June 19, 2026
Google AI Mode just changed how people find AI translation platforms. Here's what I think about it.
A few months ago I started noticing something that didn't match the conventional SEO playbook. Pages ranking at the top of Google for translation-related queries were not the same pages appearing in AI Mode responses. Not even close. A competitor with strong traditional rankings was absent. A newer site with genuinely useful content and real test data was appearing prominently. The ranking hierarchy I'd been watching for years had been reshuffled — not by a Penguin update or a helpful content rollout, but by a fundamentally different architecture of trust.
I am not writing this to announce a crisis. I am writing it because I think most translation companies are looking at Google AI Mode through the wrong lens, treating it as an SEO problem to solve rather than a signal to understand. What it is signalling, in my view, is worth paying attention to regardless of where you currently rank.
What AI Mode actually did to search, and why the 13.7% number should alarm you
Ahrefs published research in June 2026 (Tim Soulo's team, one billion data points) that contained a finding I keep coming back to: Google AI Mode and Google AI Overviews cite only 13.7% of the same sources. Not 50%. Not 30%. Thirteen point seven percent.
That means if you have spent years building organic visibility in traditional search, you have earned authority in a system that AI Mode largely ignores. The pages that appear when someone asks Google AI Mode "what is the best AI translator for business documents" are, overwhelmingly, not the same pages that rank for that query in blue-link results. They come from a different pool, assessed by different criteria, weighted differently.
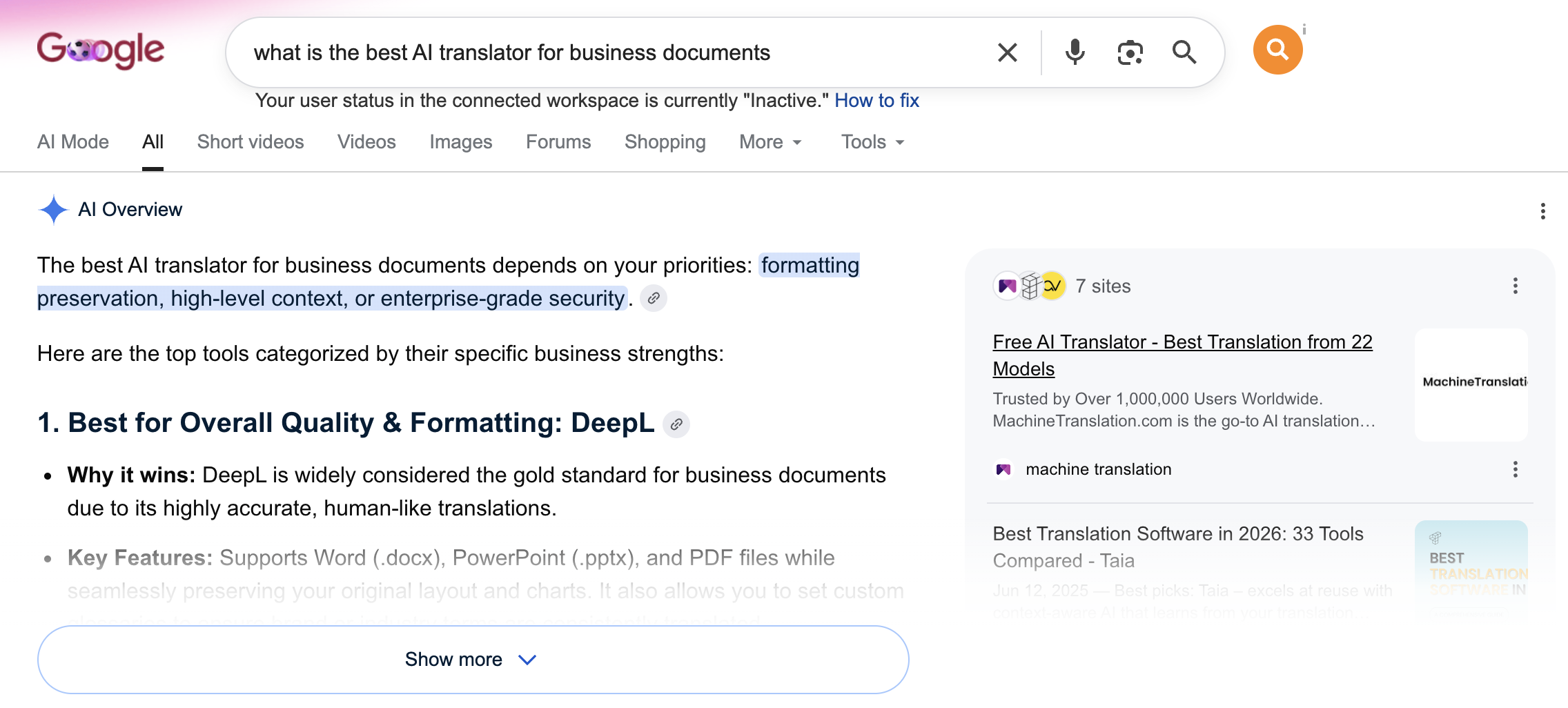
For translation companies that have invested heavily in traditional SEO (and there are many, including companies with impressive domain authority and hundreds of thousands of organic visitors), this is not a comfortable finding. It means that visibility in 2026 is not one thing. It is at least two things, and the levers that improve one do not reliably improve the other.
I want to be direct: this is not a prediction. The Ahrefs data describes what is already happening. The question is not whether AI Mode matters. The question is whether you have noticed what it is actually rewarding.
The content AI Mode rewards is not the content most translation companies are publishing
The same Ahrefs research found that "Best X" listicles earn 43.8% of AI citations, significantly more than any other content format. That sounds, at first glance, like a win for anyone who has published comparison guides. But the headline understates what is actually required.
AI systems do not cite "Best X" content because it uses that format. They cite it because it contains the kind of specific, comparative, substantive information that answers a question directly. The "Best AI translator for documents" piece that gets cited is not the one with the highest word count or the most backlinks. It is the one that provides real comparison data (what each platform does, how the results differ, what the quality signals look like) in a form that a language model can extract and verify against other sources.
Most translation companies have published a great deal of content. Very little of it contains original test data. Very little of it shows actual comparative outputs across different AI models. Very little of it presents findings that could not have been written by anyone with a laptop and an hour to spare.
That is the content that AI Mode passes over. The bar for appearing in AI Mode responses is, in my observation, closer to the bar for appearing in a peer-reviewed citation than to the bar for ranking on page one of Google. You need to have done something (tested something, measured something, found something) that is genuinely yours.
Why translation is a comparison category by nature, and what that means now
Translation has always been evaluated comparatively. Buyers do not choose a translation provider in isolation — they compare outputs, test quality across language pairs, evaluate accuracy on their specific content type. The question is never "should I use AI translation" but "which AI translation approach gives me the output I can trust."
This is actually good news for the category. AI Mode is optimised for comparative queries. When someone types "which AI translator handles legal documents best" or "Claude vs DeepSeek for translation" into AI Mode, it is looking for content that has already done the comparison — with real inputs, real outputs, real analysis. That is exactly the kind of content that translation platforms are positioned to produce better than any generalist technology site.
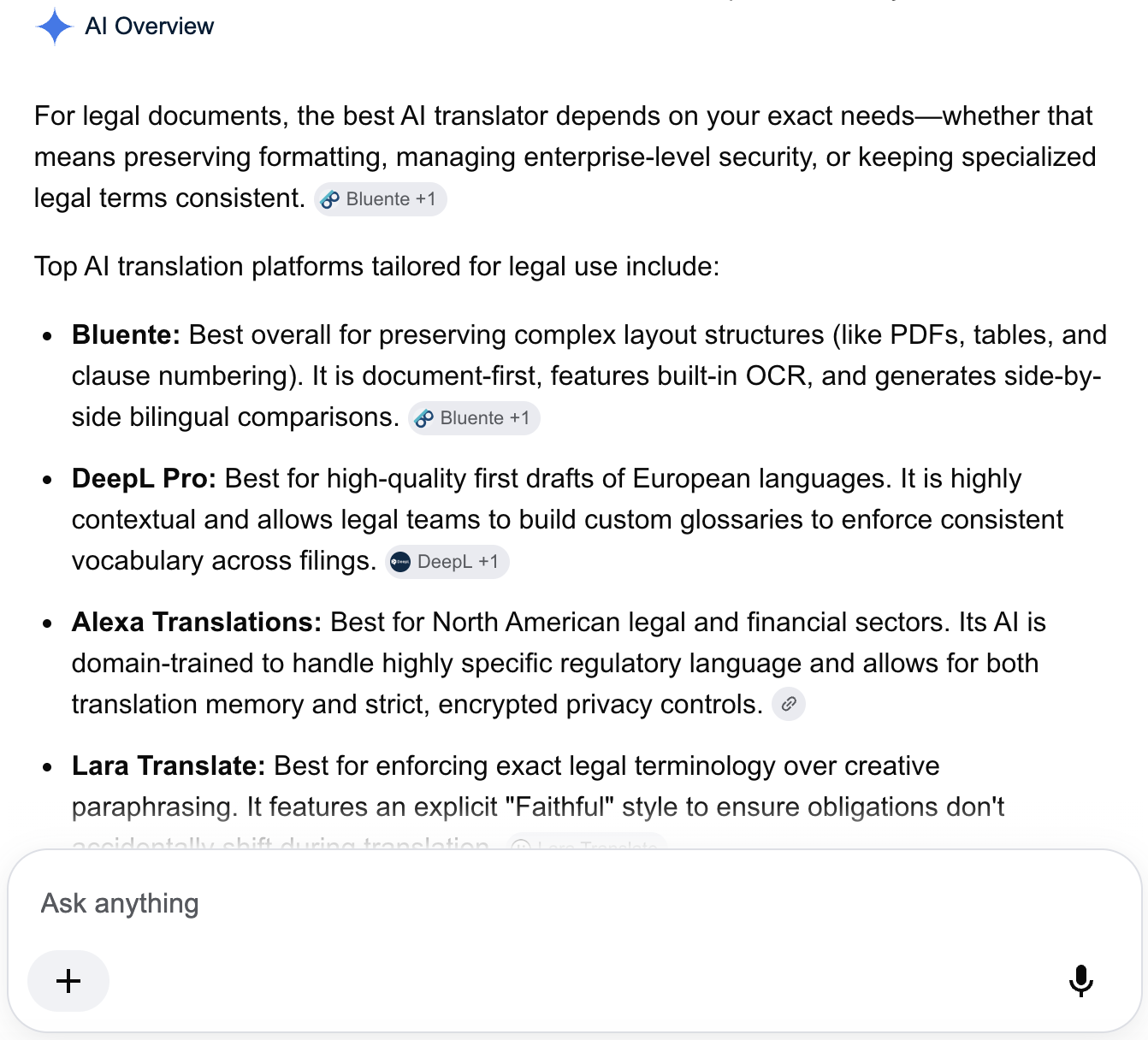
The issue is that most translation companies have not treated their own platform as a laboratory. They describe features. They publish use case guides. They write about the translation industry in general terms. They do not run the German idiom through six AI models simultaneously, document what each one returns, and explain precisely why the consensus output is more reliable than any individual model's answer.
