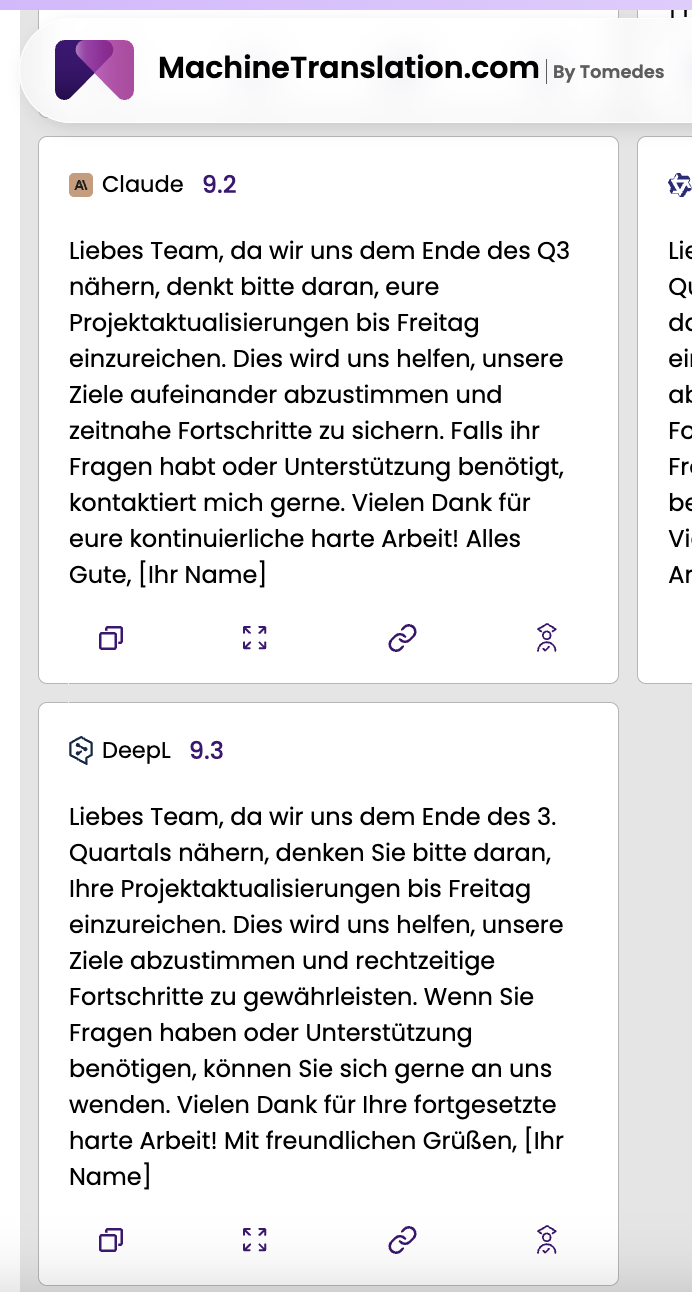
May 22, 2026
翻訳におけるClaude対DeepL:どちらの方が実際には良いですか?
正直な出発点はこちらです:ClaudeとDeepLは、実際には同じユーザーを競合相手としていない。
DeepLは翻訳のために作られた。2017年以来、ある一つのこと(自然な響きでテキストをある言語から別の言語に変換すること)を洗練させてきました。Claudeは、Anthropicによって開発された汎用推論モデルであり、特にコンテンツが長く、複雑で、深い文脈解釈を必要とする場合に、非常に優れた翻訳を行います。
「Claude vs DeepL」という問いは、プロの翻訳作業をどのように処理するかを真剣に決定し、マーケティング比較ではなく、明確な答えを求めている人々にとって重要です。この記事が目指すものです。
この記事では
- 各ツールが何のために作られたのか
- ClaudeとDeepLの精度を比較するとどうなるか?
