June 10, 2026
GPT-4.1 vs DeepSeek V3: Accuratezza, allucinazione e prestazioni di traduzione a confronto
La domanda che la maggior parte dei team di traduzione si pone in silenzio a metà 2026 non è dovremmo usare l'IA?, quella decisione è già stata presa. La vera domanda è su quale modello di IA standardizzare, e se la risposta è la stessa per ogni coppia linguistica, ogni tipo di documento e ogni budget.
GPT-4.1 e DeepSeek V3 sono emersi come le due opzioni più frequentemente valutate per i flussi di lavoro di traduzione professionale. Rappresentano filosofie genuinamente diverse: una è un'API strettamente governata e commercialmente rifinita di OpenAI; l'altra è un modello open-weight con licenza MIT da un laboratorio di ricerca cinese che ha superato silenziosamente diversi concorrenti proprietari nei benchmark WMT24. Nessuno dei due è universalmente migliore. Il caso di ciascuno dipende da ciò che si sta traducendo, per chi e a quali condizioni.
Questo articolo analizza entrambi i modelli secondo le dimensioni che contano di più per traduttori, responsabili della localizzazione e acquirenti aziendali: accuratezza su coppie linguistiche reali, comportamento di allucinazione, gestione di attività vincolate come l'aderenza al glossario e il costo totale di esecuzione di entrambi su larga scala.
Indice dei contenuti
- Perché questo confronto è importante in questo momento
- Cos'è effettivamente ciascun modello
- Confronto diretto: Accuratezza della traduzione e prestazioni di riferimento
- Quale modello delira di più e quando?
- Quale modello gestisce meglio la traduzione vincolata?
- Costi e implementazione: Cosa cambia su larga scala
- Come testare entrambi i modelli senza impegnarsi in nessuno dei due
- Quale modello scegliere per il tuo flusso di lavoro di traduzione?
- Domande frequenti
- Confronti correlati
Perché questo confronto è importante in questo momento
Gli acquirenti di traduzioni hanno storicamente valutato la traduzione automatica su un asse ristretto: Punteggio BLEU rispetto al prezzo. I LLM rompono completamente quella cornice. GPT-4.1 e DeepSeek V3 non sono motori di traduzione automatica (MT) in senso tradizionale: sono modelli di uso generale con forti capacità multilingue e le loro prestazioni nei compiti di traduzione variano a seconda dell'architettura, dei dati di addestramento e del modo in cui li si interroga.
Questa variabilità è il fulcro del problema di valutazione. Un responsabile della localizzazione che testa entrambi i modelli su testi di marketing dall'inglese allo spagnolo potrebbe riscontrare una qualità dell'output quasi identica. Lo stesso manager che testa documenti legali dall'arabo all'inglese probabilmente vedrà un divario significativo, ma quale modello risulterà migliore dipende dal fatto che il documento contenga entità nominate, gergo tecnico o riferimenti culturali che richiedono conoscenza del mondo piuttosto che riconoscimento di schemi.
Anche la posta in gioco è asimmetrica. DeepSeek V3 è ordini di grandezza più economico da eseguire, specialmente se self-hosted. GPT-4.1 comporta un significativo sovrapprezzo. Se entrambi i modelli forniscono una qualità accettabile sul tuo specifico carico di lavoro, la differenza di costo può determinare se un flusso di lavoro di traduzione AI è economicamente sostenibile su larga scala.