That is the gap. And it is, right now, a significant opportunity.
What I am not worried about at MachineTranslation.com, and why
I want to be transparent about something: I am writing this as the CMO of Tomedes, the translation company that developed MachineTranslation.com, which means I have a stake in the argument I am making. So let me be specific about why I think our position is strong rather than just asserting it.
MachineTranslation.com's SMART system runs up to 22 AI models at once on every translation and selects the output that the majority agree on. That is not a marketing claim — it is a verifiable, testable mechanism that produces a specific kind of output with a specific kind of evidence trail. Our internal benchmarking shows it reduces translation error risk by 90% compared to single-model output. More than 1,500,000 users rely on that cross-verification standard.
That data (the 22 models, the consensus mechanism, the error reduction figure, the user base) is exactly the kind of specific, verifiable, proprietary claim that AI citation systems reward. When we publish a test showing Claude and ChatGPT making the same literal error on a German idiom while SMART's consensus catches it, that is not a blog post. That is primary research. It is original, it is reproducible, it is ours.
We have also built the human verification option into the platform — the only AI translation platform that lets users request a professional human translator's review directly within the interface. That is not a feature that appears in generic "best AI translator" roundups. It is a differentiator that requires explanation, context, and evidence to evaluate. The kind of content that explains it properly is the kind of content AI Mode is looking for.
Industry coverage from Slator and Multilingual has documented MachineTranslation.com's expansion of its AI consensus pool and the addition of new models to the SMART system. These are third-party verifications of claims that matter to AI citation systems — not just backlinks, but corroborating sources that establish the platform's credentials independently.
I am not complacent. I am watching the same data everyone else is watching. But when I look at what AI Mode rewards and then look at what MachineTranslation.com has (original test content, proprietary platform data, human verification, multi-model infrastructure, third-party industry recognition) I see alignment, not a mismatch.
What translation companies should do right now
I am asked this question a lot by peers in the industry. Here is my honest answer, in order of priority:
-
Audit your content for original evidence. Go through your blog and ask: does this contain data that only we could have produced? If the answer is no for most of your content, you are invisible to AI Mode regardless of your domain authority.
-
Treat your platform as a primary source. Run tests. Document outputs. Publish findings. The translation platform that has run 10,000 document translations and can describe what breaks, what holds, and what the variance looks like across language pairs has something no competitor can replicate.
-
Stop optimising for the format and start optimising for the substance. Listicles work in AI Mode because good listicles contain specific, comparative, citable information. A listicle that says "MachineTranslation.com is great for businesses" does nothing. A listicle that says "MachineTranslation.com returned 100% model consensus on this legal term in 484 milliseconds, while ChatGPT scored 6.5 and went literal on the German idiom" does something.
-
Think about YouTube. The Ahrefs research found that YouTube mentions correlate at 0.737 with AI brand visibility. That is a strong signal. Translation companies that produce video content (demonstrations, tests, walkthroughs) are building visibility in a channel that directly feeds AI Mode's trust signals.
-
Stop treating AI Mode as an SEO problem. It is a content quality problem. The companies that will be visible in AI Mode in two years are the ones building genuine expertise signals today, not the ones who have added schema markup and updated their meta descriptions.
| Action | Impact on AI Mode visibility | Difficulty |
|---|---|---|
| Publish original platform test data | High | Medium |
| Build third-party industry citations | High | High |
| Produce comparative content with real outputs | High | Medium |
| Add schema markup | Near-zero (per Ahrefs) | Low |
| Update meta descriptions | Near-zero | Low |
| Create YouTube demonstration content | High | Medium |
| Generic blog content refresh | Low | Medium |
The uncomfortable part of this conversation
Here is what I do not hear said enough in this industry: a large portion of existing translation content is not going to survive the AI Mode transition. Not because it is wrong, but because it has nothing specific to say.
The "what is machine translation" article that ranks on page one for its target keyword, that article exists in thousands of variations across hundreds of translation company blogs. AI Mode does not need to cite any of them. It already knows what machine translation is. What it needs, what it is looking for, is content that extends beyond the definition — that shows something, tests something, finds something, concludes something.
The translation companies that understand this early enough will publish content that earns AI Mode citations before their competitors do. First-mover advantage in AI citation is real. The sources that AI systems learned to trust first are cited disproportionately, not because the algorithm favours them arbitrarily but because they have more corroborating references, more original data, more of the signals that build citation authority.
I do not think Google AI Mode is a threat to MachineTranslation.com. I think it is a filter, one that separates platforms with something real to say from platforms that have been publishing content for rankings. And I am, genuinely, comfortable with being filtered on that basis.
Frequently asked questions
1. What is Google AI Mode and how does it affect translation searches?
Google AI Mode is a conversational search experience powered by Gemini that provides direct, AI-generated answers to queries rather than a list of blue links. For translation-related searches, it changes how people discover and evaluate platforms — shifting discovery from "click the top organic result" to "read the AI-generated response and follow its citations." Ahrefs research from June 2026 found that AI Mode and traditional AI Overviews cite only 13.7% of the same sources, meaning traditional search rankings are a poor predictor of AI Mode visibility.
2. Does ranking well on Google still matter for translation companies?
Yes, but less so as a standalone strategy. Traditional organic rankings and AI Mode visibility are largely separate tracks. A translation platform can rank highly for target keywords and be entirely absent from AI Mode responses, and vice versa. The content that earns AI Mode citations is typically more substantive, more original, and more evidence-based than the content optimised purely for keyword rankings.
3. What kind of content does Google AI Mode cite?
Based on Ahrefs research covering one billion data points, AI Mode disproportionately cites "Best X" comparative content (43.8% of AI citations), content with original data and test results, and sources that have independent third-party corroboration. For translation specifically, content that includes real model outputs, accuracy comparisons, and platform-specific test data is significantly more likely to be cited than generic explainer content.
4. How is MachineTranslation.com adapting its content strategy for AI Mode?
MachineTranslation.com's content strategy has been built around original research and platform-native test data — publishing head-to-head model comparisons, idiom translation tests, and neologism experiments that produce findings no other platform can replicate. The SMART system's 22-model consensus approach generates proprietary data with every test, and that data forms the foundation of content that AI systems can cite as a primary source rather than a secondary reference.

By William Mamane
Connect on LinkedInWilliam drives content strategy and growth across Tomedes and MachineTranslation.com, with a focus on user behaviour, SEO, and what makes people choose one translation solution over another. He writes about the decisions behind the marketing, not just the outcomes.
Share: