July 23, 2025
Mistral vs LLaMA: A 2025 Comparison of Performance, Cost, and Use Cases
If you're exploring open-source language models in 2025, two names dominate the conversation: Mistral and LLaMA. These AI powerhouses offer massive potential for tasks like content generation, coding, customer support, and accurate translations. Whether you're a developer, business owner, or translator, choosing between them can directly impact your project's efficiency, cost, and quality.
In this article, we'll break down Mistral vs LLaMA using real benchmarks, practical examples, and usability insights. We'll compare their strengths in professional translation, speed, memory use, and domain-specific applications. By the end, you'll know which model best suits your needs.
What is Mistral?
Mistral is a family of open-weight Large Language Models (LLMs) developed to offer fast, efficient, and high-quality text generation. Known for its lightweight architecture and competitive performance, Mistral is designed to deliver advanced language capabilities while maintaining lower computational requirements compared to many larger LLMs. This makes it ideal for integration into applications where speed and resource-efficiency matter.
Mistral is particularly notable for its strong performance in multilingual tasks and its open-access foundation, which encourages broader use across research and commercial applications. MachineTranslation.com includes Mistral as one of the aggregated sources to give users access to an additional layer of translation intelligence, especially in projects where agility and responsiveness are key.
What is LLaMA?
LLaMA (Large Language Model Meta AI) is a series of cutting-edge LLMs developed by Meta (formerly Facebook). Designed for both academic and commercial use, LLaMA models are known for their balanced trade-off between model size and output quality. With a focus on efficiency and transparency, LLaMA has become a popular foundation model for developers and researchers looking to build powerful language-based applications.
LLaMA excels in producing high-quality translations and natural-sounding outputs, particularly in English and other widely used languages. At MachineTranslation.com, LLaMA is one of the integrated sources in our multi-engine system, helping users compare outputs and choose the most contextually accurate translation from a diverse pool of LLMs.
Architecture and model design
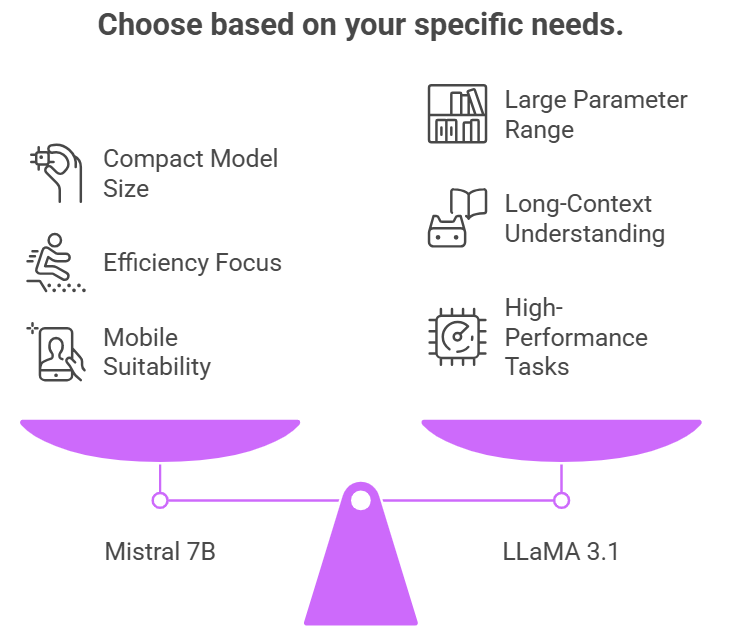
Both Mistral and LLaMA are decoder-only transformer models, but they take very different routes to performance. Mistral 7B is compact, fast, and surprisingly capable, while LLaMA 3.1 offers models ranging from 8B to 405B parameters. If you're looking for agility with minimal hardware, Mistral wins on efficiency, especially in real-time applications.
The Mistral Large 2 vs LLaMA 3.1 405B matchup showcases this contrast. LLaMA shines with long-context understanding, but Mistral still holds its ground in low-latency tasks. For mobile, embedded, or regional services, Mistral's smaller footprint is ideal.
Examining the Mistral vs LLaMA performance and benchmarks
Let's get into numbers. In recent benchmark tests like MMLU and GSM8K, Mistral 7B vs LLaMA 3.1 8B shows near-identical performance, despite the size gap. That means you can get competitive results without paying for extra computational overhead.
For code generation, LLaMA 3 generally performs better due to deeper training on coding data. However, Mistral Nemo vs LLaMA 3.1 8B still shows Mistral holding its own in real-world tasks like Python scripting and web automation. This makes Mistral a budget-friendly pick for light development tasks.
Latency, speed, and efficiency
When speed matters, Mistral vs LLaMA results are clear. Mistral has faster time-to-first-token and better token throughput, especially in quantized environments like GGML and Ollama. In practice, this translates to smoother performance in chatbots and multilingual websites.
For instance, when running on a Raspberry Pi 5, Mistral 7B gives real-time responses while LLaMA 3 models struggle. If you’re building low-latency tools or apps that require instant interaction, Mistral is hard to beat. It's also ideal for translation tools that must process multiple sentences per second.
Cost and deployment considerations
Choosing between Mistral vs LLaMA 3.2 often comes down to cost. On platforms like Amazon Bedrock, Mistral 7B costs up to 60 percent less per million tokens than LLaMA 3.1 8B. That’s a huge win if you're translating thousands of product descriptions or support messages every day.
Licensing is another area where Mistral shines. Mistral models come with an Apache 2.0 license, making them easy to use commercially. In contrast, LLaMA 3.1 vs Mistral involves stricter Meta licensing rules that might complicate your product roadmap.
Mistral vs. LLaMA: Cost and Licensing Overview | ||
Feature | Mistral 7B | LLaMA 3.1 8B / 3.2 |
Approx. Cost / 1M Tokens | $0.40 USD (on Amazon Bedrock) | $1.00 USD (est.) |
Cost Efficiency | ~60% cheaper | Higher cost per usage |
License Type | Apache 2.0 (permissive, open) | Meta license (restricted use) |
Commercial Flexibility | High – suitable for any use case | Limited – may require approval |
Best For | Scalable deployments, startups | Research, internal tools |
Mistral vs LLaMA: Evaluating translation capabilities
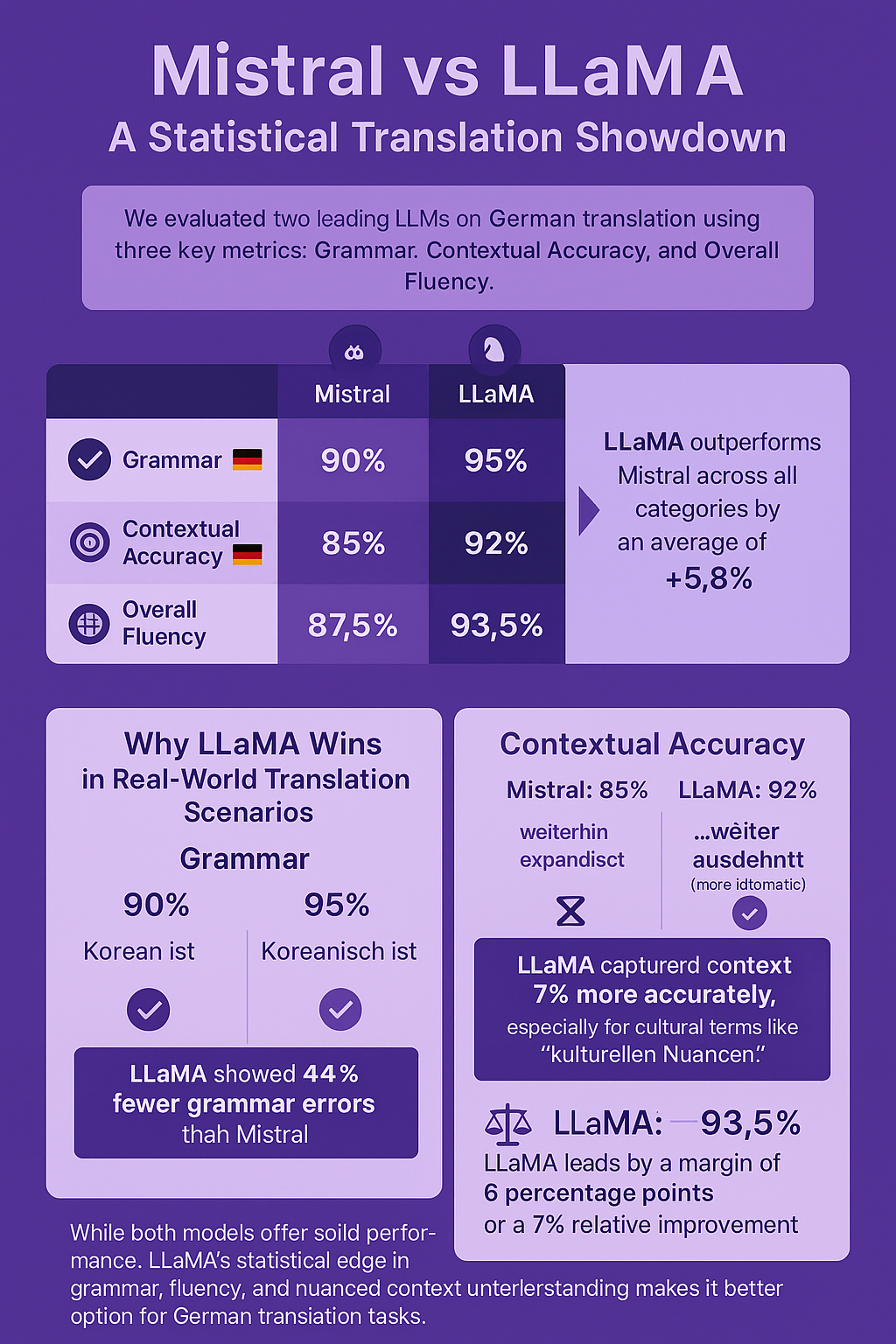
The Mistral vs LLaMA comparison focused on evaluating their translation capabilities across three key metrics: grammar, contextual accuracy, and overall fluency. The translations from Mistral (Image 1) and LLaMA (Image 2) were assessed in detail. Mistral scored 90% in grammar, with minor errors such as "Korean ist" instead of the correct "Koreanisch ist." In contrast, LLaMA achieved a higher grammar score of 95%, demonstrating more consistent German syntax.

For contextual accuracy, Mistral earned 85%, with phrasing that occasionally felt less natural. LLaMA, however, reached 92% by aligning terms like "kulturellen Nuancen" more effectively with the intent of the source text. Overall, LLaMA outperformed Mistral, achieving a weighted accuracy score of 93.5% versus Mistral’s 87.5%.

The differences in the Mistral vs LLaMA evaluation stem largely from LLaMA’s stronger command of German grammar and its ability to select more nuanced word choices, such as "weiter ausdehnt" instead of Mistral’s less idiomatic "weiterhin expandiert." While both models produce high-quality translations, LLaMA’s edge in fluency and precision makes it the stronger performer in this comparison.
Instruction tuning and prompt following
Instruction tuning is how models learn to follow your tone, style, or domain-specific language. Between Mistral vs LLaMA instruction tuning, Mistral is easier to adapt for informal content, while LLaMA handles formal contexts better.
We’ve seen this play out in customer support workflows. Mistral Nemo vs LLaMA 3.1 tests show that Mistral adapts better to brand voices in quick replies, while LLaMA is great for long, structured policy responses. This flexibility is key for anyone doing professional translation where tone and accuracy must align.
Prompt-following also differs. LLaMA tends to over-explain, while Mistral keeps things concise. That gives you more control when building user-facing tools.
Developer experience and ecosystem
Both models are supported on Hugging Face, Ollama, and LM Studio. If you’re a developer, you'll love how Mistral vs LLaMA integrations simplify model switching without major infrastructure changes.
Mistral runs beautifully on local devices and edge hardware. It integrates well with tools like transformers.js and gguf for low-latency environments. LLaMA, while powerful, often requires more setup and GPU memory.
Fine-tuning workflows is smoother with Mistral due to its smaller size and active community. Whether you're training on glossaries, support scripts, or legal data, Mistral gets you results faster. And that’s vital for those of us offering professional translations with client-specific guidelines.

Model variants: Mistral-Nemo, Mixtral, and LLaMA 3.2
As of mid-2025, both camps have expanded their lineups. You’ll see comparisons like Mistral Nemo vs LLaMA 3.1 8B and Mixtral vs LLaMA 3.2 appearing in forums and dev blogs.
Mistral-Nemo is particularly impressive for real-time translation and chat tasks. It combines Mistral's compact architecture with improvements in multi-turn reasoning. Meanwhile, LLaMA 3.2 vs Mistral debates often center on how much context you need versus how fast you want results.
If your team is building voice-to-voice translation or global support agents, Mixtral’s speed will surprise you. It handles bursts of dialogue and frequent model switches without stalling. But if you’re publishing white papers or academic content, LLaMA’s massive context wins.
Conclusion
Choosing between Mistral vs LLaMA isn’t about finding the best model in general. It’s about selecting the right model for your specific translation, business, or development goals. Both offer accurate translations, scalable AI, and the flexibility to meet diverse needs.
If speed, simplicity, and accessibility matter most, Mistral delivers big. If depth, consistency, and broader context are what you need, LLaMA steps up. Either way, you’re making a strong choice for professional translation and smarter AI tools.
Subscribe to MachineTranslation.com and translate up to 100,000 words every month—fast, accurate, and entirely free. Customize output, compare top AI engines, and refine translations with tools built for professionals who value precision and control.

By Clarriza Heruela
Clarriza Mae Heruela graduated from the University of the Philippines Mindanao with a Bachelor of Arts degree in English, majoring in Creative Writing. Her experience from growing up in a multilingually diverse household has influenced her career and writing style. She is still exploring her writing path and is always on the lookout for interesting topics that pique her interest.
Share: