May 8, 2026
ChatGPT o1 for translation: What reasoning models actually add (and what replaced them)
When OpenAI launched o1 in September 2024, it introduced something genuinely new. Unlike GPT-4o, which generates responses fluidly and immediately, o1 pauses to think — running an internal chain-of-thought reasoning process before producing output. OpenAI described it not as a replacement for GPT-4o but as a complement: a different kind of model for a different kind of problem.
For most people evaluating AI tools for translation, the natural question was: does thinking longer actually produce better translations? The answer is nuanced — and understanding it requires understanding what reasoning models are actually doing, and which translation problems benefit from it.
This article covers what o1 brought to translation, how the reasoning model family evolved through o3 and beyond, and what the current state of reasoning-model translation looks like in 2026.
In this article
- What is a reasoning model, and how is it different from standard LLMs?
- What does chain-of-thought reasoning add to translation?
- How does o1 compare to GPT-4o on translation?
- What replaced o1, and how does o3 improve things?
- Where do reasoning models fall short for translation?
- Does reasoning change anything when using a multi-model system?
- Frequently asked questions
What is a reasoning model, and how is it different from standard LLMs?
The short answer: Reasoning models spend computation time thinking through a problem step by step before generating a final answer. Standard LLMs generate the next token immediately based on learned probability distributions.
Standard language models like GPT-4o or Claude are trained to produce fluent, contextually appropriate text as quickly as possible. They are excellent at recognising patterns, following instructions, and generating natural output — but they do not verify their own reasoning before committing to an answer.
Reasoning models like o1 and its successors introduce a different approach: reinforcement learning trains the model to generate an internal chain of thought (a sequence of reasoning steps) before producing a final output. The model can revise its intermediate conclusions, consider alternative interpretations, and catch errors in its own logic before the answer appears.
Intento's 2025 taxonomy of the AI translation landscape explicitly identifies reasoning LLMs as a distinct category: "large models optimised and often prompt-engineered for multi-step, chain-of-thought reasoning, logical inference, and contextual understanding." OpenAI positions the o-series as the leading edge of this category. Source: Intento State of Translation Automation 2025.
The practical trade-off: more deliberation means higher latency and higher cost. o1 at launch was several times more expensive per token than GPT-4o, and noticeably slower. The value proposition rests entirely on whether the quality improvement justifies both.
What does chain-of-thought reasoning add to translation?
The short answer: It adds the most where the translation problem is genuinely ambiguous — where meaning depends on context, intent, or cultural knowledge that a single-pass model might not navigate correctly.
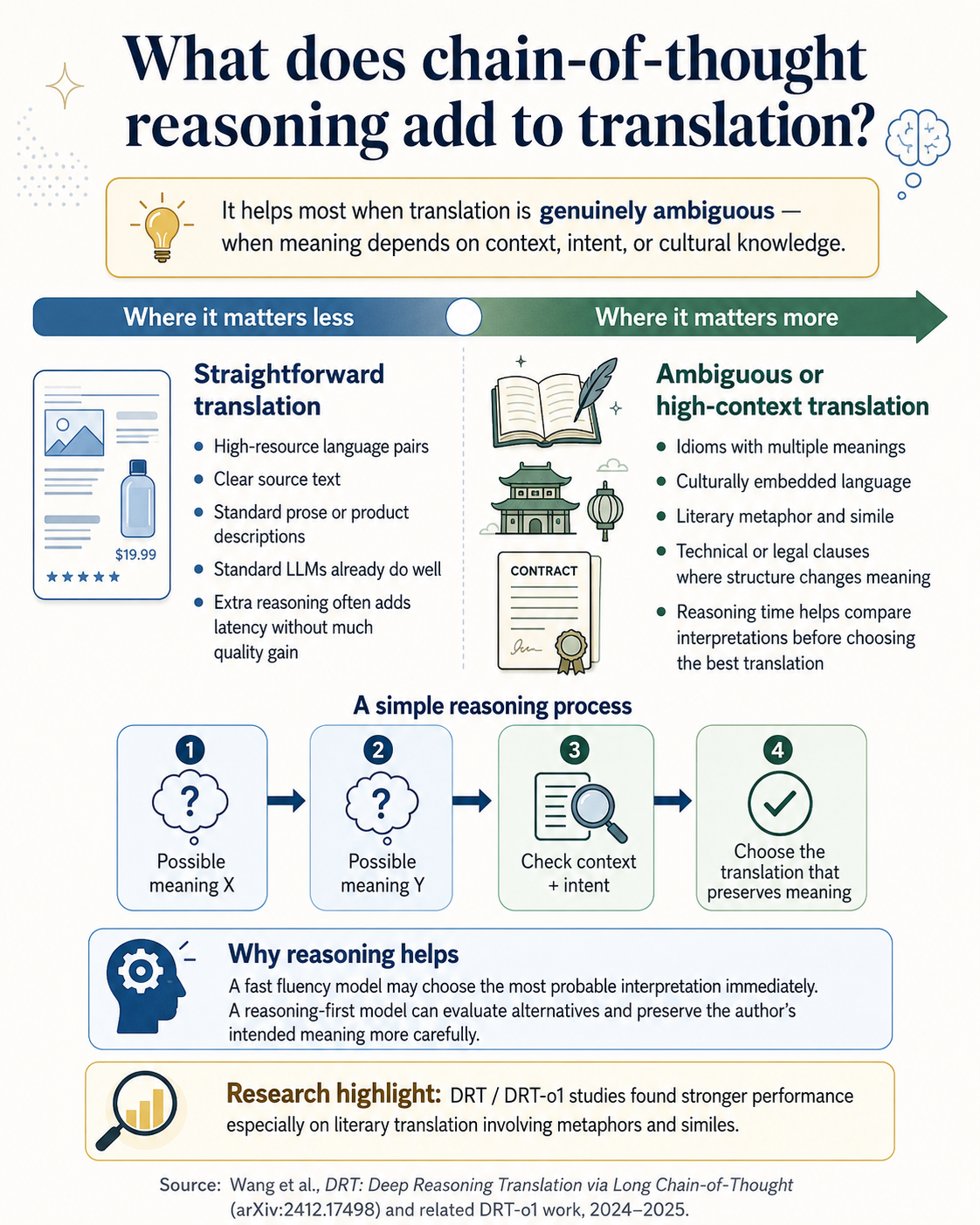
Translation is not uniformly difficult. Translating a product description from English to Spanish is a different cognitive task from translating a Japanese literary passage with embedded cultural references, or a legal contract where a subtle clause relationship changes the meaning of an obligation.
For the easy end of the spectrum (high-resource language pairs, clear source text, standard prose), standard LLMs already perform at a high level. The reasoning overhead of o1 or o3 adds latency without a meaningful quality gain on content that a well-trained fluency model handles correctly on the first pass.
For the harder end (ambiguous idiomatic expressions, culturally embedded language, literary metaphor, technical clauses where the structural relationship between sentences carries the meaning), the thinking time matters. A chain-of-thought model can reason: "The source phrase has two plausible interpretations. The surrounding context suggests the author means X rather than Y. The standard translation of this phrase in this domain is Z, but that does not preserve the intended meaning here. Therefore..." A fluency model moving at speed may simply commit to the most probable interpretation without working through the alternatives.
Research on o1-class models for translation has found exactly this pattern. The DRT-o1 study, published in early 2025, found that long chain-of-thought approaches showed "superior translation capabilities, especially with literature texts involving metaphors and similes" — the translation types where a reasoning-first approach most plausibly differs from a fluency-first one. Source: DRT-o1: Optimised Deep Reasoning Translation with o1 AI (arxiv.org, 2025).
How does o1 compare to GPT-4o on translation?
The short answer: o1 generally produces more nuanced output, particularly for idiom-heavy and culturally complex content. GPT-4o can be stronger on domain-specific terminology across many languages.
Slator tested both models informally in early 2025. Their findings: o1 generally outperformed GPT-4 on rendering natural translations and handling idioms. GPT-4o showed better handling of domain-specific terms, slang, and acronyms across multiple languages — areas where o1 was less consistent. For a scientific paper translated from English into French, German, and Spanish, GPT-4o showed good terminology handling but produced "style-poor, nuance-lacking literal translations." Neither model was clearly dominant for all translation tasks. Source: Slator, January 2025.
