June 10, 2026
GPT-4.1 対 DeepSeek V3:精度、幻覚、および翻訳パフォーマンスの比較
2026年半ば、多くの翻訳チームが静かに抱いている疑問は「AIを使うべきか?」ではない。その決断はすでに下されている。本質的な問いは、どのAIモデルを標準化するか、そしてその答えが言語ペア、文書タイプ、予算ごとに同じかどうかである。
GPT-4.1とDeepSeek V3は、プロフェッショナルな翻訳ワークフローにおいて最も頻繁に評価されている2つの選択肢として浮上している。それらは真に異なる哲学を表しています。一方はOpenAIによる厳格に管理された商業的に洗練されたAPIであり、もう一方は中国の研究機関によるオープンウェイトでMITライセンスのモデルであり、WMT24ベンチマークでいくつかの独自開発の競合他社を静かに凌駕しました。どちらも一概に優れているわけではありません。それぞれの場合の判断は、何を、誰のために、どのような制約の下で翻訳するかによって異なります。この記事では、翻訳者、ローカライゼーションマネージャー、エンタープライズバイヤーにとって最も重要な次元、つまり実際の言語ペアでの精度、幻覚の挙動、用語集の遵守のような制約のあるタスクの処理、および大規模でどちらかを実行する総コストについて、両方のモデルを分析します。目次現在この比較が重要な理由各モデルの実際の内容直接対決:
- 翻訳精度とベンチマークパフォーマンス
- どのモデルがより多く、いつ幻覚を起こすか?
- どのモデルが制約付き翻訳をよりうまく処理するか?
- コストとデプロイメント:スケールでの変更点
- どちらにもコミットせずに両方のモデルをテストする方法
- 翻訳ワークフローにはどちらのモデルを選択すべきか?
- よくある質問
- 関連比較
この比較が今重要な理由
翻訳バイヤーは、歴史的に機械翻訳を狭い軸で評価してきました。BLEUスコア対価格。LLMは、その枠組みを完全に打ち破ります。GPT-4.1およびDeepSeek V3は、従来の意味での機械翻訳(MT)エンジンではありません。これらは強力な多言語機能を備えた汎用モデルであり、翻訳タスクにおけるパフォーマンスは、アーキテクチャ、トレーニングデータ、およびプロンプトの方法によって異なります。
