June 10, 2026
GPT-4.1 vs DeepSeek V3: Accuracy, hallucination, and translation performance compared
The question most translation teams are quietly asking in mid-2026 is not "should we use AI?", that decision was made. The real question is which AI model to standardise on, and whether the answer is the same for every language pair, every document type, and every budget.
GPT-4.1 and DeepSeek V3 have emerged as the two most frequently evaluated options for professional translation workflows. They represent genuinely different philosophies: one is a tightly governed, commercially polished API from OpenAI; the other is an open-weight, MIT-licensed model from a Chinese research lab that quietly outperformed several proprietary competitors on WMT24 benchmarks. Neither is universally better. The case for each depends on what you are translating, for whom, and under what constraints.
This article breaks down both models across the dimensions that matter most to translators, localization managers, and enterprise buyers: accuracy on real language pairs, hallucination behaviour, handling of constrained tasks like glossary adherence, and the total cost of running either at scale.
Table of contents
- Why this comparison matters right now
- What each model actually is
- Head-to-head: Translation accuracy and benchmark performance
- Which model hallucinates more, and when?
- Which model handles constrained translation better?
- Cost and deployment: What changes at scale
- How to test both models without committing to either
- Which model should you choose for your translation workflow?
- Frequently asked questions
- Related comparisons
Why this comparison matters right now
Translation buyers have historically evaluated machine translation on a narrow axis: BLEU score versus price. LLMs break that frame entirely. GPT-4.1 and DeepSeek V3 are not Machine Translation (MT) engines in the traditional sense — they are general-purpose models with strong multilingual capabilities, and their performance on translation tasks varies by architecture, training data, and the way you prompt them.
That variability is the crux of the evaluation problem. A localization manager testing both models on English→Spanish marketing copy may see near-identical output quality. The same manager testing Arabic→English legal documents will likely see a meaningful gap — but which model comes out ahead depends on whether the document contains named entities, technical jargon, or cultural references that require world knowledge rather than pattern-matching.
The stakes are also asymmetric. DeepSeek V3 is orders of magnitude cheaper to run, especially self-hosted. GPT-4.1 carries a significant cost premium. If both models deliver acceptable quality on your specific workload, the cost difference can determine whether an AI translation workflow is economically viable at scale.
What each model actually is
GPT-4.1: OpenAI's instruction-tuned flagship
Released in April 2025, GPT-4.1 is OpenAI's most instruction-adherent model to date. Its headline improvements over GPT-4o are not raw translation fluency (it was already strong there) but precision in following complex, multi-part instructions. For translation workflows, this matters specifically in constrained tasks: applying a client glossary, preserving document formatting across long texts, maintaining a specific register, or adhering to a do-not-translate list.
GPT-4.1 supports a one-million token context window, which means it can process book-length documents in a single call. On structured output tasks (generating translation memories in JSON, producing segment-level quality scores alongside the translation, formatting bilingual tables), it is demonstrably more reliable than its predecessors. The tradeoff is cost: GPT-4.1 sits at a higher price tier than most alternatives, including DeepSeek V3.
DeepSeek V3: The open-source challenger
DeepSeek V3 (the current production version is DeepSeek-V3-0324) is a 685-billion parameter model built on a Mixture-of-Experts architecture — meaning only a subset of its parameters activates for any given input, which keeps inference costs low despite the enormous total parameter count. It is released under the MIT licence, meaning organisations can self-host it, fine-tune it, and deploy it commercially without per-token fees to a third party.
The model's translation performance drew significant attention after WMT24, where it posted strong BLEU and COMET scores on Chinese↔English, Arabic, and Korean language pairs — in several cases outperforming GPT-4o. For teams working heavily in Asian or Middle Eastern language pairs, DeepSeek V3 is not a compromise choice. It is genuinely competitive at a fraction of the cost.
Head-to-head: Translation accuracy and benchmark performance
| Dimension | GPT-4.1 | DeepSeek V3 |
|---|---|---|
| Context window | 1,000,000 tokens | ~64,000 tokens (standard) |
| Architecture | Dense transformer | Mixture-of-Experts (685B params) |
| Licence | Proprietary | Open-source (MIT) |
| Self-hosting | Not available | Available |
| WMT24 Chinese↔English | Strong | Very strong, outperformed GPT-4o on several pairs |
| WMT24 Arabic translation | Competitive | Strong, especially on specialised text |
| Instruction-following | Best-in-class vs GPT-4o | Good; less consistent on complex multi-step prompts |
| Structured output | Highly reliable | Reliable; minor formatting drift on long outputs |
| Hallucination tendency | Reduced vs GPT-4o | Occasional on low-resource pairs |
| Relative API cost | Higher | Significantly lower |
On general translation accuracy for high-resource language pairs (English, French, Spanish, German, Chinese, Japanese), both models perform at a level that professional translators describe as "post-edit ready." The gap between them on fluency and adequacy alone is not large enough to drive a purchasing decision for most teams.
The meaningful differences emerge in three specific scenarios: low-resource languages, constrained tasks, and hallucination-prone document types.
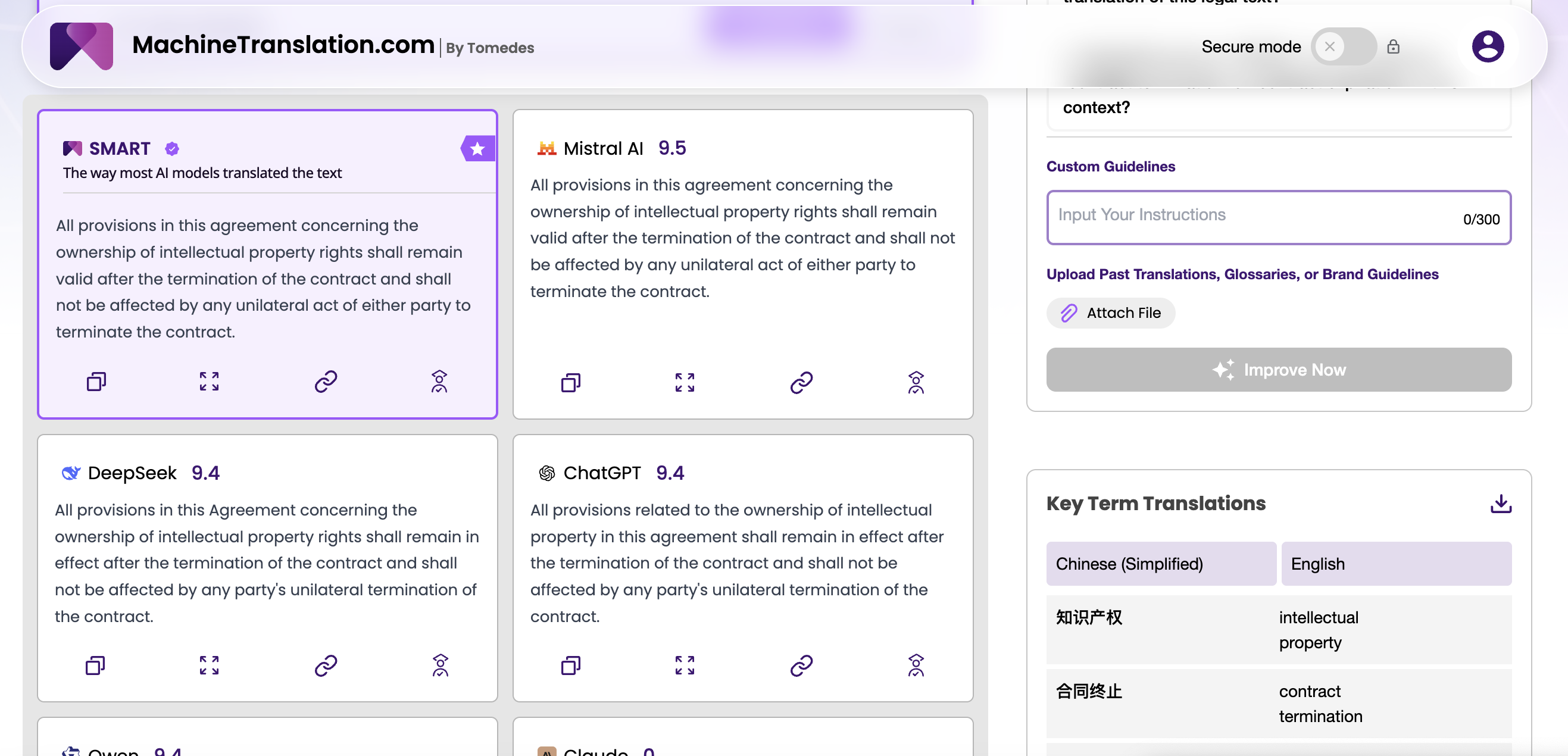
Which model hallucinates more, and when?
