June 10, 2026
GPT-4.1 vs DeepSeek V3: Akurasi, halusinasi, dan kinerja terjemahan dibandingkan
Pertanyaan yang diam-diam ditanyakan oleh sebagian besar tim penerjemahan pada pertengahan 2026 bukanlah haruskah kita menggunakan AI?, keputusan itu sudah dibuat. Pertanyaan sebenarnya adalah model AI mana yang akan distandardisasi, dan apakah jawabannya sama untuk setiap pasangan bahasa, setiap jenis dokumen, dan setiap anggaran.
GPT-4.1 dan DeepSeek V3 telah muncul sebagai dua opsi yang paling sering dievaluasi untuk alur kerja terjemahan profesional. Mereka mewakili filosofi yang benar-benar berbeda: satu adalah API yang diatur ketat dan dipoles secara komersial dari OpenAI; yang lainnya adalah model berbobot terbuka, berlisensi MIT dari laboratorium penelitian Tiongkok yang secara diam-diam mengungguli beberapa pesaing berpemilik pada tolok ukur WMT24. Tidak ada yang secara universal lebih baik. Kasus untuk masing-masing bergantung pada apa yang Anda terjemahkan, untuk siapa, dan di bawah batasan apa.
Artikel ini menguraikan kedua model berdasarkan dimensi yang paling penting bagi penerjemah, manajer lokalisasi, dan pembeli perusahaan: akurasi pada pasangan bahasa nyata, perilaku halusinasi, penanganan tugas terbatas seperti kepatuhan glosarium, dan total biaya menjalankan salah satunya dalam skala besar.
Daftar isi
- Mengapa perbandingan ini penting saat ini
- Apa sebenarnya masing-masing model itu
- Perbandingan langsung: Akurasi terjemahan dan kinerja benchmark
- Model mana yang lebih banyak berhalusinasi, dan kapan?
- Model mana yang menangani terjemahan terbatas dengan lebih baik?
- Biaya dan penerapan: Apa yang berubah pada skala
- Bagaimana menguji kedua model tanpa berkomitmen pada salah satunya
- Model mana yang harus Anda pilih untuk alur kerja terjemahan Anda?
- Pertanyaan yang sering diajukan
- Perbandingan terkait
Mengapa perbandingan ini penting saat ini
Pembeli terjemahan secara historis mengevaluasi terjemahan mesin pada sumbu yang sempit: Skor BLEU versus harga. LLMs mendobrak kerangka itu sepenuhnya. GPT-4.1 dan DeepSeek V3 bukanlah mesin Terjemahan Mesin (MT) dalam pengertian tradisional — mereka adalah model serbaguna dengan kemampuan multibahasa yang kuat, dan kinerja mereka pada tugas terjemahan bervariasi berdasarkan arsitektur, data pelatihan, dan cara Anda memberikan prompt kepada mereka.
Variabilitas itulah inti dari masalah evaluasi. Seorang manajer lokalisasi yang menguji kedua model pada salinan pemasaran Inggris→Spanyol mungkin melihat kualitas keluaran yang hampir identik. Manajer yang sama yang menguji dokumen hukum Arab→Inggris kemungkinan akan melihat kesenjangan yang berarti — tetapi model mana yang unggul bergantung pada apakah dokumen tersebut berisi entitas bernama, jargon teknis, atau referensi budaya yang memerlukan pengetahuan dunia daripada pencocokan pola.
Taruhannya juga tidak simetris. DeepSeek V3 berkali-kali lipat lebih murah untuk dioperasikan, terutama jika di-hosting sendiri. GPT-4.1 memiliki biaya premium yang signifikan. Jika kedua model memberikan kualitas yang dapat diterima pada beban kerja spesifik Anda, perbedaan biaya dapat menentukan apakah alur kerja terjemahan AI layak secara ekonomis dalam skala besar.
Apa sebenarnya setiap model itu
GPT-4.1: Produk unggulan OpenAI yang disetel instruksi
Dirilis pada April 2025, GPT-4.1 adalah model OpenAI yang paling patuh instruksi hingga saat ini. Peningkatan utamanya dibandingkan GPT-4o bukanlah kelancaran terjemahan murni (dalam hal itu sudah kuat) melainkan presisi dalam mengikuti instruksi yang kompleks dan multi-bagian. Untuk alur kerja terjemahan, ini sangat penting dalam tugas-tugas yang terbatas: menerapkan glosarium klien, mempertahankan pemformatan dokumen di seluruh teks panjang, mempertahankan register tertentu, atau mematuhi daftar jangan-terjemahkan.
GPT-4.1 mendukung jendela konteks satu juta token, yang berarti ia dapat memproses dokumen sepanjang buku dalam satu panggilan. Dalam tugas keluaran terstruktur (menghasilkan memori terjemahan dalam JSON, menghasilkan skor kualitas tingkat segmen di samping terjemahan, memformat tabel dwibahasa), ini terbukti lebih andal daripada pendahulunya. Pertukarannya adalah biaya: GPT-4.1 berada pada tingkat harga yang lebih tinggi daripada kebanyakan alternatif, termasuk DeepSeek V3.
DeepSeek V3: Penantang sumber terbuka
DeepSeek V3 (versi produksi saat ini adalah DeepSeek-V3-0324) adalah model dengan 685 miliar parameter yang dibangun di atas arsitektur Mixture-of-Experts — yang berarti hanya sebagian kecil dari parameternya yang aktif untuk setiap masukan tertentu, yang menjaga biaya inferensi tetap rendah meskipun jumlah total parameternya sangat besar. Ini dirilis di bawah lisensi MIT, yang berarti organisasi dapat menghostingnya sendiri, melakukan fine-tuning, dan menerapkannya secara komersial tanpa biaya per-token kepada pihak ketiga.
Kinerja terjemahan model ini menarik perhatian yang signifikan setelah WMT24, di mana ia mencatat skor BLEU dan COMET yang kuat pada pasangan bahasa Tionghoa↔Inggris, Arab, dan Korea — dalam beberapa kasus mengungguli GPT-4o. Untuk tim yang banyak bekerja dengan pasangan bahasa Asia atau Timur Tengah, DeepSeek V3 bukanlah pilihan kompromi. Ini benar-benar kompetitif dengan sebagian kecil dari biaya.
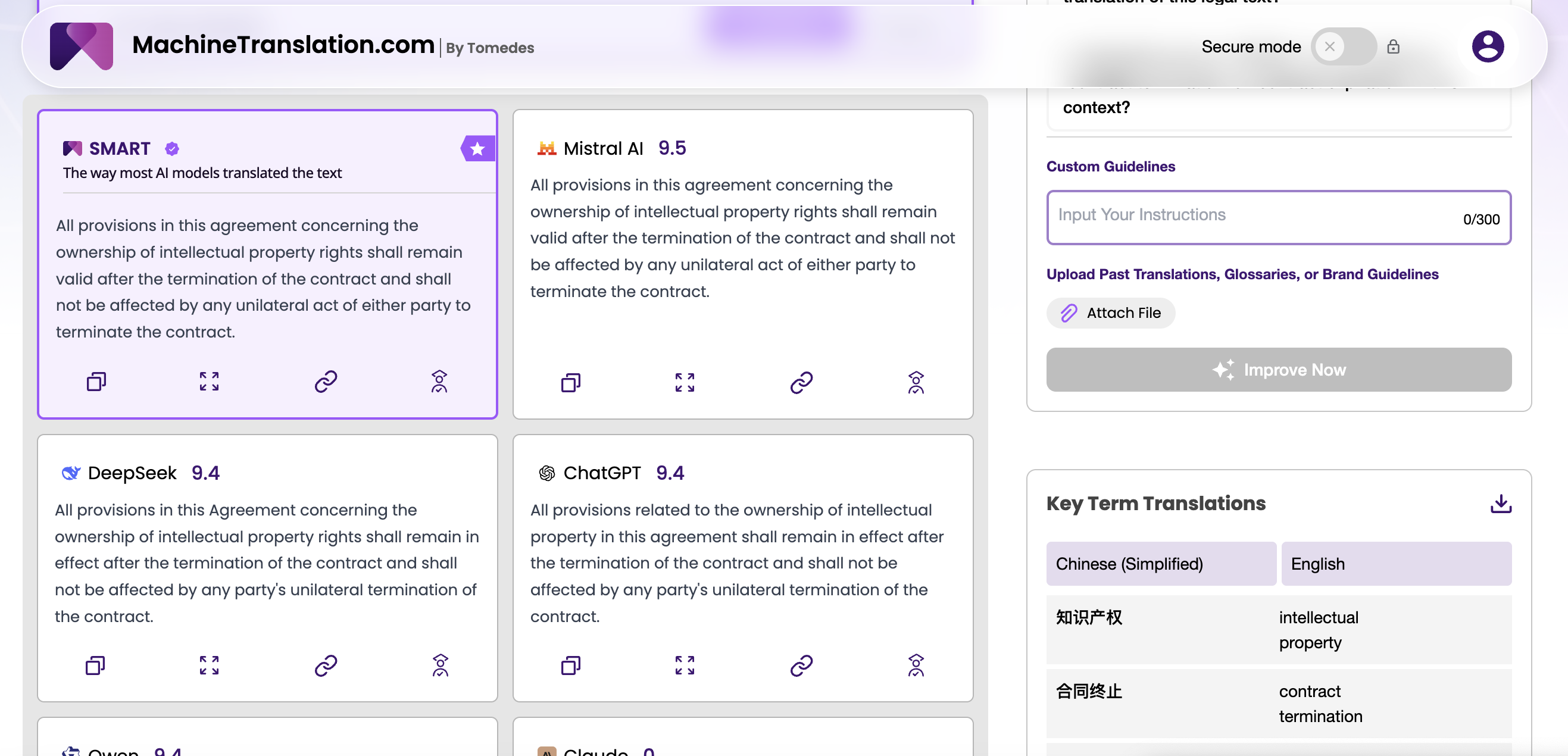
Saling berhadapan: Akurasi terjemahan dan kinerja benchmark
| Dimensi | GPT-4.1 | DeepSeek V3 |
|---|---|---|
| Jendela konteks | 1.000.000 token | ~64.000 token (standar) |
| Arsitektur | Transformer padat | Mixture-of-Experts (685B parameter) |
| Lisensi | Propietari | Sumber terbuka (MIT) |
| Hosting mandiri | Tidak tersedia | Tersedia |
| WMT24 Tiongkok↔Inggris | Kuat | Sangat kuat, mengungguli GPT-4o pada beberapa pasangan |
| Terjemahan Arab WMT24 | Kompetitif | Kuat, terutama pada teks khusus |
| Kepatuhan instruksi | Terbaik di kelasnya vs GPT-4o | Baik; kurang konsisten pada prompt multi-langkah yang kompleks |
| Output terstruktur | Sangat andal | Andal; sedikit penyimpangan format pada output panjang |
| Kecenderungan halusinasi | Berkurang vs GPT-4o | Kadang-kadang pada pasangan sumber daya rendah |
| Biaya API relatif | Lebih tinggi | Jauh lebih rendah |
Pada akurasi terjemahan umum untuk pasangan bahasa dengan sumber daya tinggi (Inggris, Prancis, Spanyol, Jerman, Tiongkok, Jepang), kedua model berkinerja pada tingkat yang digambarkan oleh penerjemah profesional sebagai siap pasca-edit. Kesenjangan di antara keduanya dalam hal kefasihan dan kecukupan saja tidak cukup besar untuk mendorong keputusan pembelian bagi sebagian besar tim.
Perbedaan yang berarti muncul dalam tiga skenario spesifik: bahasa dengan sumber daya rendah, tugas terbatas, dan jenis dokumen yang rentan terhadap halusinasi.
Model mana yang lebih banyak berhalusinasi, dan kapan?
Halusinasi dalam terjemahan tidak sama dengan halusinasi dalam generasi tujuan umum. Model tersebut bekerja dari teks sumber, tidak mengarang fakta dari ketiadaan. Halusinasi di sini bermanifestasi sebagai konten tambahan yang tidak ada dalam sumber, klausa yang dihilangkan, atau entitas bernama yang diganti. Dalam terjemahan hukum atau medis, salah satu kesalahan ini dapat menimbulkan konsekuensi serius.
GPT-4.1 menunjukkan tingkat halusinasi yang terukur lebih rendah dibandingkan GPT-4o, terutama pada dokumen panjang di mana model OpenAI sebelumnya akan mulai menyimpang dari sumber di segmen-segmen selanjutnya. Kombinasi antara jendela konteks satu juta token dan kemampuan mengikuti instruksi yang ditingkatkan berarti GPT-4.1 mempertahankan kesetiaan pada sumber lebih lama tanpa memerlukan strategi pemberian prompt khusus. Untuk pembeli perusahaan yang memproses pengajuan regulasi, dokumentasi produk, atau kontrak, ini adalah peningkatan keandalan yang signifikan.
Profil halusinasi DeepSeek V3 memiliki karakter yang berbeda. Pada pasangan bahasa yang didukung dengan baik (Cina, Inggris, Arab), umumnya dapat diandalkan. Risikonya meningkat pada pasangan sumber daya rendah: Korea→Swahili, Arab→Vietnam, atau pasangan apa pun di mana satu bahasa kurang terwakili dalam korpus pelatihan. Dalam kasus-kasus ini, DeepSeek V3 telah diamati menghasilkan konten yang terdengar masuk akal tetapi tidak didukung sumber, terutama ketika sumber berisi entitas bernama yang ambigu atau terminologi khusus domain.
Implikasi praktisnya: jika portofolio pasangan bahasa Anda terkonsentrasi pada bahasa-bahasa dengan sumber daya tinggi, risiko halusinasi DeepSeek V3 dapat dikelola dengan proses QA standar. Jika Anda menjalankan terjemahan dalam skala besar di seluruh pasangan sumber daya rendah, keandalan tambahan GPT-4.1 mungkin membenarkan premi biaya.
💬 Apa yang kami lihat secara konsisten di platform adalah bahwa kesenjangan antara GPT-4.1 dan DeepSeek V3 dalam hal halusinasi bukan tentang volume, melainkan tentang di mana hal itu terjadi. Pada konten berbahasa Inggris, Prancis, atau Spanyol, sebagian besar penerjemah profesional tidak akan melihat perbedaan yang berarti dalam keandalan. Masalah-masalah dengan DeepSeek V3 cenderung muncul pada dokumen-dokumen Korea atau Arab yang mengandung nama diri yang tidak dikenal atau terminologi yang sangat spesifik domain. GPT-4.1 menangani kasus-kasus ekstrem tersebut dengan lebih konservatif, kecil kemungkinannya untuk mengisi kekosongan dengan sesuatu yang terdengar masuk akal.
— Linguist on MachineTranslation.com
Model mana yang menangani terjemahan terbatas dengan lebih baik?
Terjemahan terbatas (di mana model harus mematuhi glosarium, mempertahankan register merek, menghindari penerjemahan istilah tertentu, atau menjaga struktur dokumen seperti header dan catatan kaki) adalah tempat keunggulan arsitektur GPT-4.1 menjadi paling nyata.
Ketika Anda memberikan prompt sistem dengan glosarium 200 istilah dan menginstruksikan model untuk menandai segmen sumber mana pun di mana kecocokan persis tidak dapat ditemukan, GPT-4.1 mengikuti instruksi tersebut dengan konsistensi yang tidak dapat dipertahankan oleh model sebelumnya di luar beberapa ratus token. Dalam jendela konteks satu juta token, ini berarti Anda dapat menerjemahkan manual teknis setebal 400 halaman dengan batasan terminologi yang kompleks dalam satu panggilan dan mengharapkan penerapan glosarium yang koheren di seluruh bagian.
DeepSeek V3 menangani batasan-batasan yang lugas dengan memadai — instruksi jangan-terjemahkan satu istilah, preferensi register dasar, aturan pemformatan sederhana. Di mana ia berkinerja kurang baik adalah dalam set instruksi kompleks dan gabungan. Seiring meningkatnya jumlah kendala simultan, DeepSeek V3 mulai memprioritaskan beberapa instruksi daripada yang lain dengan cara yang sulit diprediksi tanpa pengujian. Untuk tim lokalisasi yang mengelola panduan gaya multi-level dan memori terjemahan yang besar, inkonsistensi ini menciptakan beban kerja QA hilir yang sebagian mengimbangi keunggulan biaya model tersebut.
Untuk terjemahan murni, tanpa batasan, dari konten standar (komunikasi bisnis umum, salinan pemasaran, deskripsi produk e-commerce), kesenjangan penanganan batasan antara kedua model sebagian besar tidak relevan. Perbedaan ini paling penting bagi tim yang menjalankan alur kerja tingkat perusahaan di mana terjemahan adalah salah satu langkah dalam alur lokalisasi multi-tahap.
💬 Kami menjalankan kedua model tersebut terhadap glosarium yang sama pada kumpulan dokumen hukum, sekitar 120.000 kata di delapan pasang bahasa. GPT-4.1 mematuhi batasan terminologi hampir sempurna. DeepSeek V3 sudah mendekati, tetapi kadang-kadang ia mengganti istilah pilihan dengan sinonim dekat yang klien kami secara khusus meminta kami untuk menghindarinya. Pada volume sebesar itu, 'hampir' tidak cukup baik. Untuk konten yang tidak dibatasi, kami menggunakan DeepSeek V3 dan penghematan biaya sangat signifikan. Untuk apa pun yang memiliki glosarium yang disetujui klien, kami masih menjalankan GPT-4.1.
— Manajer Lokalisasi di MachineTranslation.com
Biaya dan penerapan: Apa yang berubah dalam skala besar
Biaya adalah titik di mana kedua model menyimpang paling tajam, dan di mana evaluasi harus memperhitungkan lebih dari harga per-token.
GPT-4.1 dihargai pada tingkat premium. Bagi organisasi yang memproses jutaan kata per bulan melalui API OpenAI, biaya tersebut berlipat ganda dengan cepat. Model ini tidak tersedia untuk self-hosting, yang berarti setiap token dikenakan biaya API yang tidak dapat dikurangi melalui investasi infrastruktur.
Profil biaya DeepSeek V3 secara fundamental berbeda. Melalui API DeepSeek, ini jauh lebih murah per token daripada GPT-4.1. Dihosting sendiri, ekonomi bergeser lebih jauh: organisasi dengan infrastruktur GPU dapat menjalankan DeepSeek V3 dengan biaya yang ditentukan terutama oleh komputasi daripada lisensi per token. Untuk operasi terjemahan bervolume tinggi (katalog e-commerce global, pipeline konten multibahasa, pemrosesan dokumen regulasi), perbedaannya dapat mewakili ratusan ribu dolar setiap tahun pada skala perusahaan.
Lisensi sumber terbuka DeepSeek V3 juga penting untuk sektor yang sensitif data. Organisasi hukum, keuangan, dan layanan kesehatan yang tidak dapat mengirim dokumen klien ke API eksternal dapat menerapkan DeepSeek V3 secara lokal. GPT-4.1 tidak menawarkan opsi yang setara.
Aturan keputusannya relatif jelas: jika beban kerja Anda bervolume tinggi, pasangan bahasa Anda didukung dengan baik, dan kebijakan tata kelola data Anda memungkinkan layanan API atau penerapan di tempat, DeepSeek V3 memberikan kualitas yang kompetitif dengan biaya yang jauh lebih rendah. Jika beban kerja Anda melibatkan terjemahan terbatas, fidelitas dokumen panjang, atau pasangan bahasa berdaya rendah, keandalan GPT-4.1 mungkin sepadan dengan harganya.
Cara menguji kedua model tanpa berkomitmen pada salah satunya
Hambatan praktis dalam pemilihan model bagi sebagian besar tim lokalisasi bukanlah pemahaman tolok ukur — melainkan gesekan dalam menyiapkan integrasi API independen dengan kedua model, merancang kondisi pengujian yang sebanding, dan menjalankan evaluasi yang bermakna pada konten Anda sendiri.
MachineTranslation.com menghilangkan hambatan tersebut. Platform ini menjalankan GPT-4.1 dan DeepSeek V3 secara berdampingan, memberikan penerjemah profesional dan manajer lokalisasi kemampuan untuk mengirimkan teks sumber yang sama ke kedua model secara bersamaan dan membandingkan hasilnya secara real-time — tanpa kunci API terpisah, tanpa proses pengadaan, dan tanpa berkomitmen pada salah satu model.
Ini penting karena kinerja benchmark pada tingkat dataset tidak selalu memprediksi kinerja pada konten spesifik Anda. Sebuah model yang menunjukkan skor COMET tinggi pada teks berita WMT24 Tiongkok→Inggris mungkin berkinerja buruk pada terminologi atau domain spesifik perusahaan Anda. Satu-satunya evaluasi yang relevan untuk pengambilan keputusan adalah yang dilakukan pada dokumen Anda sendiri, dengan batasan Anda sendiri, dalam pasangan bahasa Anda sendiri.
Posisi MachineTranslation.com sebagai platform multi-model yang netral berarti tidak memiliki insentif komersial untuk memihak GPT-4.1 atau DeepSeek V3. Peran platform adalah untuk memberi Anda data perbandingan untuk Anda putuskan sendiri, dan kemudian untuk menjalankan model mana pun yang Anda pilih pada skala produksi setelah evaluasi selesai. Meskipun tentu saja, ini juga memberi Anda terjemahan yang disepakati sebagian besar model AI sebagai terjemahan terbaik bawaan.
Untuk tim yang juga mengevaluasi di seluruh tingkatan model OpenAI, bagaimana GPT-4.1 dibandingkan dengan model OpenAI lainnya (termasuk GPT-4.5 dan GPT-4o) memberikan konteks yang berguna sebelum berkomitmen pada versi model. Dan bagi tim yang mengevaluasi bagaimana DeepSeek V3 dibandingkan dengan GPT-4o pada awal tahun 2025, artikel ini membahas apa yang telah berubah dengan rilis GPT-4.1.
Model mana yang harus Anda pilih untuk alur kerja terjemahan Anda?
Daripada satu rekomendasi tunggal, kerangka kerja berikut mencerminkan logika keputusan yang akan ditemukan berguna oleh sebagian besar tim terjemahan profesional:
-
Mulailah dengan pasangan bahasa Anda. Jika portofolio Anda terkonsentrasi pada Tionghoa↔Inggris, Arab, atau Korea, kinerja WMT24 DeepSeek V3 menjadikannya uji coba pertama yang alami. Jika Anda bekerja terutama dalam bahasa-bahasa Eropa dengan terminologi terbatas, GPT-4.1 kemungkinan akan menghasilkan keluaran yang lebih konsisten sejak hari pertama.
-
Nilai kompleksitas batasan Anda. Kendala satu tingkat (satu glosarium, satu register) ditangani dengan memadai oleh salah satu model. Batasan multi-level (glosarium + format + daftar jangan-terjemahkan + penilaian QA), GPT-4.1 lebih andal saat ini.
-
Petakan volume Anda terhadap perbedaan biaya. Di bawah 500.000 kata per bulan, perbedaan biaya API mutlak mungkin tidak secara signifikan memengaruhi anggaran Anda. Di atas ambang batas itu, keunggulan biaya DeepSeek V3 menjadi semakin sulit untuk diabaikan.
-
Perhitungkan persyaratan tata kelola data Anda. Jika dokumen tidak dapat meninggalkan infrastruktur Anda, DeepSeek V3 yang di-hosting sendiri saat ini adalah satu-satunya pilihan yang layak dari keduanya.
-
Jalankan evaluasi pada konten Anda, bukan pada tolok ukur. Gunakan MachineTranslation.com untuk mengirimkan sampel representatif dari beban kerja Anda yang sebenarnya ke kedua model dan menilai hasilnya berdasarkan kriteria kualitas Anda sendiri sebelum berkomitmen.
Untuk pandangan yang lebih luas tentang posisi model-model ini dalam lanskap terjemahan AI saat ini, alat terjemahan AI terbaik tahun 2026 mencakup seluruh bidang kompetitif, termasuk bagaimana LLM dibandingkan dengan infrastruktur terjemahan yang dibangun khusus.
Pertanyaan yang sering diajukan
1. Apakah GPT-4.1 lebih baik dari DeepSeek V3 untuk terjemahan?
Tidak ada model yang secara universal lebih baik. GPT-4.1 mengungguli DeepSeek V3 dalam tugas terjemahan terbatas, fidelitas dokumen panjang, dan pasangan bahasa ber sumber daya rendah di mana risiko halusinasi lebih tinggi. DeepSeek V3 menyamai atau mengungguli GPT-4.1 pada beberapa tolok ukur WMT24 (terutama Tionghoa↔Inggris, Arab, dan Korea) dan secara signifikan lebih murah untuk dijalankan dalam skala besar atau di-hosting sendiri.
2. Apakah DeepSeek V3 berhalusinasi lebih banyak daripada GPT-4.1?
Pada pasangan bahasa berdaya tinggi, perbedaan halusinasi relatif kecil. Kesenjangan semakin lebar pada pasangan dengan sumber daya rendah dan konten khusus domain dengan entitas bernama yang langka, di mana DeepSeek V3 telah menunjukkan tingkat yang lebih tinggi dalam penambahan atau penggantian yang tidak didukung oleh sumber. GPT-4.1 menunjukkan pengurangan halusinasi dibandingkan dengan GPT-4o, terutama pada dokumen yang lebih panjang.
3. Bisakah saya menggunakan DeepSeek V3 secara komersial?
Ya. DeepSeek V3 dirilis di bawah lisensi MIT, yang mengizinkan penggunaan komersial termasuk fine-tuning dan self-hosting. Organisasi yang tidak dapat mengirim dokumen ke API eksternal dapat menerapkan DeepSeek V3 di infrastruktur mereka sendiri. GPT-4.1 membutuhkan penggunaan API OpenAI berdasarkan ketentuan layanan OpenAI dan tidak tersedia untuk hosting mandiri.
4. Model mana yang lebih baik untuk terjemahan bahasa Mandarin ke bahasa Inggris?
DeepSeek V3 memiliki keunggulan dalam terjemahan Mandarin↔Inggris berdasarkan hasil benchmark WMT24. Namun, untuk terjemahan Tiongkok→Inggris yang melibatkan terminologi terbatas, presisi hukum, atau pemformatan kompleks, kemampuan GPT-4.1 dalam mengikuti instruksi membuatnya lebih andal dalam alur kerja produksi di mana penerjemah manusia akan melakukan pasca-penyuntingan pada hasilnya.
5. Bisakah saya menguji GPT-4.1 dan DeepSeek V3 secara berdampingan sebelum memilih?
Ya — MachineTranslation.com menjalankan kedua model secara bersamaan (dan 20+ lainnya) dan memungkinkan Anda membandingkan output pada konten Anda sendiri secara real time, tanpa akun API terpisah atau proses pengadaan.
6. Bagaimana perbandingan DeepSeek V3 dengan Claude untuk terjemahan?
Bagi tim yang juga mengevaluasi model Anthropic, perbandingan Claude vs DeepSeek V3 mencakup perbedaan utama dalam arsitektur, akurasi, dan opsi penerapan di seluruh skenario yang relevan dengan terjemahan.