この変動性が評価問題の核心です。ローカライゼーションマネージャーが英語からスペイン語へのマーケティングコピーで両方のモデルをテストした場合、出力品質はほぼ同じになる可能性があります。アラビア語→英語の法律文書をテストする同じマネージャーは、意味のあるギャップに気づく可能性が高いですが、どちらのモデルが優れているかは、文書に固有名詞、専門用語、またはパターンマッチングではなく世界知識を必要とする文化的参照が含まれているかどうかにかかっています。
賭け金も非対称です。DeepSeek V3 は、特にセルフホストの場合、運用コストが桁違いに安くなります。GPT-4.1はかなりのコストプレミアムを伴います。もし両方のモデルが特定のワークロードで許容できる品質を提供する場合、コストの違いがAI翻訳ワークフローが大規模で経済的に実行可能かどうかを決定する可能性があります。
各モデルが実際に何であるか
GPT-4.1:OpenAIの指示チューニングされたフラッグシップ
2025年4月にリリースされたGPT-4.1は、これまでで最も指示に従うOpenAIのモデルです。そのヘッドラインでの改善点は、GPT-4oと比較して、生の翻訳の流暢さ(そこはすでに得意だった)ではなく、複雑で複数の部分からなる指示に正確に従うことである。翻訳ワークフローにおいて、これは特に制約のあるタスクで重要になります。クライアントの用語集の適用、長文全体での文書フォーマットの維持、特定のレジスターの維持、または翻訳禁止リストの遵守などです。GPT-4.1は100万トークンのコンテキストウィンドウをサポートしており、これは単一の呼び出しで書籍サイズの文書を処理できることを意味します。
構造化出力タスク(JSONでの翻訳メモリ生成、翻訳と並行したセグメントレベルの品質スコア生成、バイリンガルテーブルのフォーマットなど)においては、その前身よりも明らかに信頼性が高いです。トレードオフはコストです。GPT-4.1は、DeepSeek V3を含むほとんどの代替品よりも高い価格帯に位置しています。
DeepSeek V3:オープンソースのチャレンジャーであるDeepSeek
V3(現在のプロダクションバージョンはDeepSeek-V3-0324)は、Mixture-of-Expertsアーキテクチャ上に構築された6850億パラメータのモデルです。これは、任意の入力に対してパラメータの一部のみがアクティブになることを意味し、膨大な総パラメータ数にもかかわらず、推論コストを低く抑えます。MITライセンスでリリースされており、組織はそれをセルフホストしたり、ファインチューニングしたり、サードパーティへのトークンごとの料金なしで商用展開したりできます。