Cos'è effettivamente ciascun modello
GPT-4.1: Il modello di punta di OpenAI ottimizzato per le istruzioni
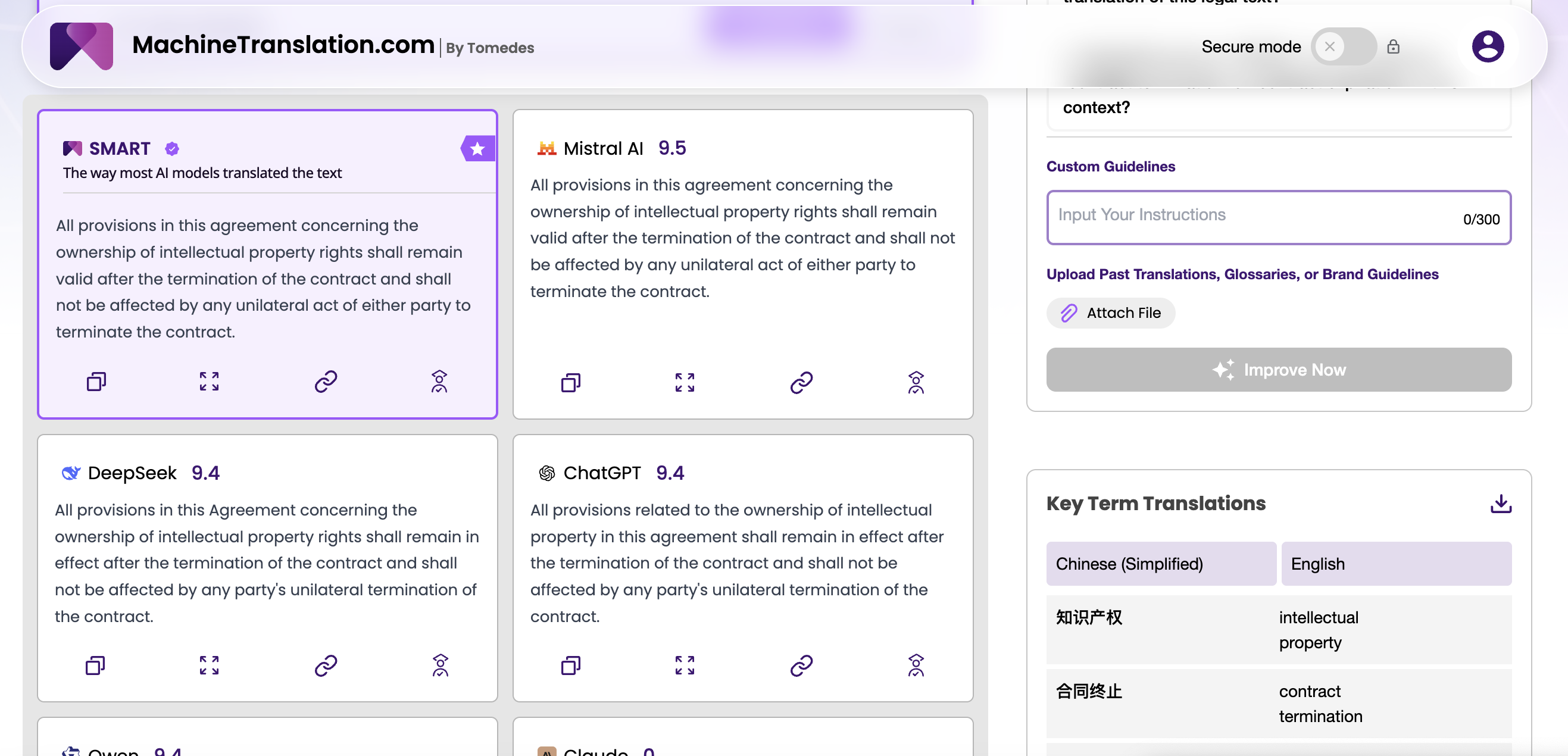
Rilasciato nell'aprile 2025, GPT-4.1 è il modello di OpenAI più aderente alle istruzioni fino ad oggi. I suoi miglioramenti principali rispetto a GPT-4o non riguardano la fluidità della traduzione grezza (era già forte in questo) ma la precisione nel seguire istruzioni complesse e multipartite. Per i flussi di lavoro di traduzione, questo è particolarmente importante in attività vincolate: applicare un glossario del cliente, preservare la formattazione del documento in testi lunghi, mantenere un registro specifico o aderire a un elenco di elementi da non tradurre.
GPT-4.1 supporta una finestra di contesto di un milione di token, il che significa che può elaborare documenti lunghi come libri in un'unica chiamata. Nelle attività di output strutturato (generazione di memorie di traduzione in JSON, produzione di punteggi di qualità a livello di segmento insieme alla traduzione, formattazione di tabelle bilingui), è dimostrabilmente più affidabile dei suoi predecessori. Il compromesso è il costo: GPT-4.1 si posiziona in una fascia di prezzo superiore rispetto alla maggior parte delle alternative, incluso DeepSeek V3.
DeepSeek V3: Il sfidante open-source
DeepSeek V3 (la versione di produzione attuale è DeepSeek-V3-0324) è un modello da 685 miliardi di parametri costruito su un'architettura Mixture-of-Experts, il che significa che solo un sottoinsieme dei suoi parametri si attiva per un dato input, mantenendo bassi i costi di inferenza nonostante l'enorme numero totale di parametri. È rilasciato sotto licenza MIT, il che significa che le organizzazioni possono auto-ospitarlo, affinarlo e distribuirlo commercialmente senza costi per token a terzi.
Le prestazioni di traduzione del modello hanno attirato notevole attenzione dopo il WMT24, dove ha ottenuto punteggi BLEU e COMET elevati per le coppie linguistiche cinese↔inglese, arabo e coreano, in diversi casi superando GPT-4o. Per i team che lavorano intensamente con coppie di lingue asiatiche o mediorientali, DeepSeek V3 non è una scelta di compromesso. È veramente competitivo a una frazione del costo.
Testa a testa: Accuratezza della traduzione e prestazioni di riferimento
| Dimensione | GPT-4.1 | DeepSeek V3 |
|---|---|---|
| Finestra di contesto | 1.000.000 token | ~64.000 token (standard) |
| Architettura | Transformer denso | Mixture-of-Experts (685B parametri) |
| Licenza | Proprietaria | Open-source (MIT) |
| Self-hosting | Non disponibile | Disponibile |
| WMT24 Cinese↔Inglese | Forte | Molto forte, ha superato GPT-4o su diverse coppie |
| Traduzione araba WMT24 | Competitivo | Forte, specialmente su testi specializzati |
| Seguire le istruzioni | Il migliore della categoria rispetto a GPT-4o | Buono; meno coerente su prompt complessi multi-step |
| Output strutturato | Altamente affidabile | Affidabile; lieve deriva di formattazione su output lunghi |
| Tendenza all'allucinazione | Ridotta rispetto a GPT-4o | Occasionale su coppie a basse risorse |
| Costo API relativo | Più alto | Significativamente più basso |
Sull'accuratezza generale della traduzione per coppie di lingue ad alta risorsa (inglese, francese, spagnolo, tedesco, cinese, giapponese), entrambi i modelli offrono prestazioni che i traduttori professionisti descrivono come pronte per la post-edizione. Il divario tra loro in termini di fluidità e adeguatezza da solo non è abbastanza ampio da guidare una decisione di acquisto per la maggior parte dei team.
Le differenze significative emergono in tre scenari specifici: lingue a basse risorse, attività con vincoli e tipi di documenti inclini all'allucinazione.
Quale modello allucina di più e quando?
L'allucinazione nella traduzione non è la stessa cosa dell'allucinazione nella generazione di scopi generali. Il modello sta lavorando da un testo di origine, non sta inventando fatti dal nulla. L'allucinazione qui si manifesta come contenuto aggiunto non presente nell'origine, clausole o entità nominate omesse o sostituite. In una traduzione legale o medica, uno qualsiasi di questi errori può avere conseguenze serie.
GPT-4.1 mostra un tasso di allucinazione misurabilmente inferiore rispetto a GPT-4o, in particolare su documenti lunghi dove i modelli OpenAI precedenti iniziavano a discostarsi dalla fonte nei segmenti successivi. La combinazione di una finestra di contesto da un milione di token e un miglioramento nell'esecuzione delle istruzioni significa che GPT-4.1 mantiene la fedeltà alla sorgente più a lungo senza richiedere strategie di prompting speciali. Per gli acquirenti aziendali che elaborano dichiarazioni normative, documentazione di prodotto o contratti, questo rappresenta un significativo miglioramento dell'affidabilità.
Il profilo di allucinazione di DeepSeek V3 è diverso per natura. Sulle coppie linguistiche ben supportate (cinese, inglese, arabo), è generalmente affidabile. Il rischio aumenta sulle coppie a basse risorse: Coreano→Swahili, Arabo→Vietnamita, o qualsiasi coppia in cui una lingua è sottorappresentata nel corpus di addestramento. In questi casi, è stato osservato che DeepSeek V3 genera contenuti plausibili ma non supportati dalla fonte, in particolare quando la fonte contiene entità nominate ambigue o terminologia specifica del dominio.
L'implicazione pratica: se il tuo portafoglio di coppie linguistiche è concentrato su lingue ad alta risorsa, il rischio di allucinazione di DeepSeek V3 è gestibile con i processi QA standard. Se stai eseguendo traduzioni su larga scala per coppie a basse risorse, l'affidabilità aggiuntiva di GPT-4.1 potrebbe giustificare il sovrapprezzo.
💬 Ciò che vediamo costantemente sulla piattaforma è che il divario tra GPT-4.1 e DeepSeek V3 sulle allucinazioni non riguarda il volume, ma dove si verificano. Sui contenuti in inglese, francese o spagnolo, la maggior parte dei traduttori professionisti non noterebbe una differenza significativa in termini di affidabilità. I problemi con DeepSeek V3 tendono a emergere su documenti coreani o arabi che contengono nomi propri sconosciuti o terminologia altamente specifica del dominio. GPT-4.1 gestisce questi casi limite in modo più conservativo, è meno probabile che colmi una lacuna con qualcosa di plausibile.
— Linguist on MachineTranslation.com
Quale modello gestisce meglio la traduzione vincolata?
La traduzione vincolata (in cui il modello deve rispettare un glossario, mantenere un registro di marca, evitare di tradurre determinati termini o preservare la struttura del documento come intestazioni e note a piè di pagina) è dove i vantaggi architetturali di GPT-4.1 diventano più tangibili.
Quando si fornisce un prompt di sistema con un glossario di 200 termini e si istruisce il modello a segnalare qualsiasi segmento di origine in cui non è possibile trovare una corrispondenza esatta, GPT-4.1 segue tali istruzioni con una coerenza che i modelli precedenti non potevano sostenere oltre poche centinaia di token. In una finestra di contesto di un milione di token, ciò significa che puoi tradurre un manuale tecnico di 400 pagine con un vincolo di terminologia complessa in una singola chiamata e aspettarti un'applicazione coerente del glossario in tutto il testo.
DeepSeek V3 gestisce adeguatamente i vincoli diretti: istruzioni di non traduzione per termini singoli, preferenze di registro di base, regole di formattazione semplici. Dove sottoperforma è in set di istruzioni complessi e composti. Man mano che il numero di vincoli simultanei aumenta, DeepSeek V3 inizia a dare priorità ad alcune istruzioni rispetto ad altre in modi difficili da prevedere senza test. Per i team di localizzazione che gestiscono guide di stile multilivello e ampie memorie di traduzione, questa incoerenza crea un sovraccarico di QA a valle che compensa parzialmente il vantaggio di costo del modello.
Per la traduzione pura e illimitata di contenuti standard (comunicazioni aziendali generali, testi di marketing, descrizioni di prodotti e-commerce), il divario nella gestione dei vincoli tra i due modelli è in gran parte irrilevante. La differenza conta di più per i team che gestiscono flussi di lavoro di livello enterprise in cui la traduzione è un passaggio in una pipeline di localizzazione multi-fase.
💬 Abbiamo eseguito entrambi i modelli sullo stesso glossario su un set di documenti legali, circa 120.000 parole in otto coppie di lingue. GPT-4.1 ha rispettato quasi perfettamente i vincoli terminologici. DeepSeek V3 ci è andato vicino, ma occasionalmente sostituiva un termine preferito con un sinonimo vicino che i nostri clienti ci avevano specificamente chiesto di evitare. A quel volume, quasi non basta. Per contenuti non vincolati, utilizziamo DeepSeek V3 e i risparmi sui costi sono significativi. Per tutto ciò che ha un glossario approvato dal cliente, stiamo ancora eseguendo GPT-4.1.
— Localization Manager su MachineTranslation.com
Costo e implementazione: Cosa cambia su larga scala
Il costo è dove i due modelli divergono maggiormente, e dove la valutazione deve tenere conto di più del prezzo per token.
GPT-4.1 è prezzato in una fascia premium. Per le organizzazioni che elaborano milioni di parole al mese tramite l'API OpenAI, quel costo si accumula rapidamente. Il modello non è disponibile per l'auto-hosting, il che significa che ogni token comporta una commissione API che non può essere ridotta tramite investimenti in infrastrutture.
Il profilo di costo di DeepSeek V3 è fondamentalmente diverso. Tramite l'API DeepSeek, è significativamente più economico per token rispetto a GPT-4.1. Auto-ospitato, l'economia cambia ulteriormente: le organizzazioni con infrastruttura GPU possono eseguire DeepSeek V3 a un costo determinato principalmente dal calcolo piuttosto che dalle licenze per token. Per le operazioni di traduzione ad alto volume (cataloghi di e-commerce globali, pipeline di contenuti multilingue, elaborazione di documenti normativi), la differenza può rappresentare centinaia di migliaia di dollari all'anno su scala aziendale.
Anche la licenza open-source di DeepSeek V3 è importante per i settori sensibili ai dati. Organizzazioni legali, finanziarie e sanitarie che non possono inviare documenti ai clienti ad API esterne possono distribuire DeepSeek V3 on-premises. GPT-4.1 non offre un'opzione equivalente.
La regola decisionale è relativamente chiara: se il tuo carico di lavoro è elevato, le tue coppie linguistiche sono ben supportate e le tue policy di governance dei dati consentono servizi API o distribuzione on-premises, DeepSeek V3 offre una qualità competitiva a un costo notevolmente inferiore. Se il tuo carico di lavoro prevede traduzioni vincolate, fedeltà di documenti lunghi o coppie linguistiche a basse risorse, l'affidabilità di GPT-4.1 potrebbe valere il sovrapprezzo.
Come testare entrambi i modelli senza impegnarsi con nessuno dei due
L'ostacolo pratico alla selezione del modello per la maggior parte dei team di localizzazione non è la comprensione dei benchmark, ma l'attrito nell'impostare integrazioni API indipendenti con entrambi i modelli, progettare condizioni di test comparabili ed eseguire una valutazione significativa sui propri contenuti.
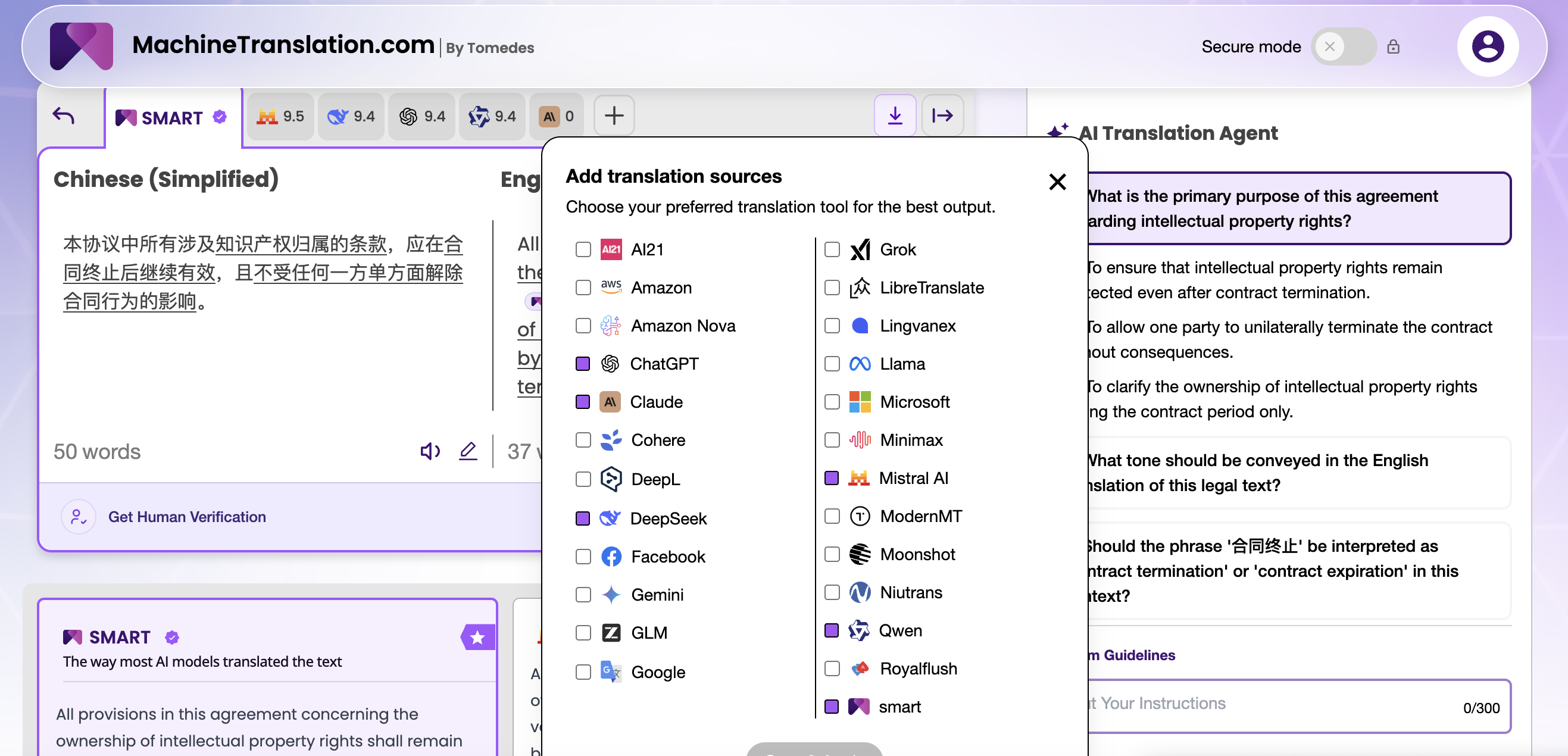
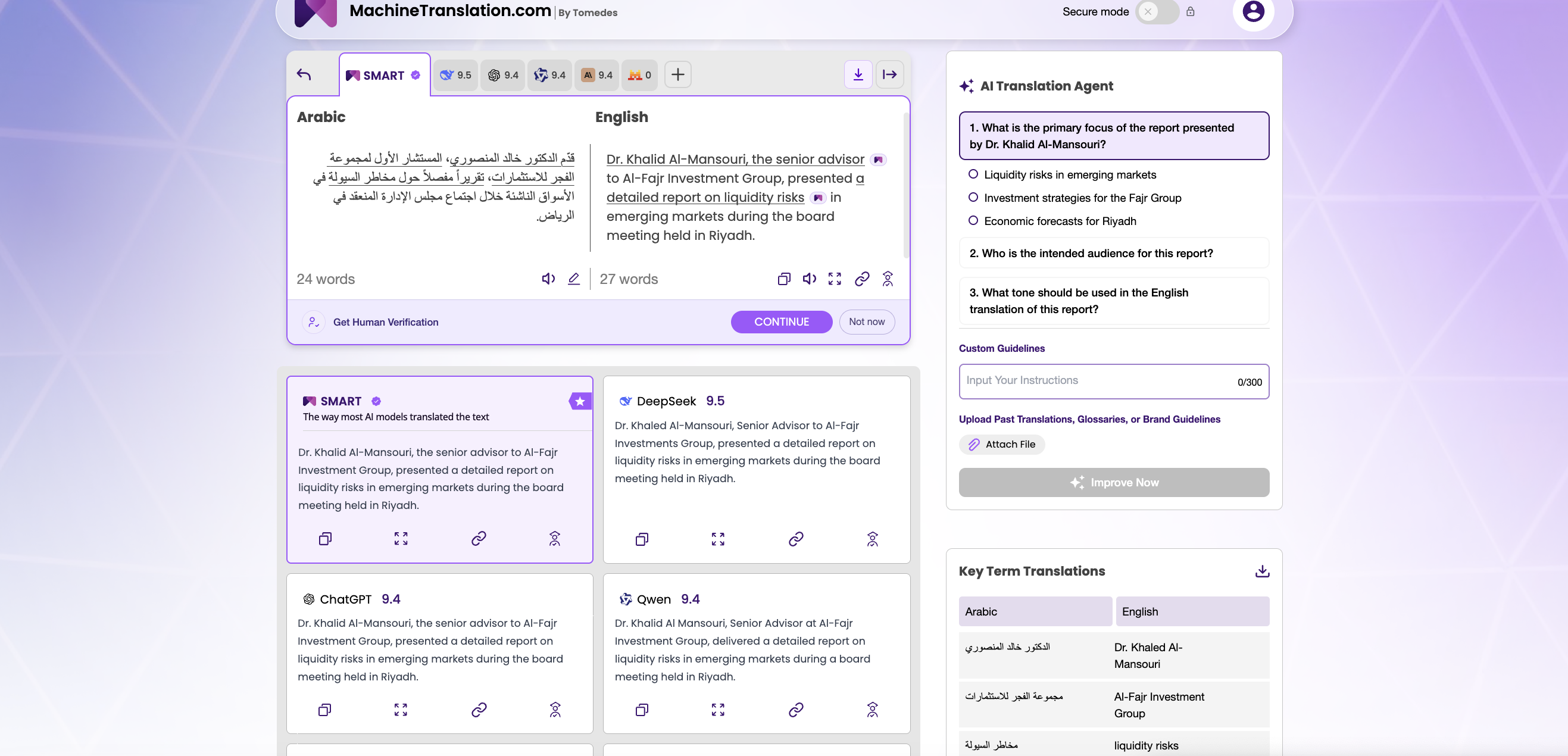
MachineTranslation.com rimuove questo ostacolo. La piattaforma esegue GPT-4.1 e DeepSeek V3 fianco a fianco, dando ai traduttori professionisti e ai responsabili della localizzazione la possibilità di inviare lo stesso testo sorgente a entrambi i modelli contemporaneamente e confrontare gli output in tempo reale, senza una chiave API separata, senza un processo di approvvigionamento e senza impegnarsi con nessuno dei due modelli.
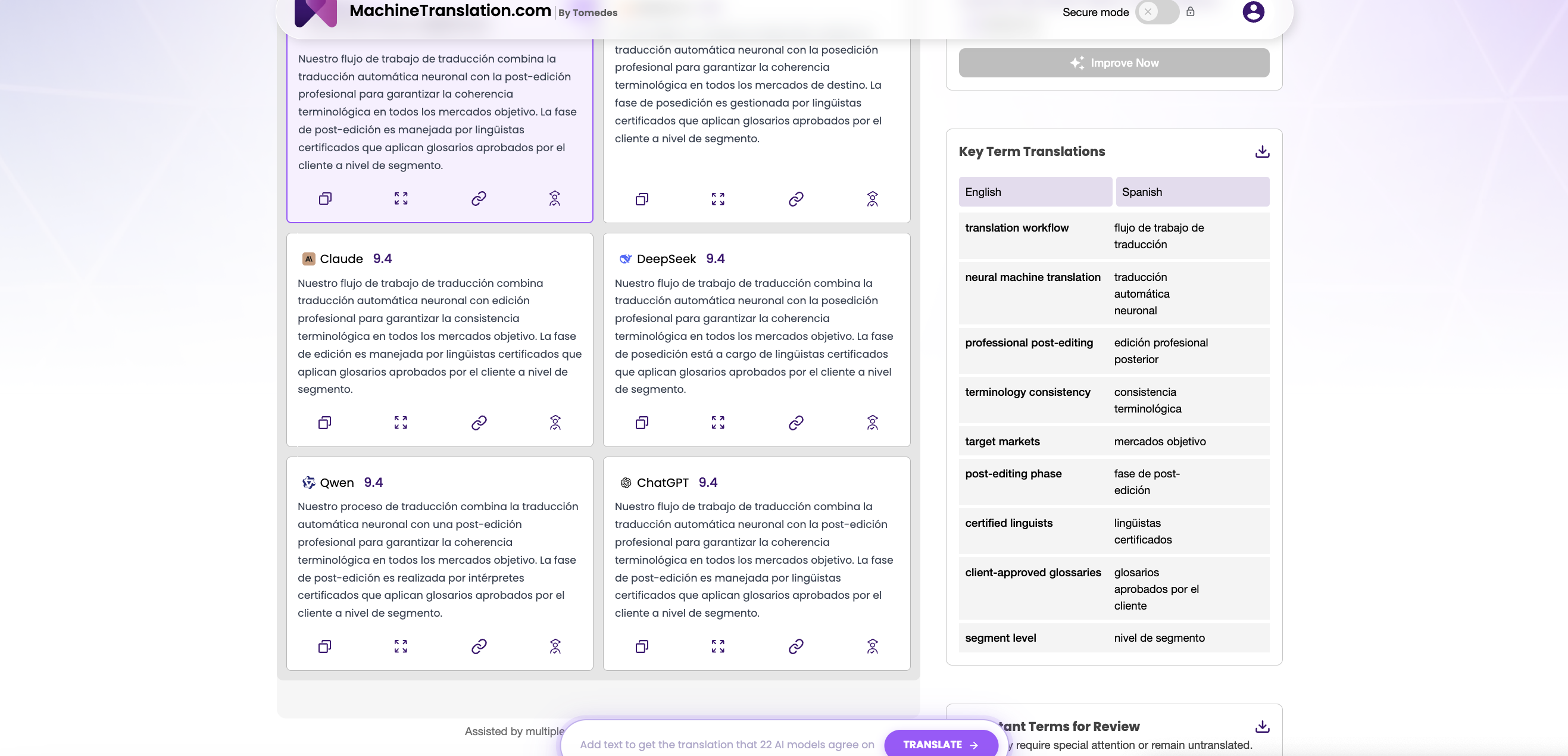
Questo è importante perché le prestazioni di riferimento a livello di set di dati non sempre prevedono le prestazioni sul tuo contenuto specifico. Un modello che ottiene punteggi COMET elevati su testi di notizie cinesi→inglesi del WMT24 potrebbe sottoperformare sulla terminologia o sul dominio specifici della tua azienda. L'unica valutazione pertinente per le decisioni è quella condotta sui propri documenti, con i propri vincoli, nelle proprie coppie linguistiche.
La posizione di MachineTranslation.com come piattaforma neutrale multi-modello significa che non ha incentivi commerciali a favorire né GPT-4.1 né DeepSeek V3. Il ruolo della piattaforma è fornirti i dati di confronto per prendere tu stesso quella decisione, e quindi eseguire il modello che selezioni su scala di produzione una volta completata la valutazione. Sebbene ovviamente ti dia anche la traduzione su cui la maggior parte dei modelli AI concorda come traduzione migliore predefinita.
Per i team che valutano anche tra i livelli di modelli OpenAI, il confronto tra GPT-4.1 e altri modelli OpenAI (inclusi GPT-4.5 e GPT-4o) fornisce un contesto utile prima di impegnarsi in una versione del modello. E per i team che hanno valutato come DeepSeek V3 si confronta con GPT-4o all'inizio del 2025, questo articolo copre cosa è cambiato con il rilascio di GPT-4.1. Quale modello dovresti scegliere per il tuo flusso di lavoro di traduzione?
Piuttosto che una singola raccomandazione, il seguente
framework riflette la logica decisionale che la maggior parte dei team di traduzione professionali troverà utile: Inizia con le tue
-
coppie linguistiche. Se il tuo portafoglio è concentrato in cinese↔inglese, arabo o coreano, le prestazioni di DeepSeek V3 al WMT24 lo rendono il primo test naturale. Se stai lavorando principalmente in lingue europee con terminologia vincolata, GPT-4.1 è probabile che produca risultati più coerenti fin dal primo giorno.
-
Valuta la complessità dei tuoi vincoli. I vincoli a livello singolo (un glossario, un registro) sono gestiti adeguatamente da entrambi i modelli. Vincoli multilivello (glossario + formato + elenco do-not-translate + punteggio QA), GPT-4.1 è più affidabile al momento.
-
Mappa il tuo volume rispetto al differenziale di costo. Sotto le 500.000 parole al mese, la differenza assoluta nel costo dell'API potrebbe non influire materialmente sul tuo budget. Oltre quella soglia, il vantaggio di costo di DeepSeek V3 diventa sempre più difficile da ignorare.
-
Considera i tuoi requisiti di governance dei dati. Se i documenti non possono lasciare la tua infrastruttura, DeepSeek V3 self-hosted è attualmente l'unica opzione praticabile tra le due.
-
Esegui la valutazione sui tuoi contenuti, non sui benchmark. Utilizza MachineTranslation.com per inviare campioni rappresentativi del tuo carico di lavoro effettivo a entrambi i modelli e valuta gli output in base ai tuoi criteri di qualità prima di impegnarti.
Per una visione più ampia di dove si collocano questi modelli nel panorama attuale della traduzione AI, i migliori strumenti di traduzione AI nel 2026 coprono l'intero campo competitivo, incluso il confronto tra LLM e infrastrutture di traduzione dedicate.
Domande frequenti
1. GPT-4.1 è migliore di DeepSeek V3 per la traduzione?
Nessuno dei due modelli è universalmente migliore. GPT-4.1 supera DeepSeek V3 nelle attività di traduzione vincolate, nella fedeltà dei documenti lunghi e nelle coppie linguistiche a basse risorse dove il rischio di allucinazione è maggiore. DeepSeek V3 eguaglia o supera GPT-4.1 su diversi benchmark WMT24 (in particolare cinese↔inglese, arabo e coreano) ed è significativamente più economico da eseguire su larga scala o in self-hosting.
2. DeepSeek V3 hallucina di più di GPT-4.1?
Sulle coppie linguistiche ad alte risorse, la differenza di allucinazione è relativamente piccola. Il divario si allarga su coppie a basse risorse e contenuti specifici del dominio con entità nominate rare, dove DeepSeek V3 ha mostrato tassi più elevati di aggiunte o sostituzioni non supportate dalla sorgente. GPT-4.1 dimostra una ridotta allucinazione rispetto a GPT-4o, in particolare su documenti più lunghi.
3. Posso usare DeepSeek V3 commercialmente?
Sì. DeepSeek V3 è rilasciato sotto licenza MIT, che ne consente l'uso commerciale, inclusi il fine-tuning e l'auto-hosting. Le organizzazioni che non possono inviare documenti a API esterne possono distribuire DeepSeek V3 sulla propria infrastruttura. GPT-4.1 richiede l'uso dell'API OpenAI secondo i termini di servizio di OpenAI e non è disponibile per l'auto-hosting.
4. Quale modello è migliore per la traduzione dal cinese all'inglese?
DeepSeek V3 ha un vantaggio sul cinese↔inglese in base ai risultati del benchmark WMT24. Tuttavia, per la traduzione cinese→inglese che coinvolge terminologia vincolata, precisione legale o formattazione complessa, la capacità di seguire le istruzioni di GPT-4.1 lo rende più affidabile nei flussi di lavoro di produzione in cui un traduttore umano post-editerà l'output.
5. Posso testare GPT-4.1 e DeepSeek V3 fianco a fianco prima di scegliere?
Sì — MachineTranslation.com esegue entrambi i modelli contemporaneamente (e oltre 20 altri) e ti consente di confrontare gli output sul tuo contenuto in tempo reale, senza account API separati o un processo di approvvigionamento.
6. Come si confronta DeepSeek V3 con Claude per la traduzione?
Per i team che valutano anche il modello di Anthropic, il confronto Claude vs DeepSeek V3 copre le principali differenze in termini di architettura, accuratezza e opzioni di distribuzione in scenari rilevanti per la traduzione.