June 26, 2026
AI translation for minority languages: What Twi, Tamazight, and Inuktitut revealed
The finding came from the data before we ran a single test.
When we looked at MachineTranslation.com's platform data sorted by engagement rather than volume, a pattern emerged that had nothing to do with the language pairs we expected to see near the top. Our highest-traffic pairs are the predictable ones: English-Spanish, German-English, English-French. But our most engaged users (measured by how rarely they leave without translating, how consistently they convert, how long their sessions run) are translating languages that most AI translation companies have never written a single word about.
Three patterns stood out immediately. English to Twi, the Akan language spoken primarily in Ghana. Arabic to Tamazight, the Berber language of North Africa. English to Inuktitut, the indigenous language of Arctic Canada.
These are not peripheral use cases. Together, these language pairs account for more than 60,000 sessions a month on MachineTranslation.com. And the people behind those sessions arrive with a specificity of purpose that shows up in every metric. They know what they need. They are not browsing.
We ran three tests to understand exactly what they find when they arrive, and where the AI falls short.
Table of contents
- The engagement data that made us look twice
- Test 1 — English to Twi: Six models, five different outputs, one consensus
- Test 2 — Arabic to Tamazight: What happens when an AI model returns the source language instead
- Test 3 — English to Inuktitut: Three writing systems and a question no generic translation API would ask
- What all three tests have in common
- What to do if you need to translate a minority language reliably
- Frequently asked questions
The engagement data that made us look twice
Bounce rate is one of the most honest signals a website has. A user who arrives and immediately leaves did not find what they were looking for. A user who stays (who translates, then translates again) found something useful.
Here is what MachineTranslation.com's data shows across the minority language pairs with the highest session volume:
| Language pair | Bounce rate |
|---|---|
| English → Twi | 15.9% |
| Arabic → Tamazight | 13.1% |
| Tamazight → Arabic | 14.8% |
| English → Tamazight | 10.8% |
| Inuktitut → English | 15.5% |
For context: the homepage has a bounce rate of 21.2%. Every minority language pair in this table beats it substantially. The English-to-Tamazight page, with a 10.8% bounce rate, means roughly nine out of ten people who land on it complete a translation.