このモデルの翻訳パフォーマンスは、WMT24で大きな注目を集めました。中国語↔英語、アラビア語、韓国語のペアで高いBLEUおよびCOMETスコアを記録し、いくつかのケースではGPT-4oを上回りました。アジアまたは中東の言語ペアで集中的に作業するチームにとって、DeepSeek V3 は妥協の選択肢ではありません。そのコストのほんの一部で、本当に競争力があります。
直接対決:翻訳精度とベンチマークパフォーマンス
| 次元 | GPT-4.1 | DeepSeek V3 | |
|---|---|---|---|
| コンテキストウィンドウ | 1,000,000 トークン | 約64,000 トークン (標準) | |
| アーキテクチャ | 密なトランスフォーマー | Mixture-of-Experts (685B パラメータ) | |
| ライセンス | プロプライエタリ | オープンソース (MIT) | |
| セルフホスティング | 利用不可 | 利用可能 | |
| WMT24 中国語↔英語 | 強力 | 非常に強力、いくつかのペアでGPT-4oを上回る | |
| WMT24 アラビア語翻訳 | 競争力がある | 強力、特に専門的なテキストで | |
| 指示追従性 | GPT-4o | との比較でクラス最高 | |
| 良好。 | 複雑な複数ステップのプロンプトでは一貫性が低い 構造化出力 | 非常に信頼性が高い | 信頼性が高い。長い出力では軽微なフォーマットのずれが発生 |
| 幻覚の傾向 | GPT-4o | と比較して減少 低リソースペアで時折発生 | |
| 相対的なAPIコスト | 高い | 大幅に低い |
高リソース言語ペア(英語、フランス語、スペイン語、ドイツ語、中国語、日本語)の一般的な翻訳精度では、どちらのモデルもプロの翻訳者が「ポストエディット可能」と表現するレベルでパフォーマンスを発揮します。それらの流暢さと適切さにおける差だけでは、ほとんどのチームにとって購入の決定を左右するほど大きくはありません。意味のある違いは、リソースの少ない言語、制約のあるタスク、幻覚を起こしやすいドキュメントタイプの 3
つの特定のシナリオで現れます。どのモデルが、いつ幻覚を起こしやすいのでしょうか?翻訳における幻覚は、汎用的な生成における幻覚とは異なります。
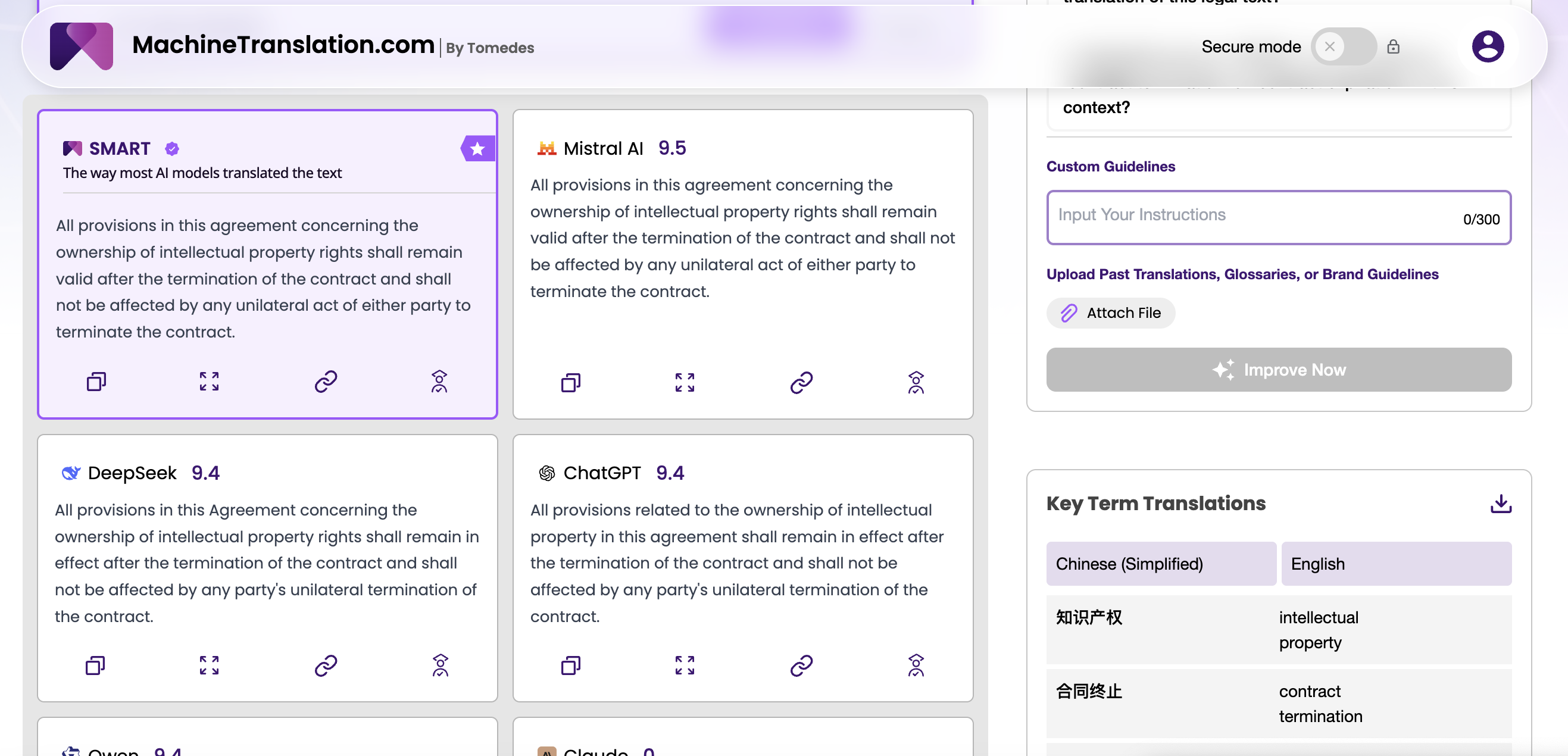
