June 11, 2026
AI translation in low-resource languages has a problem nobody talks about
A single AI model translated the English phrase "out-of-pocket" (meaning an unexpected cost) into Haitian Creole as "soti-of-pòch." That structure does not exist in the language. It violates Haitian Creole's basic spelling conventions. And the person who received it had absolutely no signal that anything was wrong.
The output looked like a translation. It was formatted like a translation. It arrived with the same confidence as every other output the tool produced. The failure was invisible.
This is not an edge case in low-resource language translation. It is the pattern.
In this article
- What "low-resource" actually means and why it matters
- Why single AI models fail in low-resource languages specifically
- The failure mode nobody talks about: The invisible error
- What platform data shows about where the reliability gap is widest
- How multi-model agreement changes the equation
- Which languages are most affected
- Frequently asked questions
What "low-resource" actually means and why it matters
When people in the translation industry say a language is "low-resource," they mean something specific: there is not much parallel text available to train AI models on. Parallel text is bilingual data — the same content in two languages, aligned so a model can learn the relationship between them. The more of it that exists for a given language pair, the more reliably an AI can learn to translate it.
English-Spanish has an enormous amount of parallel data. Decades of international trade, diplomatic communication, academic publishing, and digital content have produced billions of aligned text pairs. A model trained on that data knows Spanish deeply — not just its vocabulary and grammar, but its idioms, its registers, its domain-specific terminology.
Haitian Creole has a fraction of that. So does Tamazight, spoken by Amazigh communities across North Africa. So does Malagasy, the primary language of Madagascar. So does Twi, spoken by approximately 9 million people in Ghana. For these languages, the training data that AI models depend on is thin — and that thinness shows in the output.
The consequence is not always an obvious error. Sometimes it is. More often it is something subtler: a grammatical structure that a native speaker would never produce, a borrowed English word where a native term exists, a sentence that conveys roughly the right information but would not pass as natural speech. These errors are hard to detect if you do not speak the language, which is precisely the situation most people translating into a low-resource language find themselves in.
Why single AI models fail in low-resource languages specifically
AI translation models learn from data. When there is abundant data, a model learns the full texture of a language — not just its dictionary, but the patterns of how words interact, how sentences are constructed in practice, how meaning shifts across contexts. When data is scarce, that learning is incomplete.
The specific failure modes differ by language, but the underlying cause is the same. A model that has seen a language only in limited domains (religious texts, for instance, or a narrow set of web sources) will generalise from those domains in ways that produce unnatural output elsewhere. A model that has not seen enough morphological variation will struggle with inflected forms. A model that has processed a language primarily in one regional variety will produce output that reads as foreign in another.
The Haitian Creole case is a useful illustration. "Out-of-pocket" is an English idiom. A model that has seen enough Haitian Creole to know that English words occasionally appear in Creole text might produce "soti-of-pòch", a phonetic approximation that looks like it could be real but is not. The error is not random noise. It follows the model's internal logic. It is just wrong.
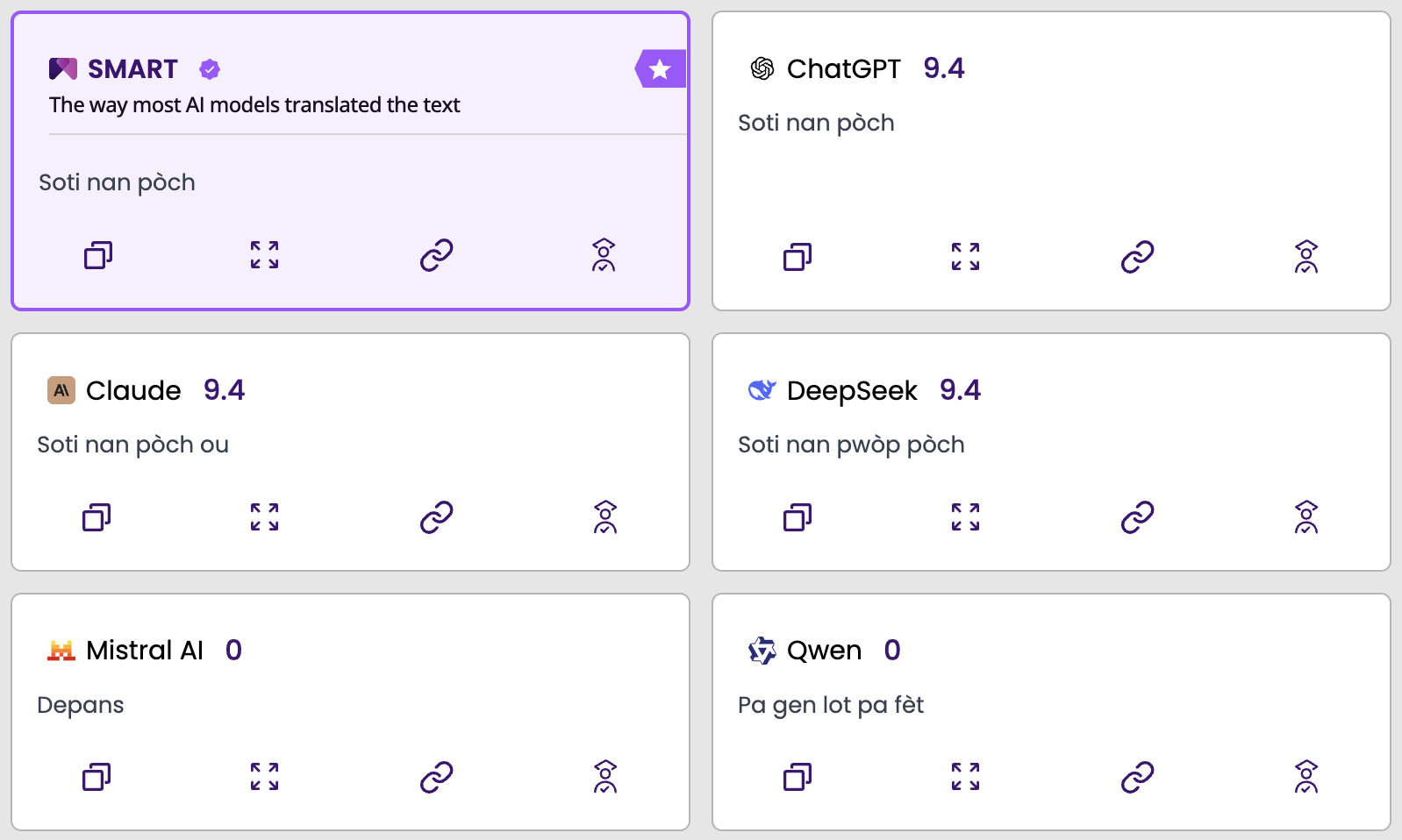
What makes this particularly difficult is that the same failure mode produces a different error in every language and every input. There is no consistent pattern that would allow a user to spot it.
The failure mode nobody talks about: The invisible error
The more commonly discussed failure mode in AI translation is the obvious error — the clearly wrong word, the broken sentence, the output that looks like something went wrong. These errors are detectable. Users notice them. They prompt manual review.
The harder problem is the invisible error: output that looks correct, reads fluently enough, and passes casual inspection — but is wrong in a way that only a speaker of the target language would catch.
As internal tracking at MachineTranslation.com has shown, the errors that remain in modern AI translation are almost entirely semantic: wrong register, wrong cultural framing, a term that sounds plausible but carries a different meaning in practice. In high-resource languages, multiple training examples help models avoid these. In low-resource languages, the training data is too thin to provide that correction.
The person who received the "soti-of-pòch" translation had no way to know it was wrong. They did not speak Haitian Creole. They used a translation tool because they needed to communicate something to someone who did. The tool produced a confident output. They trusted it. And the error passed through.
That is the failure mode that matters most — not the one users catch, but the one they do not.
What platform data shows about where the reliability gap is widest
An internal review of translation requests processed through MachineTranslation.com between January and April 2026 produced a finding that is specific enough to be useful: low-resource language pairs including Haitian Creole, Tamazight, Malagasy, Twi, and Akan showed measurably higher cross-model disagreement rates than high-resource pairs such as English-Spanish and English-French.
Cross-model disagreement is the rate at which different AI models produce different outputs for the same input. In high-resource languages, models tend to converge — they have all seen similar training data and learned similar patterns. In low-resource languages, models diverge more frequently, because each model has learned from a different and incomplete picture of the language.
That divergence is not just a quality indicator. It is a reliability signal. When models disagree, it means that even among the most capable AI systems available, there is genuine uncertainty about the correct output. A single model presenting one answer as definitive is hiding that uncertainty. Multi-model comparison makes it visible.
"Our platform data shows that the gap between single-model output and AI-verified output is widest in exactly the language pairs where users are least able to verify the result themselves," says Rachelle Garcia, AI Lead at Tomedes, the translation company behind MachineTranslation.com. "Higher cross-model disagreement rates in Haitian Creole, Malagasy, and Twi tell us that individual models are genuinely uncertain in these languages — and that the multi-model verification step is doing its most important work exactly where individual models are least reliable."
This finding was covered by Slator, the leading language industry trade publication, in June 2026 — the first time the platform's low-resource language reliability data had been reported externally.
How multi-model agreement changes the equation
The structural problem with single-model translation in low-resource languages is not addressable by improving any one model. Better training data helps. Larger model size helps. But for languages where the data is thin by nature (where no amount of scraping will produce the parallel corpora that English-Spanish has), a single model will always have gaps.
Multi-model agreement approaches this problem from a different direction. Instead of asking "what does model X produce?", it asks "what do models X, Y, Z, and nineteen others produce — and what do they agree on?"
When 20 out of 22 models produce the same output for a Haitian Creole translation, that convergence is a reliability signal that no single model can produce on its own. When the models split significantly, that divergence is a flag: the passage is uncertain, the output should be treated as provisional, and (for anything where an error has real consequences) human review should be considered.
MachineTranslation.com's SMART system runs 22 AI models at once on every translation across all 330+ languages it supports, and delivers the translation the majority agrees on. Internal testing across 10,000 translated segments spanning 10 language pairs, evaluating terminology accuracy, semantic fidelity, and negation handling against human-verified reference outputs, shows this approach reduces translation error risk by 90% compared to single-model baselines.
"The problem with low-resource languages is not just that AI models perform worse — it is that users have no way to detect when they do," says Ofer Tirosh, CEO of Tomedes. "Running 22 independent models and requiring them to agree before producing a result is the closest thing to built-in verification that exists at scale for languages where human experts are hard to find. When the models disagree, the outlier is discarded. When they agree, that agreement is itself a reliability signal."
For users who need an additional layer of certainty (for official documents, humanitarian communications, medical materials, or anything where a wrong translation has real consequences), human verification is available within the same platform, with a 100% accuracy guarantee.
Which languages are most affected
The reliability gap in AI translation is not uniform. It correlates closely with the availability of training data, which correlates with the digital presence and documentation of a language.
Languages most affected by the single-model reliability problem include:
African languages with limited digital presence — Twi, Akan, Malagasy, Tigrinya, Lingala, Wolof, and dozens of others spoken by millions of people but underrepresented in the datasets that AI models train on.
Indigenous and regional languages — Tamazight (spoken across North Africa), Quechua (spoken across South America), Nahuatl, and others that exist primarily in oral traditions or in limited written domains.
Languages where the primary script creates data scarcity — languages written in scripts that were not digitised early or extensively, limiting the parallel text available to models.
Creole languages — including Haitian Creole, Tok Pisin, and others that emerged from contact between multiple language families and do not have direct equivalents in the training data of models primarily trained on their source languages.
This does not mean these languages cannot be translated with AI. It means single-model AI translation of these languages carries a higher baseline risk of invisible errors, and that the gap between single-model output and multi-model consensus output is wider for these pairs than for any others.
Frequently asked questions
1. Why are low-resource languages harder for AI to translate accurately?
AI translation models learn from parallel text data, bilingual content that maps one language to another. Low-resource languages have less of this data available, which means models have learned from a thinner, less representative picture of the language. The result is higher rates of unnatural output, borrowed vocabulary where native terms exist, and incorrect generalisations from the limited domains where data is available.
2. How can I tell if an AI translation into a low-resource language is accurate?
Without speaking the target language, you cannot reliably detect errors in a single-model output. The most practical approach is to use a multi-model system that shows you cross-model agreement rates — high agreement signals greater reliability, significant divergence signals genuine uncertainty. For high-stakes content, human verification by a qualified professional remains the most reliable quality standard.
3. What is a "cross-model disagreement rate" and why does it matter?
Cross-model disagreement rate is the frequency with which different AI models produce different outputs for the same input. In high-resource languages, models converge because they have learned from similar training data. In low-resource languages, models diverge more because each model has an incomplete picture. High disagreement rates indicate genuine uncertainty, content where a human reviewer is particularly valuable.
4. Which low-resource languages does MachineTranslation.com support?
MachineTranslation.com supports 330+ languages across its 22-model SMART system. This includes Haitian Creole, Malagasy, Twi, Akan, Tamazight, and many other languages with limited representation in standard AI training datasets. The multi-model consensus approach applies across all supported languages, the reliability signal is most valuable precisely in the pairs where individual model uncertainty is highest.
5. Is multi-model consensus actually better than a single model for these languages?
Based on internal testing across 10,000 translated segments, the SMART consensus approach reduces translation error risk by 90% compared to single-model baselines. The gap is widest for low-resource language pairs, where individual models show the highest disagreement rates and where users are least equipped to detect errors independently. For the specific failure mode that matters most in these languages (the invisible error that looks correct but is not), cross-model agreement is currently the most practical verification mechanism available at scale.