June 2, 2026
グロック 対 ラマ:翻訳向けどのAIモデルがより性能が良いですか?
2つの非常に異なる哲学が翻訳タスクに臨む。
GrokはxAIによって構築され、ウェブやXからのライブデータにリアルタイムで接続し、急速に変化する言語、つまり流行のスラング、時事問題、週ごとに変わる文化的な参照に特化して調整されています。LlamaはMetaによって構築され、世界にオープンソースとして公開され、ダウンロード、変更、および自身のインフラストラクチャへのデプロイが可能になるように設計されており、トークンあたりのコストはゼロです。
これらは両方ともMachineTranslation.comの24モデル合意システム内にあります。二人とも翻訳します。そして、それらは本当に異なる種類の翻訳作業に適しています。
この記事では、それぞれが実際に得意とすること、それぞれが苦手とすること、そして同じコンテンツで並べてテストしたときに何が起こるかについて説明します。
この記事では
- Grokとは何か、そしてどのように翻訳を処理するのか?
- Llamaとは何か、そしてどのように翻訳を処理するのか?
- Grok対Llama:翻訳品質の比較
- 翻訳においてLlamaはGrokより優れていますか?
- ドキュメント翻訳にはどちらが優れていますか?
- 翻訳のためにLlamaをローカルで実行できますか?
- MachineTranslation.comはGrokとLlamaの両方をどのように使用していますか?
- よくある質問
Grokとは何ですか、またどのように翻訳を処理しますか?

Grokはイーロン・マスクが設立したAI企業xAIによって開発されており、一般的なウェブデータとX(旧Twitter)からのライブコンテンツの組み合わせでトレーニングされています。現在のバージョンはGrok 3とGrok 4で、それぞれ2025年2月と7月にリリースされました。GrokがほとんどのAIモデルとアーキテクチャ面で一線を画すのは、リアルタイムのデータアクセスである。固定されたトレーニングスナップショットからではなく、推論中に現在のウェブコンテンツやXプラットフォームから情報を取得できるのだ。
翻訳においては、それが特定かつ限定的な方法で重要となる。Grokは、時事問題、トレンド用語、ネットスラング、そして急速に変化する文化的言及を参照するコンテンツの翻訳を特に得意としています。最近のニュース記事、製品発表、または3週間前に登場したバイラルなフレーズに関するソーシャルメディアの投稿を翻訳する必要がある場合、Grokのライブデータアクセスは、昨年のデータでトレーニングされたモデルにはないコンテキストを提供します。
これは真の利点です。これもかなり具体的なものです。
時間制約のあるコンテンツを除けば、Grokは翻訳において、ほとんどの最先端LLMと同様に振る舞います。主要な言語ペアには対応できますが、リソースの少ない言語には弱く、すべての単一モデルシステムが共有する構造的な制限、つまり自身の出力を検証するメカニズムがないという制約を受けます。
Grokは、消費者向けにはX Premium+(月額22ドル)またはSuperGrok(月額30ドル)を通じて、またxAIのAPIを通じて、入力トークン100万あたり約0.20ドルで利用可能です。セルフホストできません。カスタムデータでのファインチューニングは利用できません。
Llamaとは何ですか、またどのように翻訳を処理しますか?
LlamaはMetaのオープンウェイトAIモデルファミリーです。現行世代(Llama 4 MaverickおよびLlama 4 Scout)は2025年にリリースされ、機能と対応言語の両方でLlama 3から大幅な飛躍を遂げています。Llama 4は200以上の言語に対応しており、マルチモーダルであり、テキストだけでなく画像も処理できます。そのマルチモーダル機能は翻訳において実用的に重要です。埋め込み画像を含むドキュメント、スキャンされたPDF、テキストラベル付きのグラフなど、テキストのみのモデルでは処理できない方法で、Llama 4はこれらすべてを処理できます。
Llamaの決定的な特徴は、それを使って何ができるかということです。モデルの重みが商用利用ライセンスの下で公開されているため、適切なインフラを持つチームは、Llamaをダウンロードし、自社のサーバーで実行し、ドメイン固有のデータでファインチューニングし、外部APIに何も送信することなく機密性の高いコンテンツを処理できます。データレジデンシーがコンプライアンス要件である法律、医療、金融分野の翻訳ワークフローにおいて、これは「あれば良い」ものではなく、唯一許容される選択肢です。
標準的なコンテンツにおけるLlamaの翻訳出力は強力ですが、この分野で最高レベルではありません。Intentoの「翻訳自動化の現状2025」では、Llama 4 MaverickとLlama 4 Scoutを11の言語ペアで評価したところ、どちらのモデルも個別の言語ペア評価において上位14のソリューションには含まれていないことが判明しました。それは述べるべき正直なベンチマークです:Llamaは有能ですが、Intentoが評価したペアにおいては、GPT-4.1、Claude Opus 4、Gemini 2.5 ProといったモデルがLlamaを上回ります。Llamaがその地位を確立しているのは、オープンソースの柔軟性、言語の幅広さ、そして大量のワークフロー向けのコスト構造を通じてです。
Grok vs Llama:翻訳品質の比較
MachineTranslation.comがGrokとLlamaの両方を、同じ500語の英語からスペイン語へのマーケティングテキストでテストしたところ、Grokは10点中8.1点の品質スコアを記録し、Llamaは7.9点だった。同じ日本語訳のテキストでは、Grokが7.4点、Llamaが7.6点という結果になり、これはLlama 4のアジア言語における多言語学習データの深さの強さを反映したわずかな逆転です。スペイン語のテキストにおける2つのモデル間の一致率は74%でした。日本語のテキストでは61%に低下し、特に日本語の場合、2つのモデルがソーステキストの重要な部分を異なって解釈していることを示しています。
この一致データは注目に値します。GrokとLlamaが翻訳で一致した場合、その収束を信頼のシグナルとして捉えることができます — アーキテクチャが異なる2つのモデルが、異なるデータで学習され、同じ出力に到達しているのです。それらが乖離した場合、そのテストでの日本語の文章の39%でそうであったように、その乖離はフラグとなる。その箇所には真の解釈の曖昧さが含まれているか、あるいは一方のモデルが他方ではしない選択をしたかのいずれかである。
| Grok (Grok 4) | Llama (Llama 4 Maverick) | |
|---|---|---|
| リアルタイムデータアクセス | はい | いいえ |
| セルフホスト可能 | いいえ | はい |
| ファインチューニング可能 | いいえ | はい |
| 言語 | 40以上 | 200以上 |
| マルチモーダル(画像/ドキュメント) | 限定的 | はい |
| APIコスト | 入力トークン100万あたり約0.20ドル | 無料(セルフホストの場合) |
| 最適なコンテンツタイプ | トレンド/ソーシャル/ニュース | 大量、ドメイン固有 |
| MachineTranslation.com品質スコア(EN-ES) | 8.1/10 | 7.9/10 |
| MachineTranslation.com品質スコア(EN-JA) | 7.4/10 | 7.6/10 |
どちらのモデルも優位ではない。標準的なコンテンツでは、違いは確かにあるものの、劇的ではありません。どちらが実際に役立つかはユースケースによって決まります。そして、ほとんどのプロの翻訳ワークフローでは、どちらか一方が単独で正解となることはありません。
翻訳においてLlamaはGrokより優れていますか?
一概にそうとは言えません。答えは、コンテンツの種類とワークフローにほぼ完全に依存します。
ソース資料が時間的制約を伴う場合、Grokには優位性があります。過去数ヶ月で一般的に使われるようになったフレーズ(政治的なスローガン、文化的なミーム、急速に変化する業界で最近作られた専門用語など)が原文に登場した場合、Grokのリアルタイムウェブアクセスは、それをターゲット言語で正確に翻訳する可能性を高めます。Llamaの学習データにはカットオフがあります。Grokにはありません。
制御、コスト、または言語の幅が優先される場合、Llamaが有利です。社内で大量のドキュメントを処理するチーム、プライベートインフラでファインチューニングされたドメインモデルを運用するチーム、またはGrokの約40言語のカバー範囲外の言語で作業するチームにとって、Llamaはより実用的なツールです。200以上の言語サポートとマルチモーダル機能により、構造化されたエンタープライズワークフローにおいて、より多用途になります。
主要な言語ペアにおける標準コンテンツのプロフェッショナルな翻訳品質に関しては、両者は非常に近く、品質の差よりも他の要因(統合、コスト、インフラストラクチャ)が重要になります。
ドキュメント翻訳にはどちらが良いですか?