モデルはソーステキストから作業しており、何も無いところから事実を捏造しているわけではありません。ここでは、幻覚はソースにないコンテンツの追加、節の省略、または固有表現の置き換えとして現れます。法的または医学的な翻訳では、これらのいずれかの誤りが重大な結果を招く可能性があります。GPT-4.1は、特に以前のOpenAIモデルが後半でソースから逸脱し始める長文において、GPT-4oよりも測定可能なほど低い幻覚率を示しています。
100万トークンのコンテキストウィンドウと指示追従性の向上を組み合わせることで、GPT-4.1は特別なプロンプト戦略を必要とせずに、より長くソースへの忠実性を維持します。規制当局への提出書類、製品ドキュメント、または契約書を処理するエンタープライズバイヤーにとって、これは信頼性の意味のある向上です。
DeepSeek V3 の幻覚プロファイルは、性質が異なります。十分にサポートされている言語ペア(中国語、英語、アラビア語)では、一般的に信頼できます。低リソースペアではリスクが増加します。韓国語→スワヒリ語、アラビア語→ベトナム語、またはトレーニングコーパスで十分に表現されていない言語ペア。これらのケースでは、DeepSeek V3は、特にソースに曖昧な固有表現やドメイン固有の用語が含まれている場合、もっともらしく聞こえるがソースに裏付けられていないコンテンツを生成することが観察されています。
実用的な意味合い:言語ペアのポートフォリオが高リソース言語に集中している場合、DeepSeek V3の幻覚のリスクは標準的なQAプロセスで管理可能です。低リソースペア全体で大規模な翻訳を実行している場合、GPT-4.1 の追加の信頼性はコストプレミアムを正当化する可能性があります。
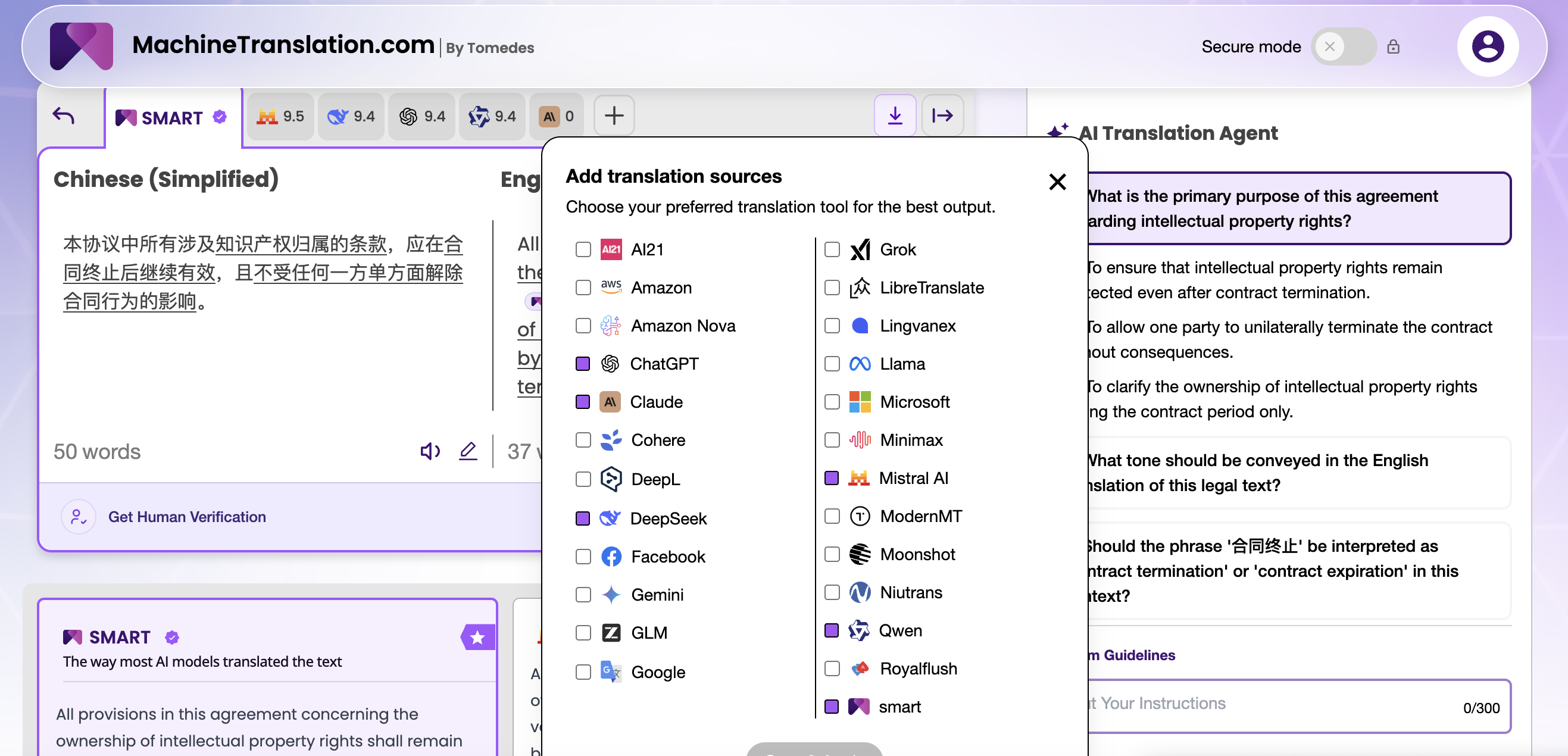
💬「プラットフォームで一貫して見られるのは、GPT-4.1 と DeepSeek V3 の幻覚のギャップは量ではなく、それがどこで発生するかということです。英語、フランス語、スペイン語のコンテンツであれば、ほとんどのプロの翻訳者は信頼性の面で意味のある違いに気づかないでしょう。DeepSeek V3 の問題は、馴染みのない固有名詞や非常に専門的な用語を含む韓国語またはアラビア語の文書で表面化する傾向があります。GPT-4.1 は、それらのエッジケースをより保守的に処理し、もっともらしい音のするものでギャップを埋める可能性が低くなります。
— Linguist on MachineTranslation.com
制約付き翻訳でより優れたパフォーマンスを発揮するのはどちらのモデルですか?