The explanation is not difficult to find. For speakers of Twi, Tamazight, or Inuktitut, the digital translation landscape is sparse. As research on large language model performance consistently shows, the quality gap between high-resource and low-resource language translation is driven directly by data availability during training — and that gap is wide. When users translating minority languages find a platform that actually works, they stay and they return.
We wanted to understand what "works" looks like at the model level, and where it quietly breaks.
Test 1 — English to Twi: Six models, five different outputs, one consensus
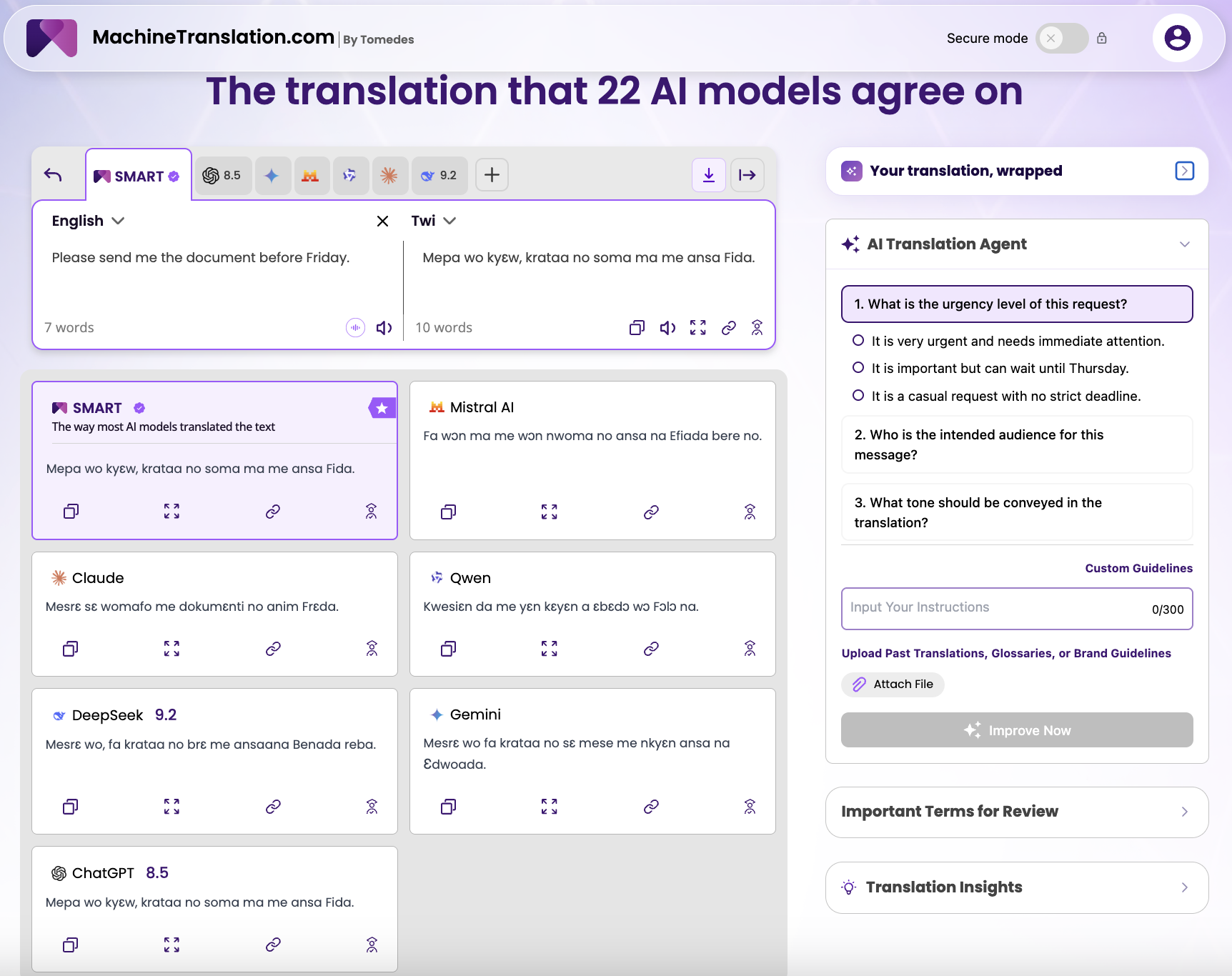
We translated a standard professional phrase ("Please send me the document before Friday.") from English to Twi using MachineTranslation.com, which runs multiple AI models simultaneously and identifies the consensus (most-agreed) output.
| Model | Output |
|---|---|
| ChatGPT (8.5) | Mepa wo kyɛw, krataa no soma ma me ansa Fida. ✅ |
| Mistral AI | Fa wɔn ma me wɔn nwoma no ansa na Efiada bere no. |
| Claude | Mesrɛ sɛ womafo me dokumenti no anim Frɛda. |
| DeepSeek (9.2) | Mesrɛ wo, fa krataa no brɛ me ansaana Benada reba. |
| Qwen | Kwesiɛn da me yɛn kɛyɛn a ɛbɛdɔ wɔ Fɔlɔ na. |
| Gemini | Mesrɛ wo fa krataa no sɛ mese me nkyɛn ansa na Ɛdwoada. |
Six models. Six different translations.
This degree of fragmentation on a seven-word business sentence would be unusual for English, Spanish, or German — where the model pool typically converges quickly. In Twi, it reflects something structurally real: the language has significantly less training data available than high-resource languages, which means each model has learned from a different, smaller slice of the available corpus. The result is not stylistic variation. It is genuine uncertainty at the model level.
On a single-model platform, the output would be whichever of those five divergent translations that model happened to return, with no indication that five other models would have said something different.
One detail in the screenshot is worth pausing on. The AI Translation Agent on the right side of the interface (a feature that analyses the translation and surfaces contextual questions) was asking the user about the urgency of the request, the intended audience, and the tone to convey. These are not generic prompts. Word choice in Twi shifts with formality and register in ways that carry social meaning, and the platform was recognising that those contextual signals shape which translation is correct — not just acceptable.