The pattern reflects the structural difference between the models. o1's chain-of-thought makes it more careful about meaning, it is less likely to take the most obvious token-level path. But "careful about meaning" and "strong on domain terminology" are different things. A model that has seen enormous amounts of domain-specific bilingual data may outperform one that reasons more carefully but lacks the terminological coverage.
The broader implication: for translation evaluation, the question is never just "which model is smarter?" It is always "which model is better for this specific content type, language pair, and use case?" Reasoning depth helps with ambiguous, literary, and culturally embedded content. Training data depth helps with domain terminology and high-resource pair fluency. No single model optimises for both equally.
What replaced o1, and how does o3 improve things?
The short answer: o3 (released April 2025) superseded o1 across the board, making 20% fewer major errors on real-world tasks. o3-pro replaced o1-pro. The current OpenAI reasoning model lineup is o3, o3-pro, and o4-mini.
The o-series evolution:
- o1 (September 2024) — first generation reasoning model, the proof of concept that chain-of-thought training could improve real-world task performance
- o1-preview / o1-mini — deprecated from the API April 28, 2025; replaced by o3-mini and o4-mini
- o3 (April 16, 2025) — successor to o1, with "20 percent fewer major errors than OpenAI o1 on difficult, real-world tasks." o3 also added visual reasoning capabilities and tool access. OpenAI's own evaluation: o3 excels in "programming, business/consulting, and creative ideation." Source: OpenAI o3 announcement.
- o3-pro (June 10, 2025) — replaced o1-pro; designed for the highest-stakes tasks where extended thinking time is worth the wait
- o4-mini (April 2025) — cost-efficient reasoning model; replaced o3-mini
- GPT-5 (August 2025) — unified model combining reasoning and fluency in a single system with an automatic router; incorporates and extends the o-series capabilities
For translation specifically, Intento's State of Translation Automation 2025 (evaluating 46 MT engines and LLMs across 11 language pairs) includes both OpenAI o3 and o4-mini in the 14 solutions showing best results across all language pairs. Neither o1 nor GPT-4o appear in this top group. The implication: if you are using an OpenAI reasoning model for translation today, o3 or o4-mini are the relevant reference points, not o1.
Where do reasoning models fall short for translation?
The short answer: They are slower and more expensive, and for most professional translation workflows the quality difference over strong standard LLMs is marginal for high-resource, clear-source-text tasks.
Latency. Chain-of-thought reasoning takes time. o1 at launch was noticeably slower than GPT-4o; o3 improved on this but reasoning models remain slower than fluency models for equivalent outputs. For real-time translation, live subtitling, or high-volume batch processing where throughput matters, the latency cost is real.
Cost. Reasoning models price higher per token than their standard equivalents. For translation use cases where volume is high and content is straightforward, the cost-quality trade-off rarely favours reasoning models over well-tuned standard LLMs.
The error evolution problem. MachineTranslation.com's internal analysis of translation errors from 2020 to 2026 documents a shift that reasoning models do not fully solve: in 2020, the majority of errors were syntactic — word order, verb conjugation, surface-level mistakes. By 2026, surface errors have dropped to near zero across all major LLMs. The remaining errors are almost exclusively semantic — contextual, terminological, meaning-level. Reasoning models reduce semantic errors on complex content. But they still produce semantic errors; they simply produce fewer of them than standard models. Source: MachineTranslation.com internal analysis, 2026.
The single-model ceiling. Even with extended reasoning, o3 remains one model producing one output with one perspective on the source text. When it misinterprets an ambiguous phrase (which all models do, at some rate), there is no mechanism to catch it. The chain of thought is internal and not exposed to the user in most interfaces. You see the conclusion, not the reasoning that led to it.
Does reasoning change anything when using a multi-model system?
The short answer: Yes — reasoning models contribute differently to a consensus than fluency models, and when they diverge, that divergence is itself informative.
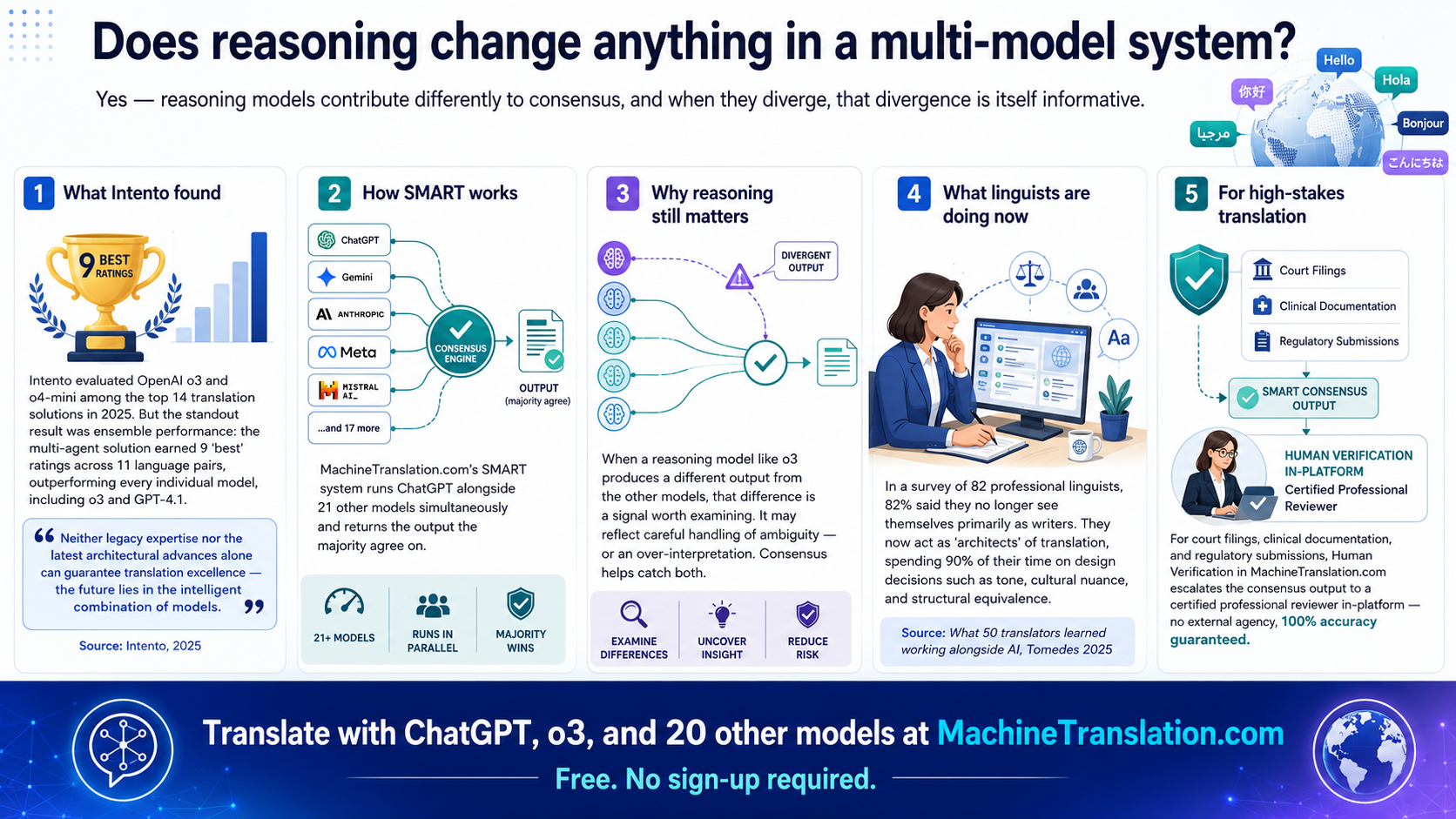
OpenAI o3 and o4-mini are both evaluated in Intento's top 14 solutions for translation in 2025, but the most striking finding in the same study is about ensemble approaches. The multi-agent solution achieved 9 "best" ratings out of 11 language pairs, outperforming every individual model including o3 and GPT-4.1. Intento's conclusion: "neither legacy expertise nor the latest architectural advances alone can guarantee translation excellence, the future lies in the intelligent combination of models."