制約付き翻訳(モデルが用語集を尊重し、ブランドの登録を維持し、特定の用語の翻訳を避け、ヘッダーや脚注などのドキュメント構造を保持する必要がある場合)は、GPT-4.1 のアーキテクチャ上の利点が最も顕著になる分野です。
200 語の用語集を含むシステムプロンプトを提供し、正確な一致が見つからないソースセグメントにフラグを付けるようにモデルに指示すると、GPT-4.1 は、以前のモデルでは数百トークンを超えると維持できなかった一貫性をもって、それらの指示に従います。100万トークンのコンテキストウィンドウでは、複雑な専門用語の制約がある400ページの技術マニュアルを単一の呼び出しで翻訳し、一貫した用語集の適用を期待できます。
DeepSeek V3は、単一用語の翻訳禁止指示、基本的なレジスタの好み、単純な書式設定ルールといった単純な制約を適切に処理します。性能が劣るのは、複雑で複合的な命令セットにおいてです。同時に制約が増えるにつれて、DeepSeek V3 は、テストなしでは予測が困難な方法で、一部の指示を他の指示よりも優先し始めます。多層的なスタイルガイドや大規模な翻訳メモリを管理するローカライゼーションチームにとって、この不整合は、モデルのコストメリットを部分的に相殺する下流のQAオーバーヘッドを生み出します。標準的なコンテンツ(一般的なビジネスコミュニケーション、マーケティングコピー、eコマースの商品説明)の純粋で制約のない翻訳においては、2つのモデル間の制約処理のギャップはほとんど関係ありません。
翻訳対象:エンタープライズグレードのワークフローを実行するチームにとって、翻訳が多段階のローカライゼーションパイプラインの1ステップである場合、その違いは最も重要になります。
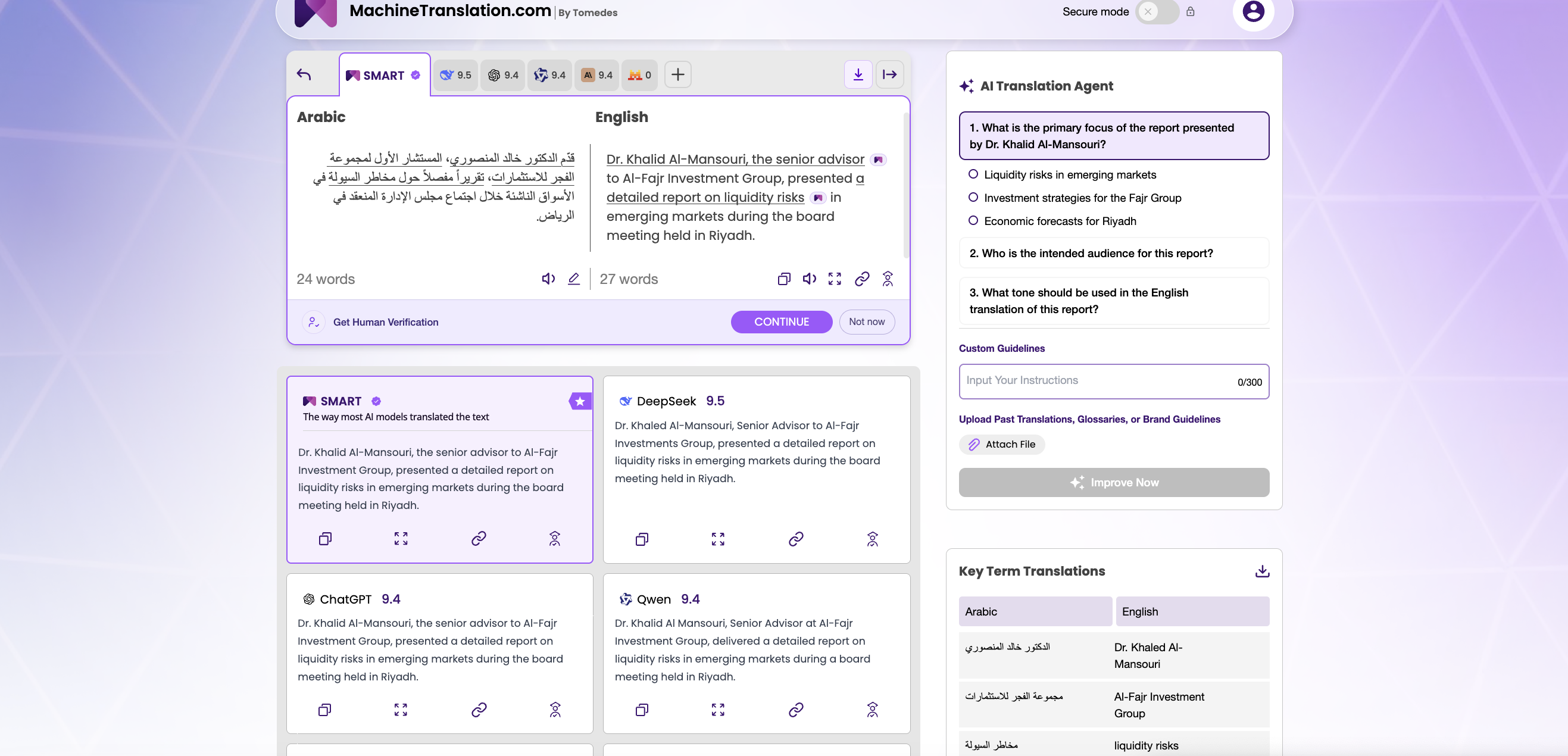
💬「両方のモデルを、8つの言語ペアにわたる約12万語の法律文書セットの同じ用語集に対して実行しました。GPT-4.1は、用語の制約をほぼ完璧に守りました。DeepSeek V3は惜しかったのですが、クライアントが特に避けるように求めていた、より好ましい用語を時折、近い類義語に置き換えてしまうことがありました。その音量では、「ほぼ」では十分ではありません。制約のないコンテンツにはDeepSeek V3を使用しており、大幅なコスト削減を実現しています。クライアント承認済みの用語集がある場合は、引き続きGPT-4.1を使用しています。「
— MachineTranslation.comのローカライゼーションマネージャー
コストと展開:スケールでの変更点
コストは、2つのモデルが最も大きく異なる点で、評価ではトークンあたりの価格設定以上のものを考慮する必要があります。
GPT-4.1はプレミアムティアで価格設定されています。毎月数百万語をOpenAI API経由で処理する組織にとって、そのコストは急速に積み重なります。モデルはセルフホスティングでは利用できないため、すべてのトークンにAPI料金が発生し、インフラ投資によって削減することはできません。
DeepSeek V3 のコストプロファイルは根本的に異なります。DeepSeek API を介して、トークンあたりのコストは GPT-4.1 よりも大幅に安くなります。セルフホストの場合、経済性はさらに変化します。GPUインフラストラクチャを持つ組織は、トークンごとのライセンスではなく、主にコンピューティングによって決定されるコストでDeepSeek V3を実行できます。大量翻訳業務(グローバルなeコマースカタログ、多言語コンテンツパイプライン、規制文書処理)において、その差はエンタープライズ規模で年間数十万ドルに達する可能性があります。
DeepSeek V3のオープンソースライセンスは、データ機密性の高い分野でも重要です。法務、金融、医療機関は、クライアント文書を外部APIに送信できない場合、DeepSeek V3をオンプレミスにデプロイできます。GPT-4.1には同等のオプションはありません。
決定ルールは比較的明確です。ワークロードが高頻度で、言語ペアが十分にサポートされており、データガバナンスポリシーでAPIサービスまたはオンプレミス展開が許可されている場合、DeepSeek V3は実質的に低コストで競争力のある品質を提供します。制約のある翻訳、長文の忠実性、またはリソースの少ない言語ペアがワークロードに含まれる場合、GPT-4.1 の信頼性はプレミアムの価値があるかもしれません。 どちらにもコミットせずに両方のモデルをテストする方法 ほとんどのローカライゼーションチームにとって、モデル選択の実際的な障害は、ベンチマークを理解していないことではなく、両方のモデルで独立した API 統合をセットアップし、同等のテスト条件を設計し、独自のコンテンツで意味のある評価を実行することの摩擦です。 MachineTranslation.com
はその障害を取り除きます。
プラットフォームはGPT-4.1とDeepSeek
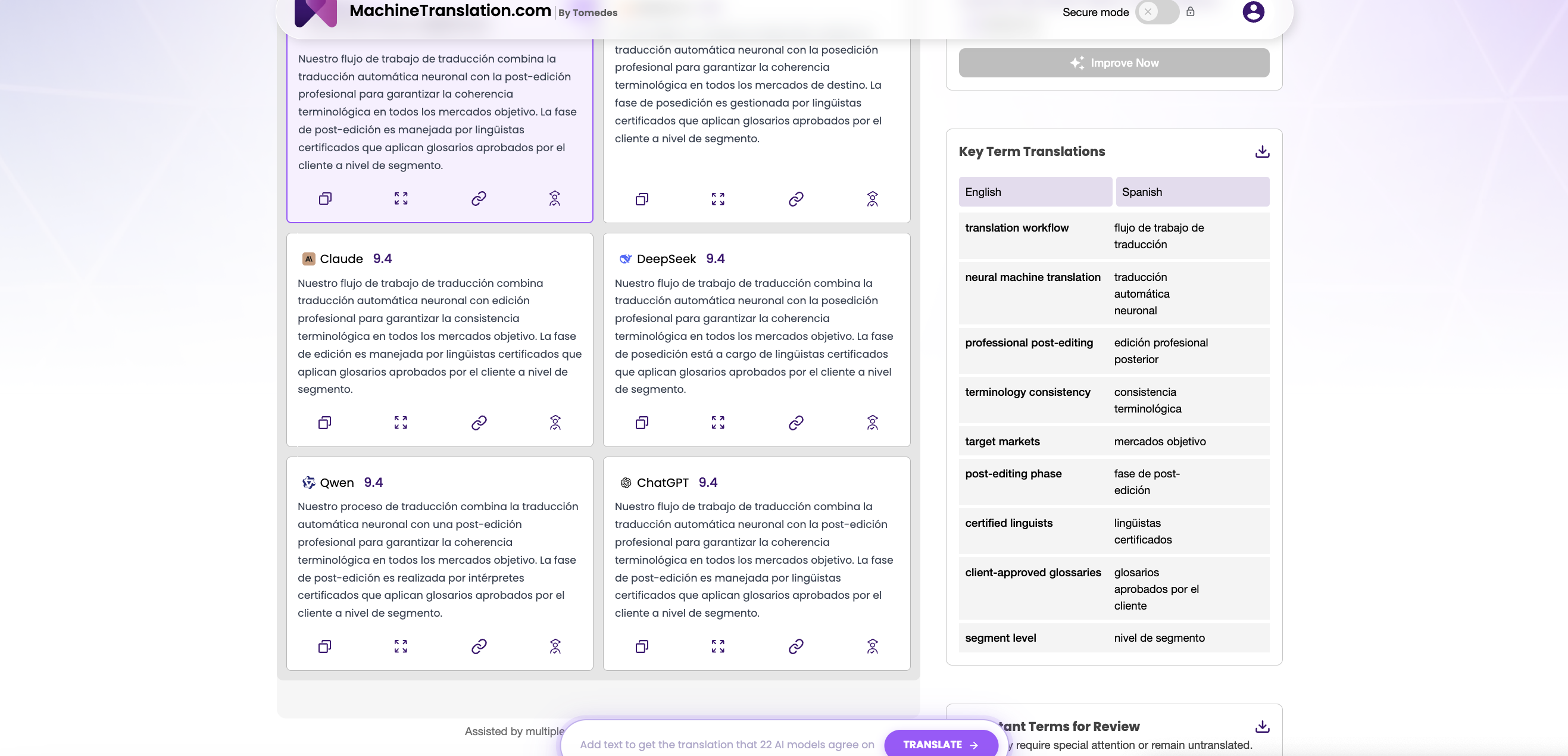
V3を並行して実行し、プロの翻訳者やローカライゼーションマネージャーが同じソーステキストを両方のモデルに同時に送信し、個別のAPIキーなしで、調達プロセスなしで、どちらのモデルにもコミットすることなく、リアルタイムで出力を比較できるようにします。これは、データセットレベルでのベンチマークパフォーマンスが、必ずしも特定のコンテンツでのパフォーマンスを予測するわけではないため重要です。WMT24中国語→英語ニューステキストで高いCOMETスコアを達成したモデルでも、貴社の特定の専門用語やドメインでは性能が低下する可能性があります。意思決定に関連する唯一の評価は、独自の制約、独自の言語ペアで、独自の文書に対して実施されたものです。