Test 2 — Arabic to Tamazight: What happens when an AI model returns the source language instead
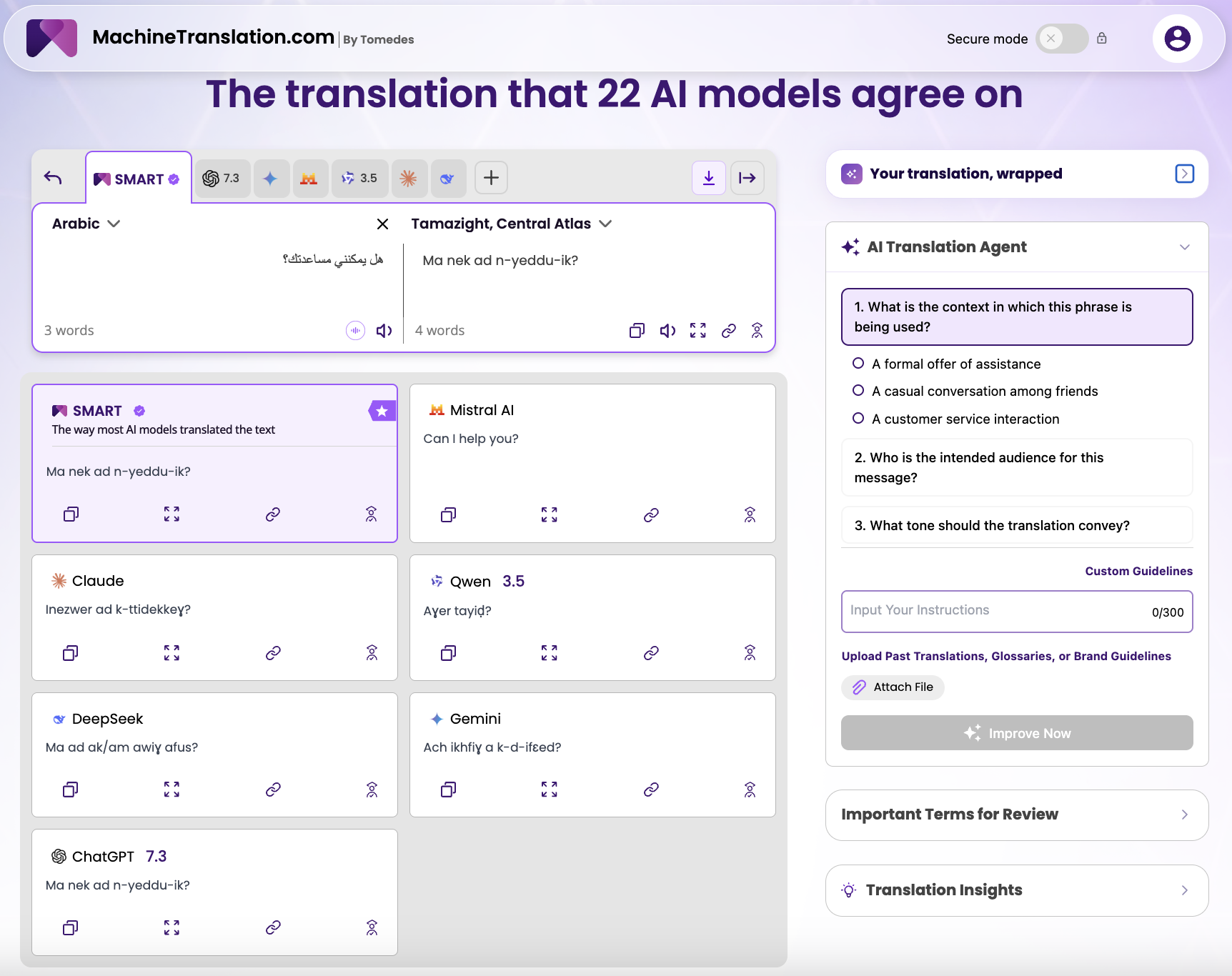
For the second test, we translated the Arabic phrase "هل يمكنني مساعدتك؟" (Can I help you?) into Tamazight, Central Atlas variant.
| Model | Output | Notes |
|---|---|---|
| ChatGPT (7.3) | Ma nek ad n-yeddu-ik? ✅ | |
| Mistral AI | Can I help you? | ❌ Returned English — complete failure |
| Claude | Inezwer ad k-ttidekkey? | |
| DeepSeek | Ma ad ak/am awiy afus? | |
| Qwen (3.5) | Ayer tayiḍ? | |
| Gemini | Ach ikhfiy a k-d-ifɛed? |
Mistral AI returned "Can I help you?" — the English rendering of the Arabic input, not a Tamazight translation.
This is a categorically different failure from the Twi fragmentation. Mistral did not produce a bad Tamazight translation. It produced no Tamazight translation at all. The model appears to have processed the Arabic source and defaulted to English output, either because Tamazight was absent from its effective training distribution or because its language routing logic broke down entirely when asked to bridge Arabic to a Berber target language.
When one model in the pool fails entirely and the remaining five return different outputs, the consensus signal is weaker. The platform still returned a usable result, and the lower score is honest information about how much confidence the model pool actually has.
Tamazight (also called Amazigh) has roughly 30 million speakers across Morocco, Algeria, Libya, and the diaspora, with written forms in three different scripts: Tifinagh, Latin, and Arabic. The language has received limited attention from mainstream AI translation research despite representing one of the larger language communities in North Africa. Coverage of minority languages in AI translation platforms has remained inconsistent, with commercial priorities favouring languages with larger digital training corpora.
The 32,000+ combined monthly sessions across Tamazight language pairs on MachineTranslation.com (and the 10.8% bounce rate on the English-to-Tamazight page, among the lowest on the entire platform) represent a community actively seeking translation resources that are not failing them the way Mistral did in this test.
Test 3 — English to Inuktitut: Three writing systems and a question no generic translation API would ask
The Inuktitut test produced the most structurally layered results of the three.
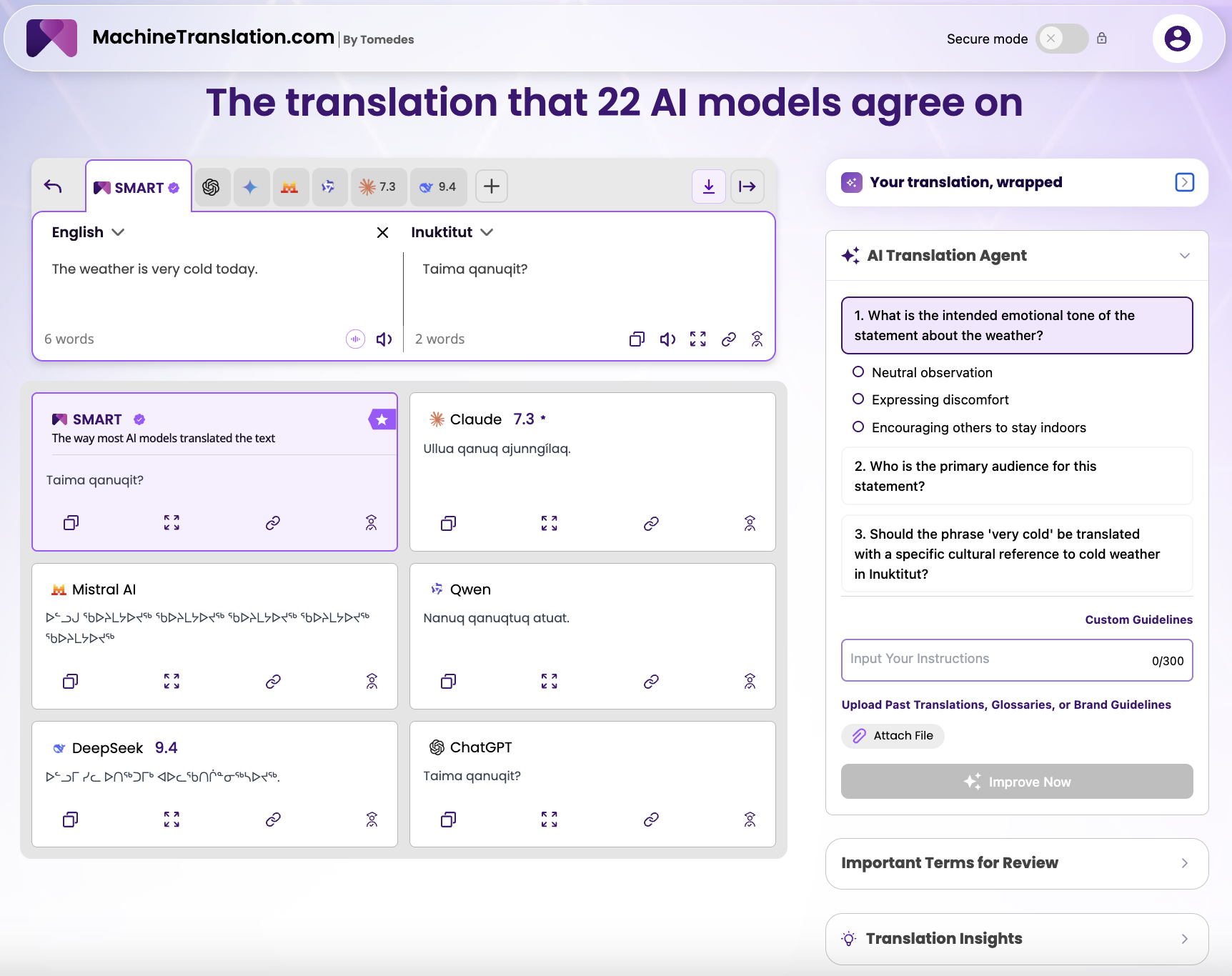
We translated the phrase "The weather is very cold today." from English into Inuktitut.
| Model | Output | Script |
|---|---|---|
| ChatGPT | Taima qanuqit? ✅ | Latin romanisation |
| Claude (7.3) | Ullua qanuq ajunngilaq. | Latin romanisation |
| DeepSeek (9.4) | ᐅᑭᐅᒃ ᓱᓕ ᑕᒪᐃᓐᓂᐊᖅᑐᖅ ᓈᒻᒪᙱᑦᑐᖅ. | Canadian syllabics |
| Mistral AI | ᐅᑭᐅᒃ ᑕᒪᐃᓐᓂᐊᖅᑐᖅ ᑕᒪᐃᓐᓂᐊᖅᑐᖅ ᑕᒪᐃᓐᓂᐊᖅᑐᖅ ᑕᒪᐃᓐᓂᐊᖅᑐᖅ | Canadian syllabics — repetitive |
| Qwen | Nanuq qanuqtuq atuat. | Latin romanisation |
Three things stand out.
First, the models divided between writing systems without being asked to. DeepSeek returned proper Canadian syllabics (ᐅᑭᐅᒃ ᓱᓕ ᑕᒪᐃᓐᓂᐊᖅᑐᖅ ᓈᒻᒪᙱᑦᑐᖅ.) — the script used for formal and community communication in Nunavut. ChatGPT, Claude, and Qwen returned Latin romanisation. This is not a neutral difference. Syllabics are the preferred written form in many Inuit communities, and a model that defaults to Latin romanisation every time is making a choice that does not always align with how the language is actually used.
Second, Mistral's syllabics output appears to repeat the same character block across the output — a pattern associated with hallucination in low-resource language generation, where a model has absorbed partial syllabic patterns without learning the language's actual structure. The output looks like Inuktitut; it is not.
Third (and this is the detail that distinguishes platform depth from raw model output), the AI Translation Agent asked two things that a generic translation API would never surface: the emotional tone the user intended to convey, and whether the phrase "very cold" should be translated with a culturally specific Inuktitut reference to cold weather conditions.
Inuktitut has a rich, semantically detailed vocabulary for cold, snow, ice, and weather states — categories that are culturally and practically central to life in the Arctic in ways that have no structural equivalent in English. The platform was recognising that "very cold" is an underspecified phrase for a language that distinguishes between these conditions with precision. That question (about whether to invoke a cultural reference) is the kind of translation awareness that exists at the intersection of linguistics and cultural knowledge. It does not come from a standard language model. It comes from a platform built to understand that translation is not a word-for-word process.
What all three tests have in common, and what it tells you about low-resource language translation
Each test revealed a distinct failure mode:
- Twi: Fragmentation — six different translations from six models
- Tamazight: Hard failure — one model returned the source language instead of the target
- Inuktitut: Script divergence and hallucination — models disagreed on which writing system to use, one returned garbled output
The underlying cause is the same in all three cases. As Stanford researchers have documented in work on low-resource language AI, the performance of AI translation systems correlates directly with the volume and quality of training data available for each language — and for Twi, Tamazight, and Inuktitut, that data is a fraction of what exists for English, French, or Spanish. Models trained on unequal data produce unequal results. The gap is not a bug. It is a structural consequence of how AI translation systems are built.
What changes the outcome is not using a better single model. It is running the full available model pool and using the consensus result rather than any individual output — precisely because, in low-resource languages, no single model can be trusted to be consistently correct. The SMART results are calibrated signals of how much agreement the model pool actually reached. A lower score on a minority language translation is not a failure; it is the platform being honest about the level of certainty the available AI can provide.
That honesty is what the 60,000+ monthly users of these language pairs are responding to. They are not getting a false 9.8 on a translation that four of six models would disagree with. They are getting the best available consensus output, with a score that tells them how much to trust it.
What to do if you need to translate a minority language reliably
Three practices make a measurable difference for anyone regularly translating low-resource or minority languages:
-
Use a multi-model platform, not a single-model one. The Tamazight test demonstrates why this is not optional: one model in a six-model pool returned the source language rather than the target. On a single-model platform, that output would have been delivered with no indication that anything had gone wrong. A consensus approach catches that failure and routes around it.
-
Use the SMART result as a confidence signal. A score of 7.3 on an Arabic-to-Tamazight translation carries different information from a 7.3 on an English-to-French translation. In a low-resource language, that score reflects genuine model uncertainty — the pool was less cohesive, the output should be treated with correspondingly more care before use in professional, legal, or community contexts.
-
Use human verification for consequential content. MachineTranslation.com's human verification option connects users with professional translators who review and certify AI output. For minority languages, the distance between a technically generated translation and a culturally accurate one can be significant. Human review is not a fallback for when AI fails; it is the final step that makes a high-stakes minority language translation usable with confidence.
The 60,000+ people translating Twi, Tamazight, and Inuktitut on MachineTranslation.com every month are not a curiosity in the platform's data. They are a signal about what AI translation has left behind, and what a platform built around consensus and verification can still provide.
Frequently asked questions
1. Does MachineTranslation.com support Twi translation?
Yes. MachineTranslation.com supports Twi (Akan) and runs it through multiple AI models simultaneously to produce a consensus output. The English-to-Twi language has a bounce rate of 15.9% (below the platform's homepage bounce rate) indicating that the large majority of users arrive, translate, and find what they were looking for.
2. What is the best AI translator for Tamazight?
Tamazight is a low-resource language where AI model performance varies significantly, including cases where a model returns the source language rather than a Tamazight output at all. A platform that runs multiple models simultaneously and identifies the consensus output (rather than trusting any single model) provides the most reliable Tamazight translation currently available from AI. MachineTranslation.com's Arabic-to-Tamazight and English-to-Tamazight pairs collectively receive more than 32,000 sessions monthly, with bounce rates between 10.8% and 14.8%.
3. Can AI translate Inuktitut accurately?
AI can produce Inuktitut translations, but the results vary meaningfully across models — including disagreement about whether to use Canadian syllabics or Latin romanisation, and at least one model returning garbled syllabic output in testing. MachineTranslation.com's SMART mechanism runs the available Inuktitut-capable models and returns a consensus output with a score that reflects actual model agreement. For formal or community-facing Inuktitut content, human verification of the AI output is strongly recommended.
4. Why do minority language translation pages have lower bounce rates than major language pages?
Users translating Twi, Tamazight, Inuktitut, and other underserved languages have fewer reliable AI translation options than users translating English or French. When they find a platform that handles their language (with real multi-model support rather than nominal coverage) they translate, they convert, and they return. The engagement data reflects the scarcity of working alternatives, not just platform quality in isolation.
5. Is it safe to use AI translation for official or legal minority language documents?
AI translation alone (even from a multi-model consensus platform) is not recommended for legal, official, or certified documents in any language, and the risk is higher for low-resource languages where model training data is limited. MachineTranslation.com's human verification option provides professional translator review of AI output, and is the appropriate step before using any AI-generated minority language translation in a consequential context.

By Rachelle Garcia
Connect on LinkedInRachelle leads product and AI at Tomedes, where she runs the experiments that turn internal data into better translation experiences. She writes about what actually happens when you build AI products such as MachineTranslation.com — the numbers, the surprises, and the parts that don't go to plan.
Share: