May 22, 2026
Claude vs DeepL för översättning: Vilken är egentligen bäst?
Här är den ärliga utgångspunkten: Claude och DeepL konkurrerar egentligen inte om samma användare.
DeepL byggdes för översättning. Det har förfinat en sak (att konvertera text från ett språk till ett annat med naturligt klingande flyt) sedan 2017. Claude är en allmän modell för resonemang utvecklad av Anthropic som råkar översätta exceptionellt bra, särskilt när innehållet är långt, komplext eller kräver djup kontextuell tolkning.
Frågan Claude vs DeepL är viktig för personer som verkligen bestämmer hur de ska hantera professionellt översättningsarbete och vill ha ett klart svar, inte en marknadsföringsjämförelse. Det är vad den här artikeln syftar till att vara.
I den här artikeln
- Vad varje verktyg är byggt för att göra
- Hur jämförs Claude och DeepL när det gäller noggrannhet?
- Där DeepL har en verklig fördel
- Där Claude drar ifrån
- Språktäckning och dokumenthantering
- Prissättning: Vad du faktiskt betalar
- Vilken ska du använda?
- Vad händer när du kör båda samtidigt
- Vanliga frågor
Vad varje verktyg byggdes för att göra
Claude: en resonemangsmodell som används för översättning

Claude är utvecklad av Anthropic och är i grunden en stor språkmodell designad för resonemang, analys och generering över ett brett spektrum av uppgifter. Översättning är en av de uppgifter, och det visar sig att Claude är ganska bra på det – särskilt för innehåll där den omgivande kontexten avgör meningen: juridiska dokument, litterära texter, tekniska specifikationer och allt där en enskild mening inte kan förstås isolerat.
Den nuvarande Claude 4-familjen (Claude Opus 4 och Claude Sonnet 4) har ett kontextfönster på 200 000 tokens, vilket förändrar vad som är möjligt inom översättning. En dokumentöversättare som arbetar segment för segment missar beroenden mellan meningar, inkonsekvenser i karaktärsnamn eller terminologi och tonförändringar mellan kapitel. Claude har inte det problemet. När du matar den med ett helt kontrakt ser den hela kontraktet.
Enligt Intentos State of Translation Automation 2025 rankas Claude Opus 4 och Claude Sonnet 3.7 bland de bäst presterande enagentlösningarna för engelska till tyska, engelska till nederländska, engelska till italienska, engelska till japanska och engelska till koreanska språkpar i både automatiserad och mänsklig LQA-utvärdering.
DeepL: ett verktyg byggt specifikt för översättning

DeepL gör en sak och har optimerat obevekligt för det. Dess neurala maskinöversättningsmotor är tränad specifikt på översättningsrelevant data, och den specialiseringen syns i dess utdata: DeepL-översättningar låter genomgående mer naturliga för europeiska språkpar än de flesta konkurrenter. Fraseringen är idiomatiskt, grammatiken är ren och registret är vanligtvis väl matchat källan.
I MachineTranslation.coms interna riktmärke över 5 000 ord av blandat tekniskt och marknadsföringsinnehåll fick DeepL 94,2 % noggrannhet – den högsta av alla fristående motorer som testades, och beskrevs i riktmärket som kungen av flöde. För specifika europeiska språkpar låter det mest mänskligt.
DeepL lanserade också DeepL next-gen 2024, en specialbyggd LLM för översättning som förbättrar den klassiska modellen för längre texter, och som Intentos utvärdering 2025 placerar bland de bäst presterande realtidslösningarna för flera språkpar, inklusive engelska till spanska, franska, italienska, nederländska, koreanska och portugisiska.
Avvägningen för den specialiseringen: DeepL stöder 33 språk, vilket är smalt. Och det är ett system med en enda modell – utdata du får är DeepLs tolkning, utan någon korsreferenssignal och inget sätt att veta när den har gjort ett val som du kanske inte håller med om.
Hur jämför sig Claude och DeepL när det gäller noggrannhet?
Svaret beror starkt på vad du översätter och till vilket språk.
Europeiska språkpar
För europeiska kärnpar (tyska, franska, spanska, italienska, nederländska, portugisiska) är DeepL next-gen verkligen konkurrenskraftigt. Intentos LQA-utvärdering för 2025 placerar det i toppskiktet för sex av de elva språkpar som utvärderats. Utdata låter naturligt, idiomatiskt och lämpligt formellt utan att kräva någon prompt engineering från användaren.
Claude Opus 4 och Sonnet 3.7 förekommer också i toppskiktet för flera av dessa par, särskilt engelska till tyska och engelska till nederländska, där Claudes kontextuella resonemang hjälper den att hantera morfologisk komplexitet och kasusöverensstämmelse över längre texter.
Den praktiska skillnaden på denna nivå: för kort, standardinnehåll (produktbeskrivningar, formulärfält, UI-kopia) spelar DeepLs hastighetsfördel en roll och dess kvalitet är konsekvent. För längre, mer komplexa innehåll producerar Claudes kontextfönster och resonemangsdjup märkbart starkare resultat.
Långa dokument och kontexthantering
Det är här jämförelsen blir mindre nära.
Enligt MachineTranslation.coms interna analys är de fel som återstår i modern AI-översättning nästan uteslutande semantiska: fel ton, fel register, fel term, missad beroende över meningar. Det här är inte fel som en segment-för-segment-översättning fångar upp. De är fel som bara uppstår när du läser hela dokumentet och märker att en karaktärs titel ändrades tre sidor in, eller att en definierad term återgavs olika i två klausuler.
Claudes kontextfönster på 200 000 tokens innebär att den kan hålla ett helt juridiskt avtal, en teknisk manual eller ett litterärt kapitel i sitt arbetsminne och producera en översättning som är internt konsekvent i hela dokumentet. DeepLs dokumentöversättningsfunktion bearbetar innehåll avsnitt för avsnitt, vilket i allmänhet fungerar bra för strukturerade dokument men kan introducera den typ av drift som Claude undviker genom design.
Tekniskt och domänspecifikt innehåll
Båda verktygen hanterar allmänt tekniskt innehåll ganska bra. För mycket specialiserade områden (juridik, medicin, ekonomi) beror resultaten på hur väl källinnehållet matchar varje verktygs träningsdata.
DeepL tillåter glossarinmatning på betalda API-planer, vilket hjälper till att upprätthålla terminologisk konsekvens. Claude, som används via API eller i en välstrukturerad fråga, kan ta in en hel ordlista som kontext och tillämpa den genomgående. Ingen metod är definitivt bättre; båda kräver förberedande arbete från användaren.
Där DeepL har en verklig fördel
Naturlighet och flyt för europeiska språkpar. När en översättning behöver låta som om den är skriven av en modersmålstalare (marknadsföringstexter, varumärkeskommunikation, konsumentinriktat innehåll), är DeepLs resultat konsekvent bland de mest naturligt klingande som finns tillgängliga. Claude översätter korrekt, men DeepLs utdata, särskilt för EU-språkpar, låter mer idiomatiskt.
Hastighet. DeepL är en NMT-motor optimerad för genomströmning. För högvolymiga, tidskritiska arbetsflöden är det betydligt snabbare än Claude, som arbetar med LLM-hastigheter.
Arbetsflödesintegration. DeepL har ett moget ekosystem: CAT-verktygsplugins, ett väldokumenterat API, glosshantering och toninställningar (formell/informell). Det passar in i professionella översättares arbetsflöden på sätt som Claude, som en generell modell, inte gör naturligt.
Konsekvent utdata för standardinnehåll. För innehåll där översättningsuppgiften är väldefinierad och utdata bara behöver vara tillförlitligt korrekta, tar DeepL bort variabler. Du vet ungefär vad du kommer att få.
Där Claude tar ledningen
Långa, kontextuellt komplexa dokument. Ett 40-sidigt kontrakt, ett litterärt kapitel, en teknisk specifikation i flera avsnitt – Claude bearbetar hela saken på en gång och upprätthåller konsekvens genom den på ett sätt som segment-för-segment-översättning inte kan åstadkomma.
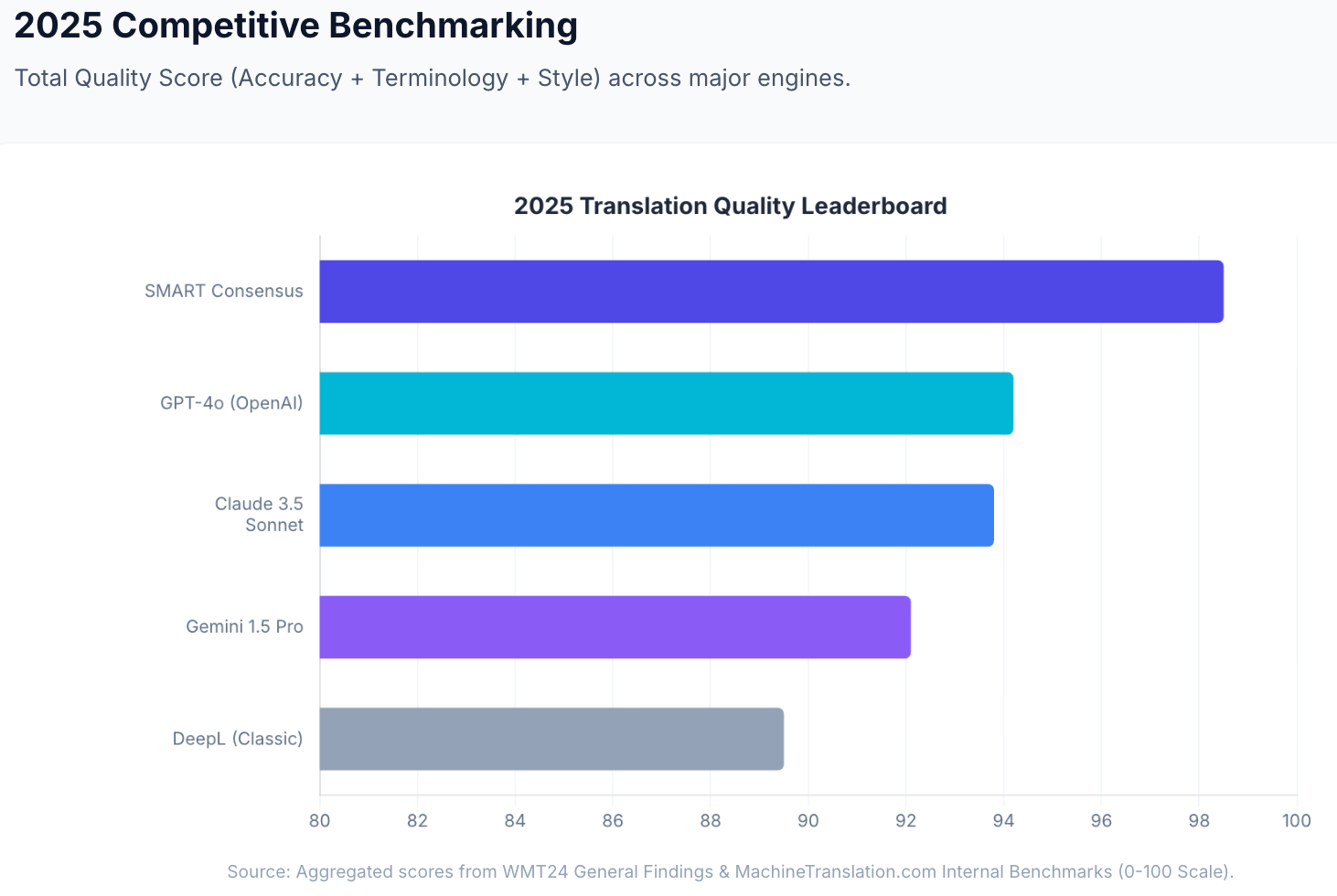
Nyans och register. Claude 3.5 Sonnet fick 93,8 av 100 i MachineTranslation.coms interna kvalitetsbenchmark och presterade särskilt bra på innehåll där tonen spelar roll: översättningar av varumärkesröster, intressentkommunikation och professionell korrespondens där tekniskt korrekt inte räcker.
 {4}
{4}Flerspråkig bredd. Claude stöder ett mycket bredare utbud av språk än DeepLs 33. För team som arbetar utanför DeepLs kärntäckning i Europa fyller Claude ett verkligt gap.
Resonemang om texten. Om du inte bara översätter utan också ber modellen att anpassa innehållet för en annan publik, justera register eller flagga kulturellt olämpliga fraser, gör Claude detta som en del av samma uppgift. DeepL översätter. Claude tycker också.