ほとんどの場合、Llamaです。
Llama 4のマルチモーダル機能が、複雑なドキュメントの決定的な要因となります。グラフが埋め込まれたPDF、スキャンされた契約書、画像を多用したプレゼンテーション、および複合メディアファイルはすべて、視覚情報とテキスト情報を合わせて処理できるモデルを必要とします。Grokのマルチモーダル機能は、現在のバージョンではより制限されており、企業翻訳が必要とするような文書処理ワークフロー向けには設計されていません。
フォーマット処理を超えて、機密性の高いコンテンツを含む文書には、セルフホスティングの選択肢が重要です。機密の合併文書を翻訳している法務チームは、そのテキストを外部APIに送信できません。患者記録を扱う医療機関には、オンプレミスで完結する翻訳が必要です。ローカルで動作するLlama 4は、これら両方の要件を満たします。xAIのクラウドインフラストラクチャを介してのみ動作するGrokは、そうではない。
全文にわたる一貫性が重要な長文ドキュメントの場合、MachineTranslation.comの内部分析が示すように、断片的に処理されたドキュメントは、全体として処理されたものと比較して、用語の不整合率が28%高くなります。GrokとLlamaはどちらもLLMとして文書全体のコンテキストをかなりうまく処理しますが、非常に長い文書(法的合意書、年次報告書、技術マニュアルなど)の場合、MachineTranslation.comの24モデル合意を介して実行すると、単一のモデルが40,000語の文書全体で導入する可能性のあるずれを捉えます。
Llamaをローカルで翻訳に実行できますか?
はい、特定のユースケースでは、これがまさに正しいアプローチです。
MetaはLlamaモデルの重みを商用利用ライセンスの下で公開しています。大規模なAIモデルを実行するためのインフラを持つチームは、Llama 4 MaverickまたはScoutをダウンロードし、完全にオンプレミスで運用できます。これにより、データが外部サーバーに送信されることはなく、トークンごとのAPIコストも発生せず、モデルを独自の専門用語、クライアント固有の用語集、またはドメイン固有の並列データでファインチューニングできます。
実用的な要件は多大です:Llama 4 Maverick は、多大な計算リソースを必要とする大規模モデルです。既存のGPUインフラを持たないチームにとって、セルフホスティングの経済性を考えると、代わりにクラウドAPIを利用する方が有利になることがよくあります。しかし、すでに自社ハードウェアでAIワークロードを実行している組織(企業テクノロジー、医療システム、法律・金融機関)にとっては、セルフホスト型Llamaは、コンプライアンス、コスト、品質の要件を同時に満たす翻訳インフラとなります。
信頼性の高い商用APIではカバーされていない、あまり一般的でない言語ペアを含む200以上の言語で多言語出力を必要とするチームにとって、Llamaのオープンなトレーニングデータは、いかなるクローズドモデルよりも適応性が高いものにします。
MachineTranslation.comがGrokとLlamaの両方をどのように使用しているか
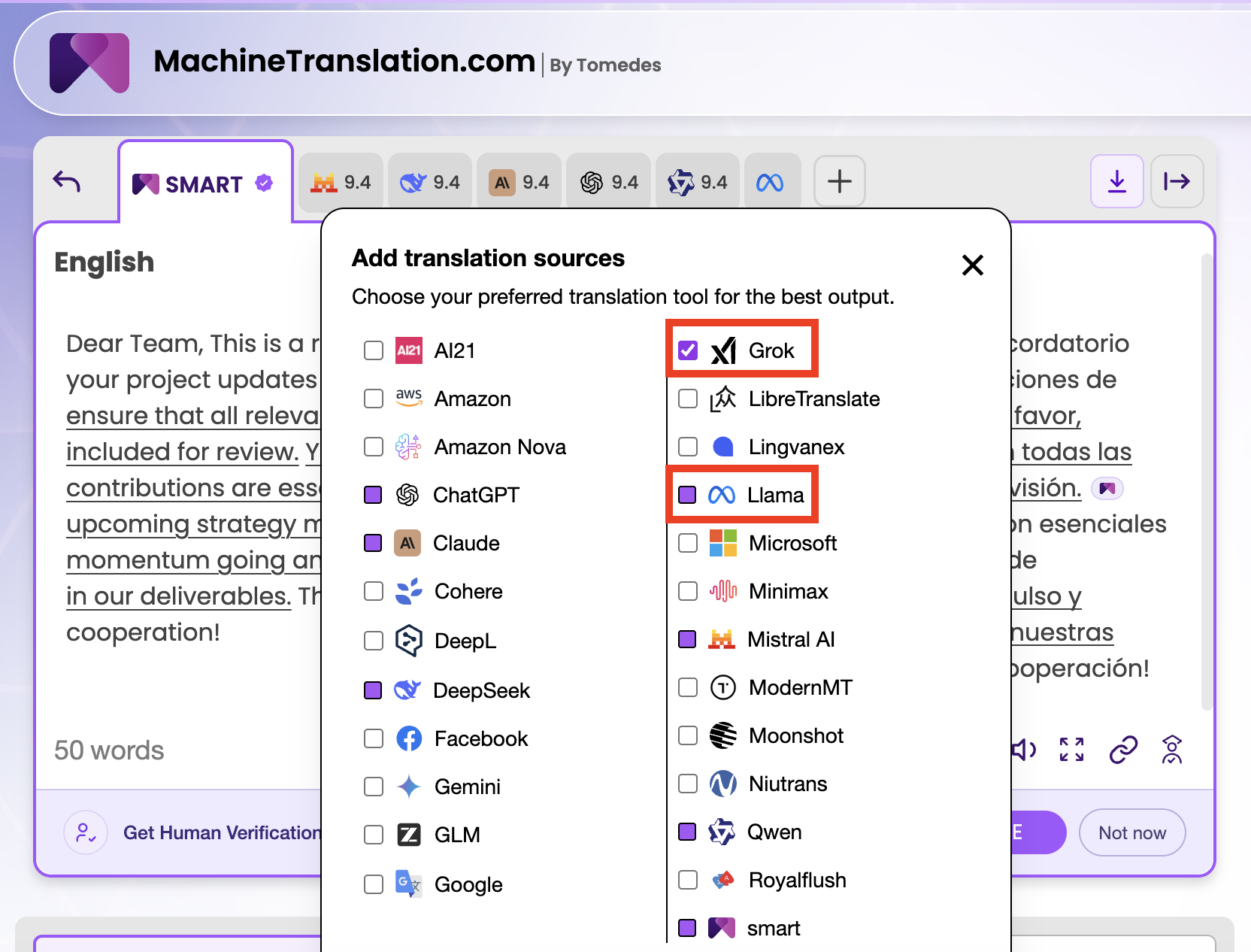
MachineTranslation.comは、プラットフォームの24モデル合意システムであるSMARTの一部として、GrokとLlamaの両方を実行しています。テキストや文書を翻訳すると、両方のモデルが独立した出力を生成します。SMARTは24の出力すべてを比較し、大多数のモデルが収束する翻訳を、各個別のモデルの品質スコアとともに提示します。
その実用的な結果として、Grokが生成したもの、Llamaが生成したもの、そして24のモデルのコンセンサスが同意するものが表示されます。GrokとLlamaが同じ英語からスペイン語へのテキストでそれぞれ8.1と7.9のスコアを獲得し、SMARTコンセンサスが9.4のスコアを獲得した場合、その差はあなたに何か意味のあることを教えてくれるでしょう。コンセンサス出力は、両方のモデルが正しく認識したものを統合し、それぞれが個別に導入したエラーを除外します。
MachineTranslation.comでの社内テストでは、SMARTコンセンサスアプローチは、いずれか単一のモデルに依存する場合と比較して、致命的な翻訳エラーのリスクを90%削減します。この記事での具体的な比較(英語からスペイン語への翻訳でGrokが8.1、Llamaが7.9)では、同じテキストに対するSMARTコンセンサスは9.4点を記録し、GrokとLlamaは74%の文で一致し、残りの26%の不一致はコンセンサス出力によって解決されました。
GrokもLlamaも盲目的に信頼されているわけではありません。24モデル合意が重要なシグナルです。
GrokとLlamaの出力をMachineTranslation.comで直接比較できます。無料で、サインアップは不要です。両方実行するどこで一致するかを見るどこで分岐するか見てください。翻訳が実際に難しかったのは、乖離の部分でした。
よくある質問
1.ラマは翻訳においてGrokより優れていますか?
一概には言えません。Grokは、最近の出来事、流行語、現在の文化的言及といったリアルタイム性の高いコンテンツにおいて、Llamaよりも優れた性能を発揮します。これは、Grokのリアルタイムのウェブアクセスが、Llamaの静的な学習データでは得られない文脈を提供するためです。Llamaは、大量のドキュメントワークフロー、オンプレミスに保持する必要があるコンプライアンスに配慮が必要なコンテンツ、およびGrokの約40言語の対応範囲外の言語ペアにおいて、Grokを上回ります。主要な言語ペアにおける標準的なコンテンツでは、それらの間の品質差は小さい。
2.Grokが翻訳において他のAIモデルと異なる点は何ですか?
Grokの主な差別化要因はリアルタイムデータアクセスです。ほとんどのAIモデル(Llamaを含む)は、知識のカットオフがある固定データセットで学習されていますが、Grokは推論時にライブのウェブコンテンツやXプラットフォームのデータから情報を取得できます。最近作られた用語、流行の文化的な言及、または時事問題に関するコンテンツを含む翻訳の場合、これにより、Grokは静的モデルでは再現できない事実の正確性において優位に立ちます。
3.Llama 4は翻訳においてGrokより優れていますか?
Llama 4 MaverickとLlama 4 Scoutは、Grokの約40言語と比較して200以上の言語をサポートしており、Llama 4のマルチモーダル機能は、Grokが効果的に処理できない画像埋め込みドキュメントやスキャンされたPDFを処理できます。Intentoが評価した主要な言語ペアにおける生の翻訳品質に関して言えば、どちらのモデルも上位14のソリューションには入っていませんでした。両者とも能力はありますが、最高水準ではありません。Llama 4 の実用的な利点は、その広範さ、オープンソースの柔軟性、そしてセルフホスティングのオプションです。
4.Llamaは翻訳に利用できますか?
はい。Llama 4 MaverickとLlama 4 Scout(現行世代)は、200以上の言語をサポートし、主要な言語ペアにおいて他の最先端LLMと同等の翻訳出力を生成します。LlamaはAPI経由で、またはプライベートインフラストラクチャに自己ホストして利用できるため、データプライバシーやコンプライアンス要件を持つ組織にとって特に適しています。ドメイン固有のデータでファインチューニングすることで、専門的なコンテンツでのパフォーマンスを向上させることもできます。
5.多言語コンテンツにはどちらが良いですか:グロックかラマか?
ラマの方が、言語の幅広さでかなり優位です。Llama 4は200以上の言語をサポートしており、Grokは約40の言語をサポートしています。幅広い言語ペア(特にアフリカ言語、南アジア言語、先住民族言語など)を扱うチームにとって、Llamaの学習データカバー範囲は大幅に広範です。主要なヨーロッパおよび東アジアの言語ペアでは、両モデルは同等の性能を発揮します。
6.MachineTranslation.comはGrokとLlamaをどのように併用していますか?
GrokとLlamaは両方とも、MachineTranslation.comのSMART 24モデル合意システムの一部として同時に動作します。すべての翻訳は、全24モデルを独立して通過します。SMARTは、多数派が合意した出力を特定し、各モデルの品質スコアとともに、それを結果として提供します。ユーザーは、Grokの個別の出力、Llamaの個別の出力、および24モデルすべてが合意した内容を統合したコンセンサス翻訳を見ることができます。