This maps directly to MachineTranslation.com's SMART system, which runs ChatGPT (OpenAI's current model) alongside 21 other models simultaneously, returning the output the majority agree on. The role reasoning model outputs play in that consensus is specific: when a reasoning model like o3 produces a different output from the 20 other models in the system, that divergence is a signal worth examining. Reasoning models are more likely to have worked through an ambiguous phrase carefully, but they are also more likely to have over-interpreted it. The consensus can catch both.
The language profession's own relationship with AI reasoning models reflects this nuance. In a survey of 82 professional linguists, 82% said they no longer view themselves primarily as writers — they now identify as "architects" of translation, spending 90% of their time on design decisions (tone, cultural nuance, structural equivalence) rather than the surface-level construction that AI handles reliably. When a reasoning model's output differs from the consensus, that is precisely the kind of architectural decision a professional reviewer's attention belongs on. Source: What 50 translators learned working alongside AI, Tomedes 2025.
For high-stakes translation requiring absolute confidence (court filings, clinical documentation, regulatory submissions), Human Verification within MachineTranslation.com escalates the consensus output to a certified professional reviewer in-platform: no external agency, 100% accuracy guaranteed.
Translate with ChatGPT, o3, and 20 other models at MachineTranslation.com — free, no sign-up required.
Frequently asked questions
1. Is ChatGPT o1 good for translation?
o1 is better than standard GPT-4o for translation tasks involving ambiguous phrasing, cultural nuance, and literary or metaphorical content, where chain-of-thought reasoning produces more considered interpretations. For high-resource, clear-source-text translation, the improvement over GPT-4o is marginal. o1 has since been superseded by o3, which makes 20% fewer major errors on real-world tasks.
2. What is the difference between o1 and o3 for translation?
o3 is the direct successor to o1, released April 2025. It makes 20% fewer major errors than o1 on difficult real-world tasks according to OpenAI's own evaluation. o3 also adds visual reasoning and tool access that o1 lacked. For translation purposes, o3 appears in Intento's 2025 top-14 evaluation solutions while o1 does not, suggesting meaningful quality improvements in the generation between them.
3. Is o1 still available?
The full o1 model remains accessible via OpenAI's API as of May 2026. o1-preview and o1-mini were deprecated from the API on April 28, 2025. o1-pro was replaced by o3-pro in June 2025. For new translation workflows, o3 or o4-mini are the currently recommended o-series models.
4. Do reasoning models make better translators than standard LLMs?
For specific translation tasks (ambiguous idioms, literary metaphor, culturally embedded language, complex clause structures), reasoning models produce more considered output. For standard professional translation of clear source text in high-resource language pairs, strong standard LLMs like GPT-4.1 or Claude Opus 4 perform comparably or better on fluency, while being faster and cheaper. The right model depends on content type, not on which generation is newest.
5. Why did OpenAI build reasoning models?
Reasoning models use reinforcement learning to train the model to generate an internal chain of thought before answering. The goal is to improve performance on multi-step, logically complex tasks (mathematics, coding, scientific reasoning) where a single-pass fluency model may commit to the most likely next token rather than working through the problem. OpenAI describes o1 as the first in a series of such models, with o3 and GPT-5 building on the same approach.
6. How does chain-of-thought reasoning help with translation specifically?
Translation involves choosing between multiple plausible interpretations of a source text. For clear, unambiguous content, this choice is straightforward. For idiomatic expressions, culturally specific references, metaphors, and texts where syntax and clause structure carry meaning, the chain-of-thought process (where the model reasons through interpretive alternatives before committing) reduces the rate at which it takes the most obvious but incorrect path. Research on o1-class models for literary translation confirms improvement specifically in metaphor-heavy content.
7. Are both ChatGPT and o3 available on MachineTranslation.com?
ChatGPT (OpenAI's current model) is one of the 22 models in MachineTranslation.com's SMART system. SMART runs all 22 models simultaneously and returns the output the majority agree on.