MachineTranslation.com が中立的なマルチモデルプラットフォームとしての位置づけにあるということは、GPT-4.1 または DeepSeek V3 のどちらかを優遇する商業的インセンティブがないことを意味します。プラットフォームの役割は、ご自身で判断するための比較データを提供し、評価が完了したら選択したモデルを本番規模で実行することです。もちろん、ほとんどのAIモデルがデフォルトの最良の翻訳として合意している翻訳も提供されます。
OpenAIモデルティア全体で評価しているチームにとって、GPT-4.1が他のOpenAIモデル(GPT-4.5やGPT-4oを含む)と比較してどうであるかは、モデルバージョンにコミットする前に有用なコンテキストを提供します。 そして、2025年初頭にDeepSeek
V3とGPT-4oを評価したチームにとって、この記事はGPT-4.1のリリースで何が変わったかをカバーしています。翻訳ワークフローにはどちらのモデルを選択すべきでしょうか?単一の推奨事項ではなく、以下のフレームワークは、ほとんどのプロの翻訳チームが役立つと感じる意思決定ロジックを反映しています。言語ペアから始めてください。
-
中国↔英語、アラビア語、または韓国語にポートフォリオが集中している場合、DeepSeek V3 の WMT24 でのパフォーマンスは、自然な最初のテストとなります。制約のある専門用語を用いて主にヨーロッパ言語で作業する場合、GPT-4.1 は初日からより一貫した出力を生成する可能性が高いです。
-
制約の複雑さを評価してください。単一レベルの制約(1つの用語集、1つのレジスタ)は、どちらのモデルでも適切に処理されます。マルチレベルの制約(用語集+フォーマット+翻訳禁止リスト+QAスコアリング)、GPT-4.1は現在より信頼性が高いです。
-
コスト差に対してボリュームをマッピングしてください。月間50万語未満であれば、APIの絶対的なコスト差は予算に大きな影響を与えない可能性があります。その閾値を超えると、DeepSeek V3のコストメリットは無視できなくなります。
-
データガバナンスの要件も考慮してください。ドキュメントをインフラストラクチャから持ち出せない場合、DeepSeek V3 セルフホスト版が、現時点で唯一の実行可能な選択肢となります。
-
ベンチマークではなく、ご自身のコンテンツで評価を実行してください。MachineTranslation.comを使用して、実際のワークロードから代表的なサンプルを両方のモデルに送信し、コミットする前に独自の品質基準で出力を評価してください。
これらのモデルが現在のAI翻訳の状況でどこに位置するかをより広く理解するには、2026年の最高のAI翻訳ツールが、LLMが専用翻訳インフラストラクチャと比較してどのように機能するかを含む、完全な競争分野をカバーしています。
よくある質問
1.GPT-4.1はDeepSeek V3よりも翻訳に優れていますか?
どちらのモデルも万能ではありません。GPT-4.1は、制約付き翻訳タスク、長文の忠実性、幻覚のリスクが高い低リソース言語ペアにおいてDeepSeek V3を上回ります。DeepSeek V3は、いくつかのWMT24ベンチマーク(特に中国語↔英語、アラビア語、韓国語)でGPT-4.1に匹敵するかそれを上回り、大規模運用またはセルフホストでは大幅に安価です。
2。DeepSeek V3 は GPT-4.1 よりも幻覚を起こしやすいですか?
リソースの多い言語ペアでは、幻覚の差は比較的小さいです。リソースの少ないペアや、まれな固有表現を含むドメイン固有のコンテンツでは、ギャップが拡大し、DeepSeek V3 はソースでサポートされていない追加や置換の割合が高いことが示されています。GPT-4.1は、特に長文ドキュメントにおいて、GPT-4oと比較して幻覚が減少したことを示しています。
3。DeepSeek V3を商用利用できますか?
はい。DeepSeek V3 は、ファインチューニングやセルフホスティングを含む商用利用を許可するMITライセンスの下でリリースされています。外部APIにドキュメントを送信できない組織は、DeepSeek V3を自社のインフラストラクチャにデプロイできます。GPT-4.1は、OpenAIの利用規約に基づきOpenAI
APIを使用する必要があり、セルフホスティングでは利用できません。中国語から英語への翻訳にはどのモデルが適していますか?
WMT24ベンチマークの結果に基づくと、DeepSeek V3は中国語↔英語において優位性があります。しかし、制約のある専門用語、法律上の正確さ、または複雑なフォーマットを伴う中国語→英語の翻訳においては、GPT-4.1の指示追従能力により、人間が後編集を行う本番ワークフローにおいてより信頼性が高くなります。
GPT-4.1とDeepSeek V3を、選択する前に並べてテストできますか?
はい — MachineTranslation.comは、両方のモデル(および20以上のモデル)を同時に実行し、個別のAPIアカウントや調達プロセスなしで、リアルタイムで独自のコンテンツでの出力を比較できます。
6.DeepSeek V3 は Claude と翻訳でどのように比較されますか?
Anthropic のモデルも評価しているチームにとって、Claude と DeepSeek V3 の比較では、翻訳に関連するシナリオ全体でのアーキテクチャ、精度、およびデプロイメントオプションの主な違いがカバーされています。