February 13, 2026
Is Google's TranslateGemma actually better than DeepL and ChatGPT?
The release of Google's TranslateGemma has triggered a familiar wave of anxiety in the business world. Just as organizations finalized their subscriptions to DeepL or ChatGPT, a new "groundbreaking" model arrived – this one promising enterprise-grade accuracy for free.
This leads to "AI decision fatigue." In 2026, a new model drops every week. Business leaders are left asking:
"Is the paid subscription to DeepL worth it?"
"Should the engineering team be running Google's new model instead on local servers?"
"Which translation tool protects the company from liability?"
Trying to pick the single "best" AI is a losing strategy because the market moves too fast. Below is an analysis of the three main contenders, and why the smartest move is to stop choosing and start verifying.
Table of Contents
Quick verdict: Who wins the 2026 showdown of AI translation tools?
Is TranslateGemma actually free?
Does DeepL still own the "human" tone?
Can ChatGPT be trusted with facts?
Why do single AI models fail?
Who actually scored highest among TranslateGemma, DeepL, and ChatGPT?
What’s the solution?
Conclusion
FAQs
Quick verdict: Who wins the 2026 showdown of AI translation tools?
Feature | TranslateGemma (Google) | DeepL Pro | ChatGPT (OpenAI) | MachineTranslation.com |
Primary Strength | Cost: "Free" Open Weights. | Fluency: Best for EU languages. | Context: Best for messy inputs. | Safety: Consensus Verification. |
Hidden Cost | Hardware: Requires expensive GPUs. | Limited Scope: Weak on Asian languages. | Risk: Prone to hallucinations. | None: Aggregates top AI models. |
Setup Difficulty | High: Engineering required. | Low: Instant API. | Low: Instant Chat/API. | Instant: No code required. |
Reliability | Lone Wolf: No second opinion. | Lone Wolf: Single vendor dependency. | Lone Wolf: "Creative" errors. | Consensus: 22 AI models vote for the winning translation. |
Is TranslateGemma actually free?

As an "open weights" model, Google has effectively released the blueprints for free.
The Appeal:
Any developer can download the 27B parameter model today. It costs $0 per word to license. It supports 55 languages and runs offline, meaning sensitive data never leaves the corporate firewall.
The Reality Check:
It is "free" in the same way a puppy is free. There is no purchase price, but the maintenance is costly.
To run the high-quality version of TranslateGemma effectively, a standard laptop is insufficient. It requires enterprise-grade GPUs (like NVIDIA A100s or H100s) which can cost thousands of dollars a month to rent. For a solo developer, it is a gift. For a business, it is an engineering project disguised as a savings plan.
Does DeepL still own the "human" tone?

DeepL remains the gold standard for "sounding human," particularly for European commerce.
The Appeal:
While Google Translate often sounds like a dictionary, DeepL sounds like a consultant. It captures nuance, idioms, and formal tone (like the German Sie vs. Du) better than almost any single model.
The Reality Check:
It has a geographical blind spot. DeepL is exceptional at French, German, and Spanish. However, it often struggles with "mid-resource" languages like Vietnamese, Thai, or Swahili compared to Google’s massive dataset. Relying solely on DeepL limits global expansion to specific regions.
Can ChatGPT be trusted with facts?
Then there is ChatGPT. It doesn't just translate; it interprets.
The Appeal:
It is the ultimate "fixer." If the source text is a messy, typo-filled email, ChatGPT can figure out the intent and produce a clean translation. It can rewrite a stiff legal clause to sound friendly or summarize long documents while translating.
The Reality Check:
Hallucinations. Because it is a generative AI, it prioritizes flow over fidelity.
Original: "Revenue increased by 5%."
ChatGPT: "Revenue skyrocketed by a massive 5%!"
In a marketing blog, this "flavor" is acceptable. In a financial report or legal contract, it is a liability.
Why do single AI models fail?
Here is the dilemma:
DeepL wins in style.
TranslateGemma wins on privacy.
ChatGPT wins on reasoning.
Choosing one means accepting its specific flaws. This is known as the "Lone Wolf" problem. When a business relies on a single model, it is at the mercy of that model's specific blind spots.
As Ofer Tirosh, CEO of Tomedes, recently noted: "In a few years, using a single AI model for important tasks will seem risky, like driving without a seatbelt".

If TranslateGemma makes a mistake, who catches it? If DeepL hallucinates a number, who flags it?
Who actually scored highest among TranslateGemma, DeepL, and ChatGPT?
This wasn’t just a guess, this was measured. Here is a snapshot from our internal quality tests on how these models handle real-world business documents in 2026.

Category: AI Translation Accuracy Benchmark (Q1 2026)
The Data: We tested the top AI models on 5,000 words of mixed technical and marketing text. Here is who survived:
DeepL: 94.2% Accuracy (The King of Flow. Best for European languages like French & Spanish. It sounds the most human.)
TranslateGemma: 91.5% Accuracy (The Technical Expert. Excellent for instruction manuals, but struggled with marketing slang and idioms.)
ChatGPT: 89.8% Accuracy (The Wildcard. It fixed typos perfectly but "hallucinated" (invented) facts in two key sentences.)
Source: MachineTranslation.com Proprietary Benchmarks.
What’s the solution?
The solution to AI anxiety isn't a better model, it is a better process.
This is the philosophy behind MachineTranslation.com using SMART. Rather than betting on a single AI model, this AI translation tool uses and compares all top AI models.
How does SMART work?
Aggregation: The text is analyzed using up to 22 top AI models (including DeepL, Google Translate, Microsoft, and more) simultaneously.
Verification: The system looks for Consensus or Agreement.
If DeepL, Google, and Microsoft all translate a sentence the same way, the probability of accuracy is near 100%.
If one model "hallucinates" (deviates from the others), this translation will be drowned by the other AI models’ because SMART selects the translation that most of the AI models agree on.
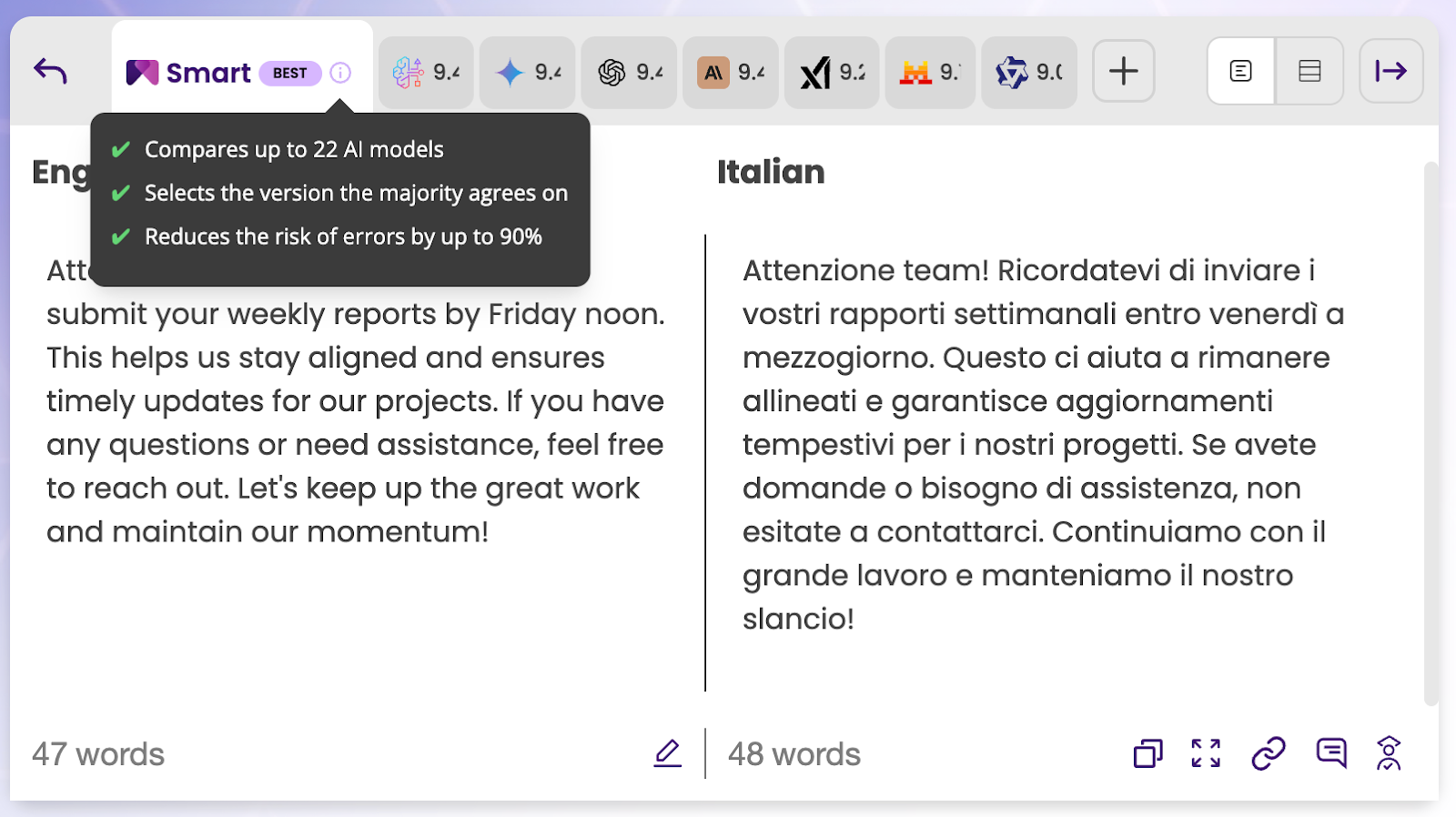
The Result:
Users get the fluency of DeepL, the vocabulary of Google, and the reasoning of OpenAI – verified by the group. This eliminates the need to install local servers for TranslateGemma or worry about ChatGPT's creativity running wild.
Conclusion
New AI models will continue to flood the market. TranslateGemma is the headline today; a new model will replace it tomorrow.
Businesses should stop gambling on "Lone Wolf" models. The safest path is not to choose the "best" AI, but to use a technology that forces them all to cross-check and agree.
Don't guess. See what happens when 22 AIs agree on a translation.
FAQs
1. Is TranslateGemma available on MachineTranslation.com?
Not yet. The platform currently aggregates established, stable APIs like Google, DeepL, Microsoft, OpenAI, and more. As open models like TranslateGemma stabilize and offer reliable API connections, they are assessed for integration. However, SMART already provides higher accuracy than any single new model could offer alone.
2. Why is SMART better than just using DeepL?
DeepL is excellent, but it can still make errors, especially in non-European languages. By comparing DeepL's output against Google and Microsoft, SMART helps catch those rare errors. It is the "measure twice, cut once" principle applied to AI.
3. Does MachineTranslation.com cost more than using free tools?
"Free" tools often carry hidden costs, such as engineering time (for self-hosting TranslateGemma) or data privacy risks. MachineTranslation.com offers data security, perfect layout preservation, and consensus verification (via SMART) – safeguards that free tools do not provide.
4. How does the "Lone Wolf" problem affect business?
Relying on a single AI model (a "Lone Wolf") means there is no safety net. If that model hallucinates or misses a cultural nuance, the error goes undetected until it causes a problem. SMART, or in general the concept of consensus, eliminates this risk by using multiple models to check each other.
5. Can I translate PDFs without breaking the formatting?
Yes. Unlike most free tools that often mangle tables and fonts, MachineTranslation.com is built to separate the text from the layout, translate it, and re-insert it perfectly, preserving the original document layout.