Språktäckning och dokumenthantering
| Claude (Opus 4 / Sonnet 4) | DeepL (Classic + next-gen) | |
|---|---|---|
| Språk som stöds | Brett flerspråkigt (100+) | 33 språk |
| Kontextfönster | Upp till 200 000 tokens | Segment för segment |
| Dokumentformat | Via API eller filuppladdning | PDF, DOCX, PPTX, XLSX |
| Layoutbevarande | Begränsat | Starkt (ursprunglig formatering bevarad) |
| Filstorlek | Beror på antalet tokens | Upp till 30 MB på högre planer |
| Ordlistestöd | Via prompt / API | Inbyggd ordlistefunktion |
| CAT-verktygsintegration | Nej | Ja (stöd för större CAT-verktyg) |
En praktisk notering om dokument: DeepL bevarar den ursprungliga formateringen när DOCX- och PDF-filer översätts, vilket är verkligen användbart för affärsdokument där omformatering efter översättning är tidskrävande. Claudes dokumentöversättning via API bevarar inte layouten på samma sätt, vilket är viktigt för allt som ska distribueras direkt utan efterbehandling.
Prissättning: Vad du faktiskt betalar
Claude (via Anthropic API):
- Claude Sonnet 4: $3.00 per miljon input-tokens / $15.00 per miljon output-tokens
- Claude Opus 4: $15.00 per miljon input-tokens / $75.00 per miljon output-tokens
- Via Claude.ai: Gratisnivå tillgänglig med användningsgränser; Pro-plan för $20/månad
DeepL:
- Gratis: begränsat antal tecken, 3 icke-redigerbara dokumentöversättningar per månad
- Starter: ~10,49 $/användare/månad
- Advanced: ~34,49 $/användare/månad
- Ultimate: ~68,99 $/användare/månad
- API Pro: $25 per miljon tecken
För de flesta enskilda professionella användare är DeepLs prenumerationsprissättning mer förutsägbar. För API-intensiva arbetsflöden beror jämförelsen på volymen: Claudes pris per token skalas annorlunda än DeepLs modell per tecken, och vid hög volym kan skillnaden gå åt båda hållen beroende på genomsnittlig dokumentlängd och översättningsriktning.
Vilken ska du använda?
Valet beror på vad du översätter, inte vilket verktyg som objektivt sett är bäst.
| Användningsområde | Bättre val |
|---|---|
| Marknadsföringstexter, konsumentinriktat EU-innehåll | DeepL |
| Långa juridiska eller tekniska dokument som kräver konsekvens | Claude |
| UI-strängar, produktbeskrivningar i volym | DeepL |
| Litterär översättning eller översättning av varumärkesröst | Claude |
| Språk utanför DeepLs 33 som stöds | Claude |
| Arbetsflöde med CAT-verktyg eller TMS-integration | DeepL |
| Innehåll som kräver formatering | DeepL |
| Komplex flerspråkig resonemang eller anpassning | Claude |
| Snabb standardöversättning med hög volym | DeepL |
| Känsligt innehåll där kontextuell nyans är viktigast | Claude |
Inget svar är permanent. Ett team som översätter en produktkatalog till franska och ett team som översätter ett juridiskt utlåtande till japanska behöver olika standardinställningar.
Vad händer när du kör båda samtidigt
Det finns ett argument för att frågan Claude vs. DeepL inte är den mest användbara ramen. Båda är starka verktyg med olika styrkor. Den mer användbara frågan är: hur får man det bästa av båda?
När du kör Claude och DeepL på samma källtext och jämför resultaten, berättar skillnaderna något om innehållet. Hög överensstämmelse mellan de två betyder att översättningen är relativt entydig. Divergens avslöjar var genuina tolkningsval existerar – vilket ord, vilken stilnivå, vilken idiomatiskt återgivning.
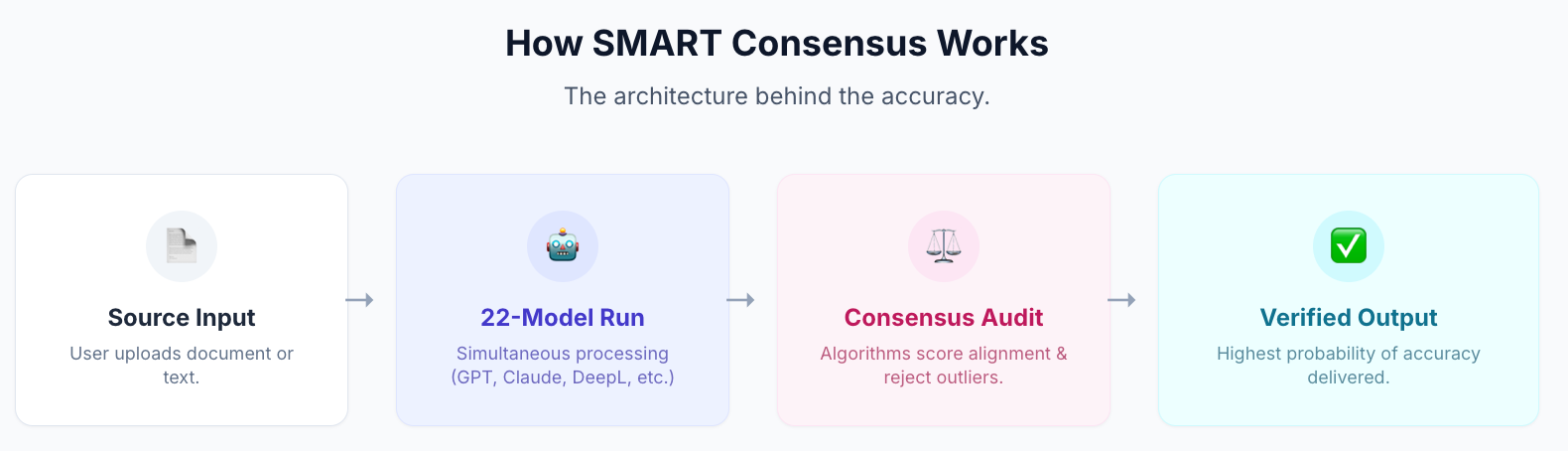
Det är vad MachineTranslation.coms SMART-system gör i praktiken. Den kör 22 AI-modeller samtidigt (inklusive både Claude och DeepL) och visar den utdata som majoriteten av modellerna överensstämmer om, tillsammans med kvalitetsbetyg för varje. Konvergensen är signalen: när Claude och DeepL (och 20 andra modeller) landar på samma översättning är sannolikheten för att den är korrekt strukturellt högre än att lita på någon av dem enskilt.
I MachineTranslation.coms interna riktmärken uppnår denna konsensusmetod en aggregerad kvalitetsresultat på 98,5 av 100 – jämfört med Claude 3.5 Sonnet på 93,8 och DeepL Classic på 94,2 som fristående motorer. Skillnaden är inte marginell: det är klyftan mellan att lita på en modells tolkning och att veta vad de flesta modeller är överens om.
För många översättningsuppgifter kommer antingen Claude eller DeepL att fungera bra. För innehåll där felaktigheter får verkliga konsekvenser är det värt mer att se var de är överens än att bara se en av dem.
Vanliga frågor
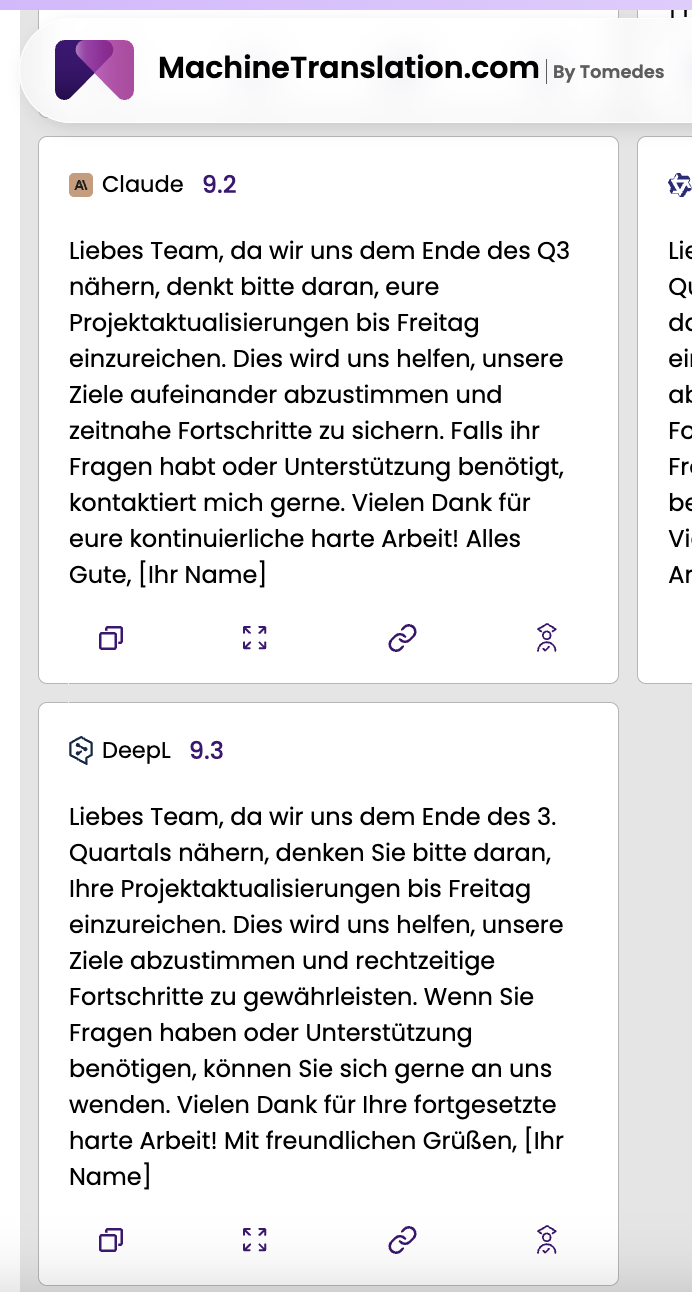
1. Är Claude bättre än DeepL för översättning?
Det beror på innehållstypen. DeepL är bättre för kort, högvolymsöversättning av europeiska språk där flyt och snabbhet är prioriterade. Claude är bättre för långa dokument, komplext innehåll som kräver konsekvent terminologi på många sidor och språkpar utanför DeepLs 33 språks täckning. För de flesta professionella arbetsflöden är det ärliga svaret att de är starka på olika sätt.
2. Vilket är mer korrekt: Claude eller DeepL?
I MachineTranslation.coms interna jämförelse med 5 000 ord av blandat tekniskt och marknadsföringsinnehåll fick DeepL 94,2 % noggrannhet och Claude 3.5 Sonnet fick 93,8 %. På den nivån är skillnaden inte praktiskt meningsfull för det mesta innehållet. Där Claude utmärker sig är på längre dokument där konsekvens i sammanhanget är viktigt, och där DeepLs segment-för-segment-bearbetning kan introducera terminologisk drift.
3. Kan jag använda Claude och DeepL tillsammans?
Inte direkt inom något av verktygen. MachineTranslation.com kör både Claude och DeepL samtidigt som en del av sitt system med 22 modeller, och visar dig resultatet och kvalitetsresultatet för varje, och lyfter fram den översättning som majoriteten av modellerna är överens om. För användare som vill jämföra båda utan att hantera separata integrationer är det ett praktiskt sätt att se hur varje verktyg hanterar samma innehåll.
4. Är DeepL eller Claude bättre för juridiska dokument?
För långa juridiska dokument som kräver intern konsistens (definierade termer används konsekvent, formell stil bibehålls genomgående, korsreferenser mellan klausuler), är Claudes kontextfönster en meningsfull fördel. För kortare juridiska texter som standardklausuler eller korta avtal är DeepLs resultat vanligtvis flytande och snabbt. För juridisk översättning med höga insatser där fel medför ansvar, är mänsklig verifiering fortfarande det lämpliga sista steget oavsett vilket AI-verktyg som producerat utkastet.
5. Hur är DeepLs prissättning jämfört med Claude?
DeepLs prenumerationsplaner börjar på cirka $10.49/användare/månad för professionellt bruk. Claude prissätts per token via API: 3,00 USD per miljon indatatokens för Sonnet 4 och 15,00 USD för Opus 4. För enskilda användare med måttlig volym är DeepLs prenumeration generellt sett mer förutsägbar. För API-arbetsflöden med hög volym beror kostnadsjämförelsen på dokumentlängd och volym, och ingen av dem är konsekvent billigare i alla användningsfall.