March 26, 2026
Can AI translate Latin? What classicists need to know in 2026
For anyone working with Latin texts professionally (classicists, historians, theologians, archaeologists, researchers reading scientific correspondence from the 17th century), the question of what AI translation can actually do has become genuinely pressing. Not because AI has replaced the humanist's judgment, but because the tools have improved enough that the question is no longer dismissible.
The answer is neither a confident yes nor a reflexive no. It is a set of distinctions that matter enormously for research practice: distinctions between Latin text types, between use cases, between what a single model will do silently wrong versus what a consensus system will surface for your review. Getting these distinctions right is the difference between AI as a productive research accelerator and AI as a source of quiet errors that corrupt your argument before you notice.
Table of contents
The honest answer is more interesting than yes or no
Why Latin is a structurally different problem for AI than modern languages
What current AI models actually do well with Latin
Where single-model AI consistently fails on classical texts
Why consensus matters more for Latin than for any modern language
A practical framework: matching the tool to the task
When to involve a human Latinist
FAQs
The honest answer is more interesting than yes or no
A 2024 study published in Euleriana benchmarked AI translation on scientific Latin texts from the works of Euler and his contemporaries, comparing Google Translate and ChatGPT. ChatGPT outperformed Google Translate on both benchmark tests and in translating an 18th-century letter from Johann Bernoulli to Euler – a finding that holds up in broader testing: large language models trained on extensive classical scholarship handle standard Classical Latin prose meaningfully better than earlier neural machine translation systems did.
That is the good news. The less comfortable news is that "better than NMT" and "reliable for research" are not the same threshold, and the gap between them depends heavily on what kind of Latin you are working with, what you plan to do with the output, and whether you have a mechanism for knowing where the model made a confident guess that was nonetheless wrong.
The shift that matters most for classicists in 2026 is not that AI has gotten better at Latin in isolation. It is that consensus architectures (systems that run a text through multiple independent AI models simultaneously and surfaces where those models agree) have changed the epistemics of AI translation in ways that are directly relevant to scholarly use. When 22 independent models converge on a single rendering of a Latin phrase, that convergence is a stronger evidential basis than the output of any one of them alone. When they diverge, the divergence flags exactly the terms that require a scholar's judgment. This is a research-compatible workflow in a way that a single confident output simply is not.
Why Latin is a structurally different problem for AI than modern languages
The training data gap
AI translation systems learn from parallel corpora – large collections of texts that exist in both the source language and the target language, aligned sentence by sentence. For high-resource languages like French, Spanish, or German, these corpora contain billions of words. For Latin, the situation is fundamentally different.
While Latin remains a cornerstone of religious and academic studies, its scarcity of annotated datasets and linguistic ambiguities complicate NLP tasks such as translation, semantic parsing, and automated analysis of ancient texts. The extant Latin corpus (everything from Plautus through the medieval period) is finite, and the proportion of that corpus that has been translated into modern languages and digitized in machine-readable form represents a far smaller training signal than any modern European language provides. Due to a lack of training data for low-resource languages, most LLMs cannot properly translate such languages, and fine tuning without sufficient language resources remains a fundamental challenge.
The practical consequence is that AI models working on Latin are, to a meaningful degree, reasoning from pattern-matching on a relatively thin corpus rather than from the deep statistical grounding they have in French or German. For standard classical prose (Caesar, Cicero, Livy), the training signal is adequate because these texts are widely digitized and frequently translated. For technical Latin, post-classical Latin, medieval Latin, or manuscripts in non-standard orthography, the model is increasingly working at the edge of its training distribution.
Morphological complexity and free word order
Latin is a heavily inflected language with six cases, multiple declensions, and a free word order in which meaning is carried by morphology rather than position. A noun at the end of a sentence governs the verb at the beginning; an adjective agrees in case, number, and gender with the noun it modifies across any distance. These features mean that parsing Latin correctly requires holding the entire sentence structure in working memory before any semantic assignment is possible.
Translating Latin scientific texts presents specific difficulties including specialized technical terminology, language evolution over time, abbreviations and symbols, complex sentence structure, cultural context, lack of contextual information, and the need for translator expertise. For AI systems optimized on subject-verb-object languages, long-distance dependencies in Latin syntax remain a persistent source of error – particularly in complex subordinate clause structures, indirect speech (oratio obliqua), and ablative absolute constructions where English has no direct grammatical equivalent.
The paraphrase problem, when accuracy becomes infidelity
This is the failure mode that matters most for scholarly use, and it is the one that is hardest to detect without knowing the source text. When a modern AI model encounters a Latin construction it cannot parse reliably, it does not fail noisily. It produces a fluent English paraphrase – a sentence that conveys something in the vicinity of the original meaning, reads smoothly, and contains no obvious error signal. In theology, precision matters even at the letter-by-letter level (the difference between homo-ousios and homoi-ousios) and the question is not whether AI is good, but whether it is good enough for tasks of such importance.
For a classicist reading a paraphrase of Caesar, the smoothed-over ambiguity of an ablative absolute might be undetectable. For a theologian working on patristic texts, a model that renders substantia and essentia interchangeably has made a philosophical decision it has no authority to make. The paraphrase problem is not a failure of fluency; it is a failure of fidelity that looks like fluency.
What current AI models actually do well with Latin
Within the Latin corpus, there are content types where modern AI performs well enough to be a genuine research tool rather than a liability:
Standard Classical prose from high-frequency authors. Caesar's Bellum Gallicum, Cicero's speeches and letters, Livy's narrative history, Virgil's Aeneid – these texts are so well-represented in training data, and so frequently parallel-translated, that model outputs for straightforward passages are often excellent first drafts. For researchers reading across large volumes of such material to identify passages for closer study, AI provides genuine efficiency without significant epistemic risk, provided the researcher can identify passages needing closer review.
Formulaic legal and administrative Latin. Roman legal formulae, administrative documents, and inscriptions with standardized phraseology are handled reasonably well because their vocabulary and structure are consistent. A researcher processing large volumes of Roman legal papyri or Imperial inscriptions for a database project can use AI translation to generate first-pass renderings and focus human attention on anomalies.
Identifying passage content and keywords before close reading. Even where the translation itself may be imperfect, AI is reliable enough for research triage — quickly establishing what a passage is about, which technical terms appear, whether a specific concept is present — before a trained reader applies close attention. This is a legitimate and underused research application.
Where single-model AI consistently fails on classical texts
Technical and scientific Latin. Mathematical, medical, botanical, and scientific terminology in Latin (from Pliny's Naturalis Historia through 17th-century scientific correspondence) draws on vocabulary that is underrepresented in training corpora and that individual models frequently resolve by borrowing from modern scientific register in ways that distort the original meaning. A persistent challenge lies in reliably translating highly specific or rare terminology found in certain historical or technical texts, an area where automated systems can still falter and human linguistic expertise remains critical.
Philosophical and theological terminology. Terms like virtus, pietas, animus, spiritus, logos, fides carry philosophical and theological weight that cannot be resolved by statistical pattern-matching on their most frequent translations. A model that renders virtus as "virtue" in every instance has flattened a concept that Roman authors used with considerable semantic range – virtus as martial excellence, civic virtue, moral goodness, and specifically masculine courage are distinct in context even if statistically proximate in training data.
Verse and rhetorical prose. Latin poetry imposes constraints (meter, alliteration, word position as a semantic signal) that AI models do not track. When Virgil places a word at line-end or line-beginning, that position is meaningful; a model that reorders the translation for English fluency has lost information the poet encoded deliberately. Similarly, the periodic sentence structure of Ciceronian oratory, where meaning is suspended across long subordinate chains and resolved in the final clause, is frequently compressed or restructured by single-model translation in ways that eliminate the rhetorical effect.
Medieval and Neo-Latin. These periods produced vast bodies of Latin that deviate significantly from Classical norms in vocabulary, syntax, and orthography. Medieval Latin absorbed vernacular influence; Renaissance and early modern scientific Latin invented terminology on the fly. Both are underrepresented in training data relative to Classical Latin, and models frequently default to Classical renderings for post-Classical vocabulary, producing anachronistic translations.
Why consensus matters more for Latin than for any modern language
The core problem with single-model AI translation of Latin is not that any given model performs badly. It is that no single model knows when it is guessing – and in a language where paraphrase masquerades as translation, confident wrongness is the most dangerous failure mode.
This is precisely where MachineTranslation.com's SMART system changes the research workflow. Rather than returning one model's rendering, SMART runs the Latin text through 22 AI models simultaneously (including ChatGPT, Claude, Gemini, DeepL, and 18 others) and returns the translation the majority agreed on. Critically for Latin, it also shows the researcher exactly where the models diverged, and what the alternative renderings were.
For a classicist, this divergence data is scholarly information. When 22 models split 60/40 between two renderings of virtus in a specific passage, that split is telling you something about the genuine ambiguity of the term in context. It is flagging that this is a term requiring your judgment, not a term that can be safely automated. When 22 models converge completely on a rendering of a straightforward ablative of means, that convergence gives you confidence to proceed without close review.
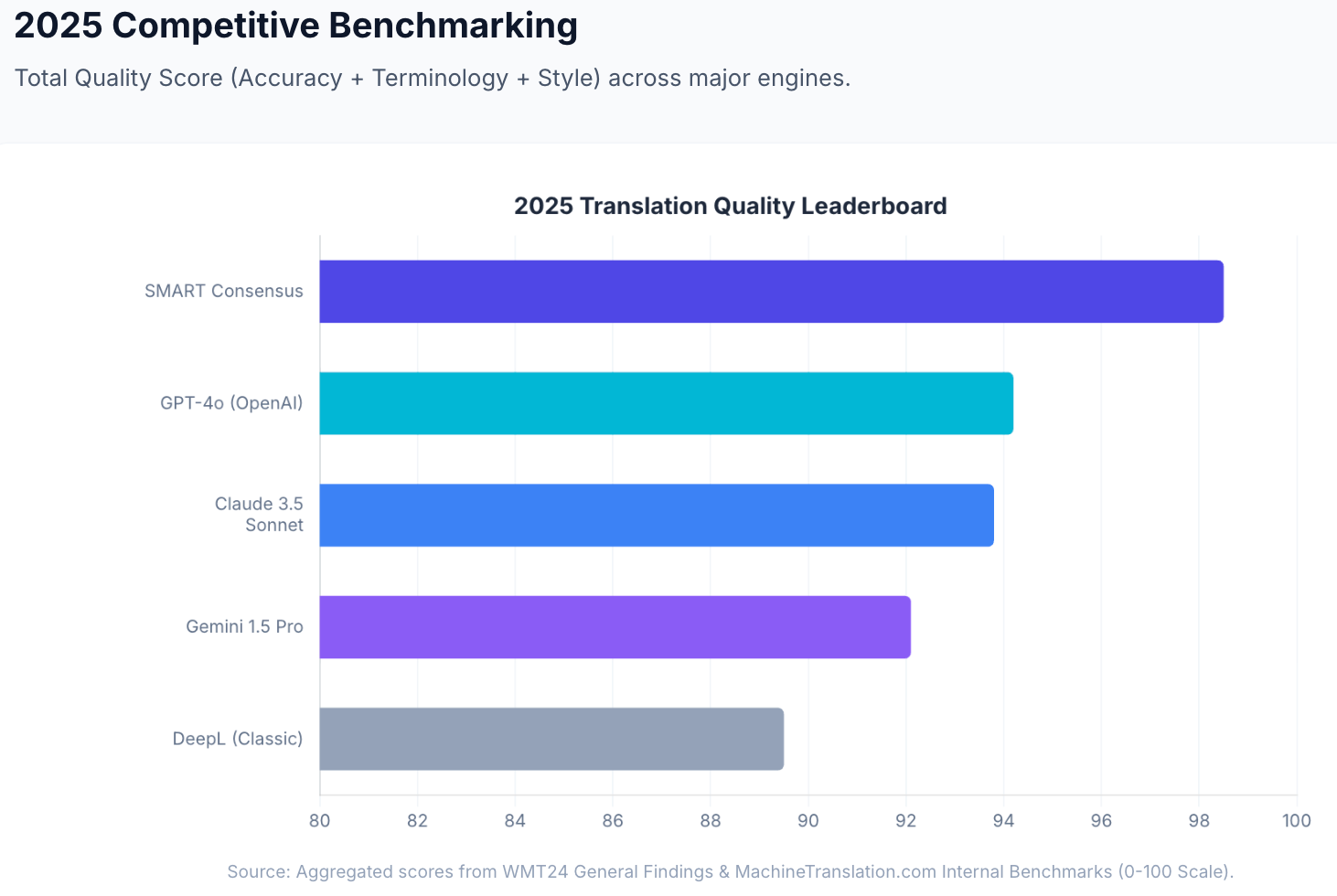
According to internal MachineTranslation.com benchmarks alongside WMT24 General Machine Translation findings, consensus systems achieve an aggregated quality score of 98.5, compared to 94.2 for GPT-4o and 93.8 for Claude 3.5 Sonnet operating individually. The consensus architecture filters out the stylistic and terminological errors native to individual engines, which for Latin specifically means filtering out the paraphrase tendencies and terminology smoothing that each individual model applies differently.
The convergence framing maps directly to how rigorous research already works. Inter-rater reliability (the degree to which independent reviewers agree on an interpretation) is a standard quality metric in humanities research. Twenty-two independent AI models converging on a rendering is a computationally implemented version of inter-rater reliability. Where they agree, you have a signal. Where they disagree, you have a question.
A practical framework: matching the tool to the task
Latin text type | AI reliability | Recommended workflow |
Standard Classical prose (Caesar, Cicero, Livy) | High for common passages | SMART as first draft; human review for key argument passages |
Philosophical & theological texts (Plato in Latin, Aquinas, Augustine) | Medium – terminology-sensitive | SMART; Key Term panel review for all core philosophical terms |
Technical & scientific Latin (Pliny, Euler's correspondence) | Low to medium | SMART; human Latinist review required for technical vocabulary |
Latin verse (Virgil, Ovid, Horace) | Low for verse form | AI for content triage only; translation requires human Latinist |
Medieval Latin | Low to medium | SMART as orientation draft; expert review for all critical passages |
Neo-Latin / early modern scientific | Low | AI for keyword identification only; full human translation recommended |
Formulaic legal / administrative Latin | High for standard formulae | SMART reliable; spot-check non-standard passages |
Ecclesiastical and liturgical Latin | Medium | SMART; community-specific terminology requires expert review |
When to involve a human Latinist
The threshold for human involvement is not a quality question, it is a stakes question. For research triage, literature surveys, and initial content identification across large corpora, AI consensus translation is a legitimate and efficient tool. For passages that will be cited in argument, published as translations, used in theological or liturgical contexts, or where a specific term's interpretation is the substance of the scholarly claim – human expertise is necessary.
MachineTranslation.com's human verification service is ISO 18587:2017 certified and available within the same platform without requiring a separate agency engagement. The SMART consensus translation runs first; human verification is an escalation within the same workflow – a professional reviewer focuses attention on the terms the consensus process flagged as low-agreement, rather than re-translating the entire document from scratch. For a researcher working through a large corpus of Latin texts with a small number of key passages requiring precise scholarly translation, this is a materially more efficient workflow than either AI-only or human-only translation.
FAQs
1. Can ChatGPT translate Latin accurately?
ChatGPT handles standard Classical Latin prose from high-frequency authors with reasonable reliability for research orientation and content triage. Comparative benchmarking found that ChatGPT outperformed Google Translate on scientific Latin texts, and this advantage holds for most Classical prose. The limitations appear in technical vocabulary, verse, philosophical terminology, and post-Classical Latin, where training data is thinner and the paraphrase problem becomes more significant. For scholarly citation or publication, AI output should always be reviewed by a human Latinist.
2. Is Latin a low-resource language for AI purposes?
Yes, in the technical sense. Ancient languages such as Latin and Ancient Greek hold immense historical and cultural significance but pose unique computational challenges, including limited and fragmented corpora and non-standardized formats in many ancient texts. While Latin is better resourced than most low-resource languages (centuries of translated scholarship provide training material), it is substantially less resourced than modern European languages, and this gap shows in AI performance on less-canonical texts.
3. What Latin texts does AI handle best?
The reliably high-performing category is canonical Classical prose: Caesar, Cicero, Livy, Tacitus, Suetonius. These texts are extensively digitized, frequently translated, and well-represented in training data. Formulaic legal and administrative Latin also performs well due to terminological consistency. Performance drops significantly for verse, philosophical texts with community-specific terminology, technical and scientific Latin, and anything from the medieval or early modern periods.
4. How does consensus AI translation help with Latin specifically?
Single-model AI translation of Latin fails silently – paraphrase looks like translation, and confident wrong renderings contain no error signal a non-specialist can detect. SMART in MachineTranslation.com shows where 22 independent models agree, which flags the precise terms and constructions requiring scholarly judgment. For Latin specifically, this divergence data corresponds closely to the passages where genuine philological debate exists: ambiguous terms, contested syntactic structures, culturally loaded vocabulary. The consensus output is more reliable, and the disagreement data is itself scholarly information.
5. When should a classicist use human translation rather than AI?
For any passage being cited in argument, published as a translation, or where the interpretation of a specific term is the substance of the scholarly claim. Also for Latin verse, where formal features encode meaning that AI does not track, and for community-specific theological and philosophical terminology where the stakes of mistranslation are reputational and scholarly rather than merely linguistic. For large-corpus triage, content identification, and generating working drafts that a scholar will then review, AI consensus translation is a legitimate and efficient research tool.
6. Does MachineTranslation.com support Latin?
Yes. MachineTranslation.com supports Latin as a source and target language, running it through 22 AI models. The Key Term Translations panel is particularly useful for Latin research – it shows every significant term with the percentage of models that agreed on each rendering, flagging low-consensus terms for scholarly review. For texts being prepared for publication or citation, the platform's human verification service connects the SMART output to a professional reviewer within the same workflow.