July 10, 2025
2025年のQwen対LLaMA:トップAIモデルを深く掘り下げる
オープンソース AI に注目しているなら、おそらく Qwen と LLaMA について聞いたことがあるでしょう。これら 2 つの言語モデルは、幅広いタスクにわたるパフォーマンス、アクセシビリティ、有用性により、2025 年に大きな話題を呼んでいます。この記事では、完全な比較をご案内し、どれがあなたのニーズに最も適しているかを判断できるようにします。
目次
Qwen vs LLaMA:AI LLM の全体的なパフォーマンスの内訳
Qwen と LLaMA とは何ですか?
Qwen(アリババクラウド製)
Qwen は「Query-Wise Enhanced Network」の略で、Alibaba Cloud が開発した多言語基盤モデルです。Qwen は中国語やその他のアジア言語に重点を置いて構築されており、流暢さ、語調への配慮、文化的正確さで急速に評判を獲得しています。
特徴
中国語、韓国語、日本語、東南アジアの言語に最適化されています。
文脈、慣用表現、形式に基づいた翻訳において優れたパフォーマンスを発揮します。
Qwen-2 のような微調整されたバリアントによる強化された命令の追従。
アジアの主要なクラウドおよび API プロバイダーを通じて利用できます。
長所
アジア言語の流暢さにおいてクラス最高。
トーンコントロール、敬語、ローカリゼーションのニュアンスに優れています。
コンテキストの高いビジネス指向のドキュメントを適切に処理します。
地域言語の改善に伴い頻繁に更新されます。
短所
ロングテール言語やリソースの少ないヨーロッパ言語ではパフォーマンスが低下します。
LLaMA と比較するとオープンソース エコシステムは限られています。
西洋の開発者スタックへの統合には回避策が必要になる場合があります。
LLaMA(Meta AIによる)
LLaMA、つまり「Large Language Model Meta AI」は、Meta のオープンウェイト モデル シリーズです。2025 年に LLaMA 3 がリリースされ、多言語翻訳からエンタープライズ自動化まで、幅広いタスクにわたって、独自仕様およびオープンソースの LLM と直接競合するようになりました。
特徴
80 億から 650 億以上のパラメータを持つモデルを備えた高度にスケーラブルなアーキテクチャ。
研究および商業利用に自由にご利用いただけます。
100 以上の言語にわたるバランスの取れた多言語サポート。
コード生成、要約、QA における優れたパフォーマンス。
長所
オープンウェイトで開発者に優しいため、微調整や展開が容易です。
多様なドメインと言語にわたる信頼性の高いパフォーマンス。
構造化編集、メモリベースのワークフロー、フィードバック ループに適しています。
LangChain、Hugging Face、MachineTranslation.com の集約エンジンなどのツールでシームレスに動作します。
短所
Qwen や他の言語と比較すると、アジア言語ではパフォーマンスが劣る場合があります。
文脈の濃いテキストでは、語調の繊細さと慣用的な正確さが欠けています。
地域市場での Qwen の流暢さに合わせるには、チューニングまたはハイブリッド システムが必要です。
Qwen vs LLaMA:AI LLM の全体的なパフォーマンスの内訳
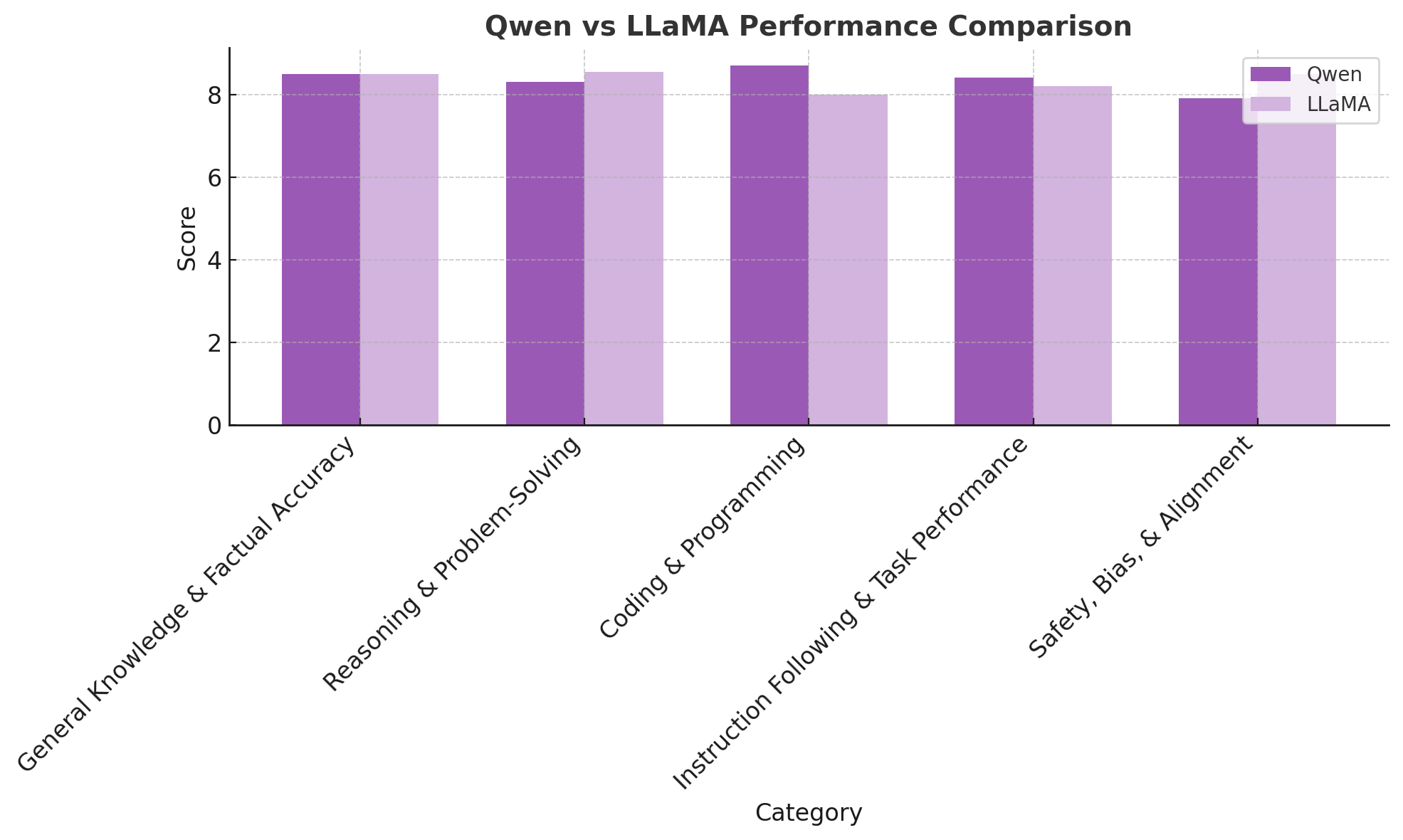 このグラフは、2 つの高度な AI 言語モデルである Qwen 2 と LLaMA 3 を 4 つの主要な評価カテゴリで直接比較したものです。
このグラフは、2 つの高度な AI 言語モデルである Qwen 2 と LLaMA 3 を 4 つの主要な評価カテゴリで直接比較したものです。
一般知識&事実の正確性では、Qwen 2 は 8.5 のスコアを獲得し、テスト条件に応じて 8.2 ~ 8.8 の範囲となる LLaMA 3 をわずかに上回りました。推論でも優位は続く&問題解決では、Qwen は 8.3 を獲得しましたが、LLaMA のパフォーマンスはより広範囲にわたり、重複しながら 8.1 ~ 9.0 の範囲に及びました。
このギャップは、技術集約型の分野ではさらに顕著になります。コーディング&プログラミングでは、Qwen 2 は 8.7 という高いスコアを獲得しましたが、LLaMA は 7.5 ~ 8.5 の範囲で後れを取っており、構造化ロジック タスクにおける Qwen の一貫性と強さが際立っています。
同様に、指示に従う場合&タスクパフォーマンスでは、Qwen のスコアは 8.4 であるのに対し、LLaMA のスコアはわずかに低い 7.8 ~ 8.6 です。これらの結果は、特に精度、明瞭性、文脈の正確性が求められる実用的なアプリケーションでは、Qwen 2 がより信頼性の高い出力を提供できる可能性があることを示唆しています。
多言語対応
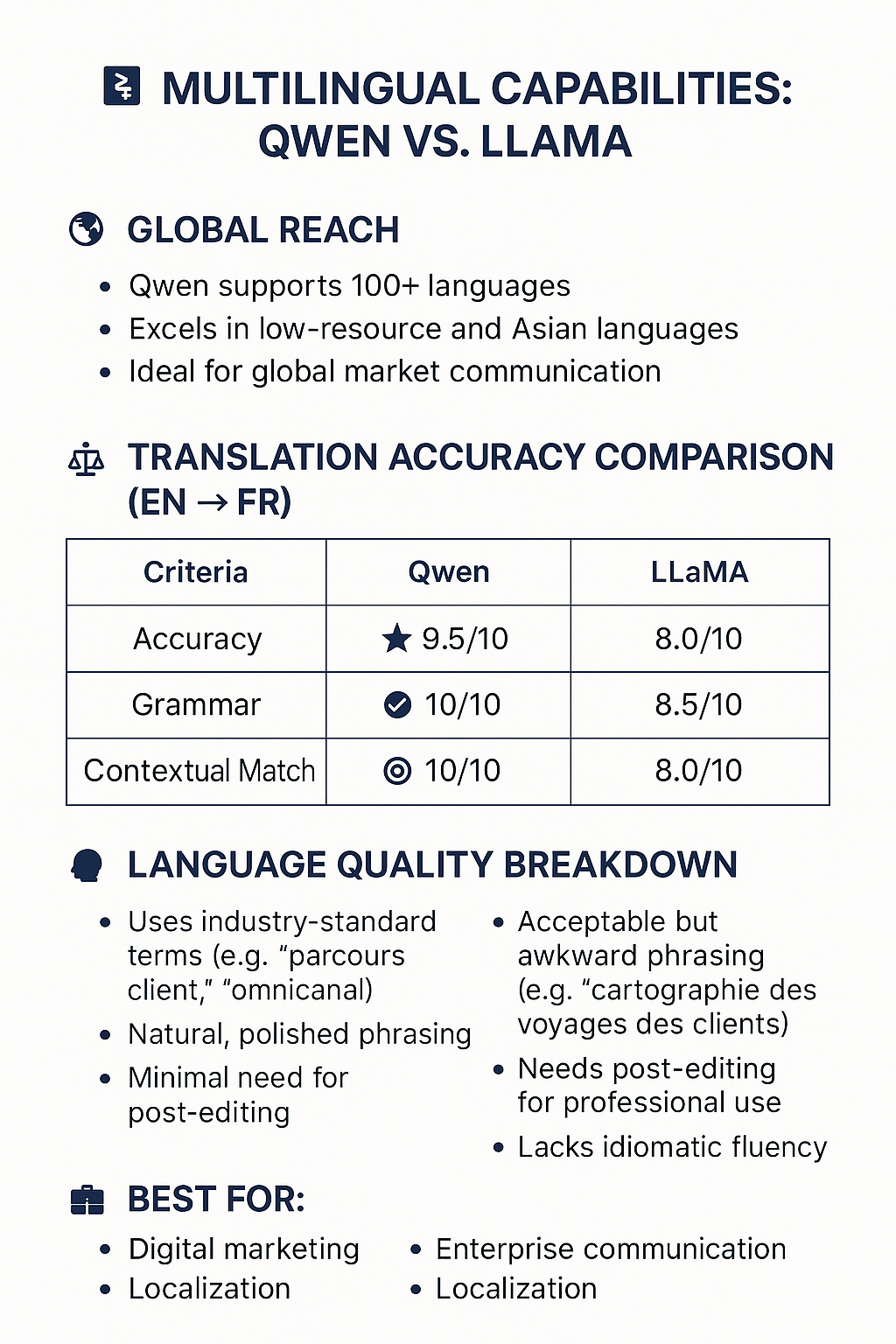
特にグローバル市場で働いている場合、多言語の強みについてお話ししましょう。Qwen は 100 を超える言語をサポートし、リソースが少ないタスクやアジア言語のタスクでも優れたパフォーマンスを発揮します。
Qwen は英語からフランス語への翻訳において優れたパフォーマンスを発揮し、正確性 (9.5/10)、文法 (10/10)、文脈の忠実度 (10/10) においてほぼ完璧なスコアを達成しました。翻訳は正確で、「parcours client」や「omnicanal」などの業界標準の用語を使用しながら、完璧な文法と自然な言い回しを維持しています。データにより、Qwen は、特にデジタル マーケティングなどの専門分野において、プロフェッショナル グレードの翻訳にとってより信頼性の高いモデルであることが明確に示されました。

対照的に、LLaMA は正確性 (8.0/10)、文法 (8.5/10)、文脈 (8.0/10) のスコアが低く、ぎこちない「顧客の旅の地図」のような矛盾を反映して遅れをとっています。
その翻訳は技術的には正しいものの、Qwen の翻訳のような洗練さと慣用的な流暢さが欠けています。この統計的ギャップは、特に重要なビジネス アプリケーションの場合、LLaMA がポスト編集を Qwen の精度に合わせる必要があることを強調しています。
 推論効率とコンテキストの長さ
推論効率とコンテキストの長さ
モデルを展開する場合、速度とコンテキストの長さが重要になります。LLaMA 3.2 は、より軽量なアーキテクチャのおかげで、ほとんどの推論設定において Qwen 2.5 よりも約 3 倍高速です。これは、実稼働環境やローエンドの GPU で実行する場合に大きな違いを生む可能性があります。
コンテキストの長さに関しては、どちらのモデルも向上しました。LLaMA 3.2 は、Qwen の拡張コンテキスト ウィンドウに一致する、最大 128K のトークンをサポートするようになりました。つまり、長い文書や会話を入力しても、正確な出力が得られるということです。
ハードウェア要件も考慮すべきもう 1 つの要素です。Qwen の大規模モデルはリソースを大量に消費する可能性がありますが、LLaMA はローカル設定でより効率的に実行されます。コストまたは速度が最大の懸念事項である場合は、LLaMA の方が適している可能性があります。
コーディングと開発者のユースケース
開発者にとって、コードのパフォーマンスは非常に重要です。Qwen は、HumanEval やコード生成ベンチマークなどのタスクで LLaMA を上回ります。このため、Qwen は、自動コーディング、開発ツールの統合、バックエンド ロジックなどのアプリケーションに最適な選択肢となります。
カスタマイズは、両方のモデルのもうひとつの強みです。Qwen は特定のドメインに合わせて微調整でき、LLaMA は低レイテンシのタスクに迅速に適応できます。HuggingFace および Transformers ライブラリとの統合はどちらもスムーズです。
私たちの経験では、開発者は高度なワークフローには Qwen を、応答性には LLaMA を好む傾向があります。ツールが複雑なロジックによる推論を必要とする場合、Qwen はより優れた基盤を提供します。しかし、高速実行が必要なタスクの場合、LLaMA を使用すると時間を節約できます。
安全性、整合性、コミュニティの採用
2025年にはAIの安全性と調整が主要なトピックになります。Qwen と LLaMA はどちらも、幻覚を減らし、事実の正確性を向上させるためにアライメントの改善を導入しました。しかし、彼らの戦略は異なります。
LLaMA は、出力をフィルタリングし、リスクのある完了を制限することで、応答の安全性を優先します。一方、Qwen は、関連性を維持するために、より多くのコンテキスト認識とより深い理解に依存します。これにより、精度とニュアンスが求められるタスクでは、Qwen がわずかに優位に立つことになります。
コミュニティのサポートも大きなプラスです。LLaMA には、Meta およびサードパーティの開発者の貢献による大規模なエコシステムがあります。Qwen は、活発な開発者フォーラムと定期的なモデル更新により、HuggingFace などのプラットフォーム上で急速に成長しました。
 MachineTranslation.comやLLMを集約する他の翻訳プラットフォームでは、QwenやLLaMAのようなモデルがSOC 2の基準を完全に満たしていないことが判明しました。データセキュリティとプライバシー。安全でプライバシーに準拠した言語ソリューションを優先する組織にとっては、MachineTranslation.com の信頼できるインフラストラクチャに直接依存する方が安全です。
MachineTranslation.comやLLMを集約する他の翻訳プラットフォームでは、QwenやLLaMAのようなモデルがSOC 2の基準を完全に満たしていないことが判明しました。データセキュリティとプライバシー。安全でプライバシーに準拠した言語ソリューションを優先する組織にとっては、MachineTranslation.com の信頼できるインフラストラクチャに直接依存する方が安全です。
結論
2025 年、Qwen 対 LLaMA の議論はこれまで以上に均衡が取れています。Qwen 2.5 は多言語、技術、コンテキストが豊富なユースケースでリードしており、LLaMA 3.2 は速度と効率に優れています。適切な選択は、コーディング、翻訳、顧客サービス、AI を活用した検索など、ニーズに応じて異なります。
パフォーマンス、推論時間、言語サポート、実際のアプリケーションについて説明し、賢明な決定を下せるよう支援します。多言語プロジェクトを実行している場合は、Qwen と MachineTranslation.com を組み合わせて、非常に正確な翻訳とスケーラブルなローカリゼーションを実現してみてください。どちらを選択しても、両方の LLM は、急速に進化するオープンソース AI の世界で大きな力と柔軟性を提供します。
MachineTranslation.com のパワーを最大限に活用し、Qwen や LLaMA などのトップレベルの LLM や翻訳エンジンにシームレスにアクセスできます。今すぐ購読するよりスマートな AI、より高速なワークフロー、そして言語間で比類のない精度により、翻訳の質を高めます。