminologie complexe en un seul appel et vous attendre à une application cohérente du glossaire tout au long du document.
DeepSeek V3 gère adéquatement les contraintes simples — instructions de ne pas traduire un terme unique, préférences de registre de base, règles de formatage simples. Là où il est moins performant, c'est dans les jeux d'instructions complexes et composés. À mesure que le nombre de contraintes simultanées augmente, DeepSeek V3 commence à accorder la priorité à certaines instructions par rapport à d'autres d'une manière difficile à prévoir sans tests. Pour les équipes de localisation qui gèrent des guides de style à plusieurs niveaux et de vastes mémoires de traduction, cette incohérence crée une surcharge d'assurance qualité en aval qui compense partiellement l'avantage de coût du modèle.
Pour la traduction pure et sans contrainte de contenu standard (communications générales d'affaires, textes marketing, descriptions de produits de commerce électronique), l'écart de gestion des contraintes entre les deux modèles est largement sans importance. La différence est la plus importante pour les équipes qui gèrent des flux de travail de niveau entreprise où la traduction n'est qu'une étape d'un pipeline de localisation en plusieurs étapes.
💬 « Nous avons testé les deux modèles avec le même glossaire sur un ensemble de documents juridiques, soit environ 120 000 mots répartis sur huit paires de langues. GPT-4.1 a respecté les contraintes terminologiques presque à la perfection. DeepSeek V3 était proche, mais il substituait occasionnellement un terme préféré par un synonyme proche que nos clients nous avaient spécifiquement demandé d'éviter. À ce volume, « presque » n'est pas suffisant. Pour le contenu non restreint, nous utilisons DeepSeek V3 et les économies sont considérables. Pour tout ce qui concerne un glossaire approuvé par le client, nous utilisons toujours GPT-4.1.
— Gestionnaire de localisation sur MachineTranslation.com
Coût et déploiement : Quels changements à grande échelle
Le coût est l'endroit où les deux modèles divergent le plus nettement, et où l'évaluation doit tenir compte de plus que le prix par jeton.
GPT-4.1 est proposé à un niveau premium. Pour les organisations qui traitent des millions de mots par mois via l'API OpenAI, ce coût s'accumule rapidement. Le modèle n'est pas disponible pour l'auto-hébergement, ce qui signifie que chaque jeton entraîne des frais d'API qui ne peuvent pas être réduits par des investissements en infrastructure.
Le profil de coût de DeepSeek V3 est fondamentalement différent. Via l'API DeepSeek, c'est considérablement moins cher par jeton que GPT-4.1. Auto-hébergé, l'économie change encore davantage : les organisations dotées d'une infrastructure GPU peuvent exécuter DeepSeek V3 à un coût déterminé principalement par la puissance de calcul plutôt que par une licence par jeton. Pour les opérations de traduction à grand volume (catalogues de commerce électronique mondiaux, flux de contenu multilingues, traitement de documents réglementaires), la différence peut représenter des centaines de milliers de dollars annuellement à l'échelle de l'entreprise.
La licence open-source de DeepSeek V3 est également importante pour les secteurs sensibles aux données. Les organisations juridiques, financières et de soins de santé qui ne peuvent pas envoyer de documents clients à des API externes peuvent déployer DeepSeek V3 sur leurs propres serveurs. GPT-4.1 n'offre aucune option équivalente.
La règle de décision est relativement simple : si votre charge de travail est importante, si vos paires de langues sont bien prises en charge et si vos politiques de gouvernance des données autorisent les services d'API ou le déploiement sur site, DeepSeek V3 offre une qualité compétitive à un coût considérablement inférieur. Si votre charge de travail implique une traduction contrainte, la fidélité de longs documents ou des paires de langues à faibles ressources, la fiabilité de GPT-4.1 pourrait valoir le coût supplémentaire.
Comment tester les deux modèles sans s'engager envers l'un ou l'autre
L'obstacle pratique à la sélection de modèles pour la plupart des équipes de localisation n'est pas la compréhension des points de référence — c'est la difficulté de mettre en place des intégrations API indépendantes avec les deux modèles, de concevoir des conditions de test comparables et d'effectuer une évaluation significative sur votre propre contenu.
MachineTranslation.com élimine cet obstacle. La plateforme exécute GPT-4.1 et DeepSeek V3 côte à côte, donnant aux traducteurs professionnels et aux gestionnaires de localisation la possibilité de soumettre le même texte source aux deux modèles simultanément et de comparer les résultats en temps réel — sans clé API distincte, sans processus d'approvisionnement et sans engagement envers l'un ou l'autre modèle.
C'est important car la performance de référence au niveau du jeu de données ne prédit pas toujours la performance sur votre contenu spécifique. Un modèle qui obtient de bons scores COMET sur le texte d'actualité chinois→anglais du WMT24 peut sous-performer sur la terminologie ou le domaine spécifique de votre entreprise. La seule évaluation pertinente pour la prise de décision est celle menée sur vos propres documents, avec vos propres contraintes, dans vos propres paires de langues.
Le positionnement de MachineTranslation.com en tant que plateforme neutre multi-modèles signifie qu'il n'a aucun intérêt commercial à favoriser ni GPT-4.1 ni DeepSeek V3. Le rôle de la plateforme est de vous fournir les données de comparaison pour que vous puissiez prendre cette décision vous-même, puis d'exécuter le modèle que vous sélectionnez à l'échelle de production une fois l'évaluation terminée. Bien sûr, cela vous donne également la traduction sur laquelle la plupart des modèles d'IA s'accordent comme étant la meilleure traduction par défaut.
Pour les équipes qui évaluent également les modèles de la gamme OpenAI, la comparaison de GPT-4.1 avec d'autres modèles OpenAI (y compris GPT-4.5 et GPT-4o) fournit un contexte utile avant de s'engager sur une version de modèle. Et pour les équipes qui ont évalué la comparaison entre DeepSeek V3 et GPT-4o plus tôt en 2025, cet article couvre ce qui a changé avec la sortie de GPT-4.1. Quel modèle devriez-vous choisir pour votre flux de travail de traduction ?
Plutôt qu'une seule recommandation, le cadre suivant reflète
la logique de décision que la plupart des équipes de traduction professionnelles trouveront utile : commencez par vos paires
-
de langues. Si votre portefeuille est concentré sur le chinois↔anglais, l'arabe ou le coréen, les performances de DeepSeek V3 au WMT24 en font le premier test naturel. Si vous travaillez principalement avec des langues européennes et une terminologie restreinte, GPT-4.1 est susceptible de produire des résultats plus cohérents dès le premier jour.
-
Évaluez la complexité de vos contraintes. Les contraintes de niveau unique (un glossaire, un registre) sont gérées adéquatement par l'un ou l'autre modèle. Contraintes à plusieurs niveaux (glossaire + format + liste de non-traduction + notation QA), GPT-4.1 est plus fiable à l'heure actuelle.
-
Mappez votre volume par rapport à la différence de coût. En deçà de 500 000 mots par mois, la différence de coût absolu de l’API pourrait ne pas avoir d’incidence notable sur votre budget. Au-delà de ce seuil, l'avantage de coût de DeepSeek V3 devient de plus en plus difficile à ignorer.
-
Tenez compte de vos exigences en matière de gouvernance des données. Si les documents ne peuvent pas quitter votre infrastructure, DeepSeek V3 auto-hébergé est actuellement la seule option viable des deux.
-
Effectuez l'évaluation sur votre contenu, pas sur des points de référence. Utilisez MachineTranslation.com pour soumettre des échantillons représentatifs de votre charge de travail réelle aux deux modèles et évaluer les résultats selon vos propres critères de qualité avant de vous engager.
Pour une vue d'ensemble de la place de ces modèles dans le paysage actuel de la traduction par IA, les meilleurs outils de traduction par IA en 2026 couvrent l'ensemble du marché concurrentiel, y compris la comparaison des LLM avec l'infrastructure de traduction spécialisée.
Questions fréquemment posées
1. GPT-4.1 est-il meilleur que DeepSeek V3 pour la traduction ?
Aucun des deux modèles n'est universellement meilleur. GPT-4.1 surpasse DeepSeek V3 dans les tâches de traduction contraintes, la fidélité des longs documents et les paires de langues à faibles ressources où le risque d'hallucination est plus élevé. DeepSeek V3 égale ou surpasse GPT-4.1 sur plusieurs points de référence WMT24 (en particulier chinois↔anglais, arabe et coréen) et est considérablement moins cher à exécuter à grande échelle ou auto-hébergé.
2. Est-ce que DeepSeek V3 hallucine plus que GPT-4.1?
Sur les paires de langues à ressources élevées, la différence d'hallucination est relativement faible. L'écart se creuse sur les paires à faibles ressources et le contenu spécifique à un domaine avec des entités nommées rares, où DeepSeek V3 a montré des taux plus élevés d'ajouts ou de substitutions non pris en charge par la source. GPT-4.1 démontre moins d'hallucinations que GPT-4o, particulièrement sur les documents plus longs.
3. Puis-je utiliser DeepSeek V3 commercialement ?
Oui. DeepSeek V3 est publié sous la licence MIT, qui autorise l'utilisation commerciale, y compris le réglage fin et l'auto-hébergement. Les organisations qui ne peuvent pas envoyer de documents à des API externes peuvent déployer DeepSeek V3 sur leur propre infrastructure. GPT-4.1 nécessite l'utilisation de l'API OpenAI conformément aux conditions d'utilisation d'OpenAI et n'est pas disponible pour l'auto-hébergement.
4. Quel modèle est le meilleur pour la traduction du chinois vers l'anglais ?
DeepSeek V3 a un avantage sur le chinois↔anglais, selon les résultats de référence de WMT24. Cependant, pour la traduction du chinois vers l'anglais impliquant une terminologie restreinte, une précision juridique ou une mise en forme complexe, la capacité de GPT-4.1 à suivre les instructions le rend plus fiable dans les flux de travail de production où un traducteur humain effectuera la révision du résultat.
5. Puis-je tester GPT-4.1 et DeepSeek V3 côte à côte avant de choisir ?
Oui — MachineTranslation.com exécute les deux modèles simultanément (et plus de 20 autres) et vous permet de comparer les résultats sur votre propre contenu en temps réel, sans comptes API distincts ni processus d'approvisionnement.
6. Comment DeepSeek V3 se compare-t-il à Claude pour la traduction ?
Pour les équipes qui évaluent également le modèle d'Anthropic, la comparaison Claude vs DeepSeek V3 couvre les principales différences en matière d'architecture, de précision et d'options de déploiement dans des scénarios pertinents pour la traduction.