- DeepLが本当に優れている点
- Claudeが優れている点
- 言語のカバー範囲とドキュメントの処理
- 価格:実際に支払う金額
- どちらを使うべきか?
- 両方を同時に実行するとどうなるか
- よくある質問
各ツールが何のために作られたか
Claude:翻訳に使用される推論モデル

ClaudeはAnthropicによって開発され、その中核は、幅広いタスクにわたる推論、分析、生成のために設計された大規模言語モデルです。翻訳は、そのようなタスクの1つであり、Claude はそれに非常に優れていることが判明しました。特に、周囲のコンテキストが意味を決定するコンテンツ、つまり法的文書、文学作品、技術仕様、そして単一の文を単独で理解できないものに適しています。
現在の Claude 4 ファミリー (Claude Opus 4 および Claude Sonnet 4) は、200,000 トークンのコンテキストウィンドウを備えており、翻訳で何が可能になるかを変えています。セグメントごとに作業するドキュメント翻訳者は、文間の依存関係、登場人物の名前や用語の不整合、章ごとのトーンの変化を見逃します。クロードにはその問題はありません。完全な契約を読み込ませると、契約全体を把握します。
DeepL:翻訳に特化して作られたツール

DeepLは1つのことに取り組み、それを徹底的に最適化しています。そのニューラル機械翻訳エンジンは、翻訳に関連するデータに特化して訓練されており、その専門性は出力に表れています。DeepLの翻訳は、ほとんどの競合他社よりも、ヨーロッパ言語のペアで一貫してより自然に聞こえます。言い回しは慣用的で、文法は整然としており、レジスターは通常、ソースとよく一致しています。
MachineTranslation.comの、技術的な内容とマーケティングの内容が混在する5,000語の内部ベンチマークでは、DeepLは94.2%の精度を記録し、これはテストされたスタンドアロンエンジンの中で最も高く、ベンチマークでは「流れの王」と評されています。ヨーロッパの言語ペアについては、特に人間らしく聞こえます。
DeepLはまた、2024年にDeepL next-genをリリースしました。これは、長いテキスト向けに従来のモデルを改善した、翻訳専用に構築されたLLMです。そして、Intentoの2025年の評価では、英語からスペイン語、フランス語、イタリア語、オランダ語、韓国語、ポルトガル語を含む複数の言語ペアで、最高のパフォーマンスを発揮するリアルタイムソリューションの一つとして位置づけられています。
その専門化のトレードオフは:DeepL は 33 の言語をサポートしていますが、これは狭いです。そして、これは単一モデルシステムです。つまり、あなたが受け取る出力はDeepLの解釈であり、クロスチェック信号はなく、あなたが同意しない選択をいつ行ったのかを知る方法もありません。
ClaudeとDeepLの精度はどのように比較されますか?
答えは、何を翻訳し、どの言語に翻訳するかによって大きく異なります。
ヨーロッパ言語ペア
主要なヨーロッパ言語ペア(ドイツ語、フランス語、スペイン語、イタリア語、オランダ語、ポルトガル語)の場合、DeepL次世代は本当に競争力があります。Intentoの2025年ヒューマンLQA評価では、評価対象の11の言語ペアのうち6つでトップティアにランクインしました。出力は自然で、慣用的で、ユーザーからのプロンプトエンジニアリングを必要とせずに、適切にフォーマルなものになります。
Claude Opus 4とSonnet 3.7も、これらのペアのいくつか、特に英語からドイツ語、英語からオランダ語においてトップティアに登場し、Claudeのコンテキスト推論が、より長いテキスト全体での形態的複雑さと格一致の処理に役立っています。
このレベルでの実用的な違い:短く標準的なコンテンツ(製品の説明、フォームフィールド、UIコピー)の場合、DeepLの速度の優位性が重要であり、その品質は一貫しています。より長く、より複雑なコンテンツの場合、Claude のコンテキストウィンドウと推論の深さによって、明らかに強力な出力が生成されます。
長いドキュメントとコンテキスト処理
この比較は、ここで差が大きくなります。
MachineTranslation.com の内部分析で追跡されているように、現代の AI 翻訳に残っているエラーは、ほぼすべて意味的なものです。つまり、間違ったトーン、間違ったレジスター、間違った用語、文間の依存関係の見落としです。これらは、セグメントごとの翻訳では捉えられないエラーです。それらは、全文を読んで初めて表面化するエラーであり、登場人物の肩書きが3ページ目で変わっていたり、定義された用語が2つの節で異なるように表現されていたりする場合などです。
Claudeの20万トークンのコンテキストウィンドウは、法的合意書、技術マニュアル、または文学作品の章全体をワーキングメモリに保持し、ドキュメント全体で内部的に一貫性のある翻訳を生成できることを意味します。DeepL のドキュメント翻訳機能は、コンテンツをセクションごとに処理します。これは、構造化されたドキュメントには概ね有効ですが、Claude が設計上避けているようなずれが生じる可能性があります。
技術的および専門分野のコンテンツ
どちらのツールも、一般的な技術コンテンツを比較的うまく処理します。高度に専門化された分野(法律、医療、金融)では、結果はソースコンテンツが各ツールのトレーニングデータにどの程度うまくマッピングされるかに依存します。DeepLは、有料APIプランで用語集のインジェクションを可能にし、用語の一貫性を維持するのに役立ちます。API経由または構造化されたプロンプトで使用されるClaudeは、コンテキストとして完全な用語集を吸収し、それを全体に適用できます。どちらのアプローチが良いと断言できるわけではありません。どちらもユーザーによるセットアップ作業が必要です。
DeepLが真に優れているのは
ヨーロッパ言語のペアにおける自然さと流暢さです。 翻訳がネイティブスピーカーによって書かれたように聞こえる必要がある場合(マーケティングコピー、ブランドコミュニケーション、消費者向けコンテンツなど)、DeepLの出力は常に最も自然に聞こえるものの1つです。クロードは正確に翻訳しますが、特にEU言語ペアの場合、DeepLの出力はより慣用的に読めます。
スピード。 DeepLは、スループットに最適化されたNMTエンジンです。大量の、時間的制約のあるワークフローでは、LLM速度で動作するClaudeよりも大幅に高速です。
ワークフローの統合。 DeepLは成熟したエコシステムを持っています:CATツールプラグイン、ドキュメント化されたAPI、用語集管理、トーン設定(フォーマル/インフォーマル)。プロの翻訳者のワークフローに、汎用モデルであるClaudeが元々備えていない方法で適合します。
標準的なコンテンツに対する一貫した出力。翻訳タスクが明確に定義されており、出力が確実に正しくある必要があるコンテンツの場合、DeepLは変数を排除します。あなたは、何が得られるかをおおよそ知っています。
クロードが優れている点
長くて、文脈的に複雑なドキュメントです。 40ページの契約書、文学的な章、複数のセクションからなる技術仕様など、クロードは全体を一度に処理し、セグメントごとの翻訳では再現できない方法で、全体を通して一貫性を保ちます。
ニュアンスとレジスター。 Claude 3.5 Sonnetは、MachineTranslation.comの内部品質ベンチマークで100点満点中93.8点を獲得し、トーンが重要なコンテンツ、つまりブランドボイスの翻訳、ステークホルダーとのコミュニケーション、そして「技術的に正しい」だけでは不十分な専門的なやり取りにおいて、特に優れたパフォーマンスを発揮しました。
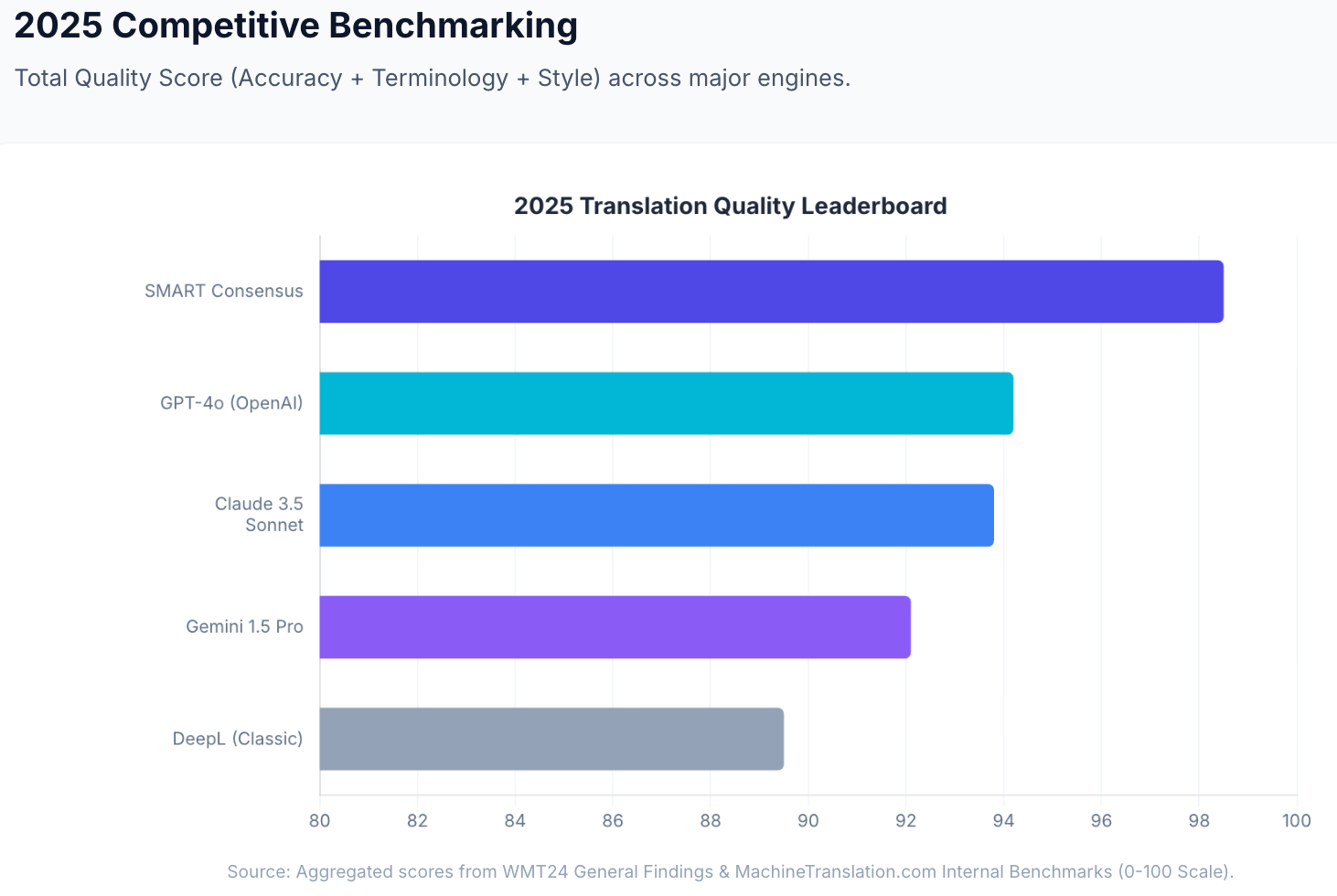
多言語の幅。 クロードは、DeepLの33言語よりもはるかに幅広い言語をサポートしています。DeepLの主要なヨーロッパ圏外で活動するチームにとって、Claudeは真のギャップを埋めます。
テキストに関する推論。翻訳だけでなく、異なるオーディエンス向けにコンテンツを調整したり、レジスターを調整したり、文化的に不適切なフレーズにフラグを立てたりする場合、Claudeは同じタスクの一部としてこれを行います。DeepL が翻訳します。クロードも考えています。