Hallucination in translation is not the same as hallucination in general-purpose generation. The model is working from a source text, it is not inventing facts from nothing. Hallucination here manifests as added content not in the source, dropped clauses, or substituted named entities. In a legal or medical translation, any of these errors can have serious consequences.
GPT-4.1 shows a measurably lower hallucination rate than GPT-4o, particularly on long documents where earlier OpenAI models would begin drifting from the source in later segments. The combination of a one-million token context window and improved instruction-following means GPT-4.1 maintains fidelity to the source for longer without needing special prompting strategies. For enterprise buyers processing regulatory filings, product documentation, or contracts, this is a meaningful reliability upgrade.
DeepSeek V3's hallucination profile is different in character. On well-supported language pairs (Chinese, English, Arabic), it is generally reliable. The risk increases on low-resource pairs: Korean→Swahili, Arabic→Vietnamese, or any pair where one language is underrepresented in the training corpus. In these cases, DeepSeek V3 has been observed generating plausible-sounding but source-unsupported content, particularly when the source contains ambiguous named entities or domain-specific terminology.
The practical implication: if your language pair portfolio is concentrated in high-resource languages, DeepSeek V3's hallucination risk is manageable with standard QA processes. If you are running translations at scale across low-resource pairs, GPT-4.1's additional reliability may justify the cost premium.
💬 "What we see consistently on the platform is that the gap between GPT-4.1 and DeepSeek V3 on hallucination isn't about volume, it's about where it happens. On English, French, or Spanish content, most professional translators wouldn't notice a meaningful difference in reliability. The issues with DeepSeek V3 tend to surface on Korean or Arabic documents that contain unfamiliar proper nouns or highly domain-specific terminology. GPT-4.1 handles those edge cases more conservatively, it's less likely to fill a gap with something plausible-sounding."
— Linguist on MachineTranslation.com
Which model handles constrained translation better?
Constrained translation (where the model must respect a glossary, maintain a brand register, avoid translating certain terms, or preserve document structure like headers and footnotes) is where GPT-4.1's architecture advantages become most tangible.
When you provide a system prompt with a 200-term glossary and instruct the model to flag any source segment where an exact match cannot be found, GPT-4.1 follows those instructions with a consistency earlier models could not sustain beyond a few hundred tokens. In a one-million token context window, this means you can translate a 400-page technical manual with a complex terminology constraint in a single call and expect coherent glossary application throughout.
DeepSeek V3 handles straightforward constraints adequately — single-term do-not-translate instructions, basic register preferences, simple formatting rules. Where it underperforms is in complex, compound instruction sets. As the number of simultaneous constraints increases, DeepSeek V3 begins prioritising some instructions over others in ways that are difficult to predict without testing. For localization teams managing multi-level style guides and large translation memories, this inconsistency creates downstream QA overhead that partially offsets the model's cost advantage.
For pure, unconstrained translation of standard content (general business communications, marketing copy, e-commerce product descriptions), the constraint-handling gap between the two models is largely irrelevant. The difference matters most to teams running enterprise-grade workflows where translation is one step in a multi-stage localization pipeline.
💬 "We ran both models against the same glossary on a legal document set, about 120,000 words across eight language pairs. GPT-4.1 respected the terminology constraints almost perfectly. DeepSeek V3 was close, but it would occasionally substitute a preferred term with a near-synonym that our clients had specifically asked us to avoid. At that volume, 'almost' isn't good enough. For unconstrained content, we use DeepSeek V3 and the cost savings are significant. For anything with a client-approved glossary, we're still running GPT-4.1."
— Localization Manager on MachineTranslation.com
Cost and deployment: What changes at scale
Cost is where the two models diverge most sharply, and where the evaluation has to account for more than per-token pricing.
GPT-4.1 is priced at a premium tier. For organisations processing millions of words per month through the OpenAI API, that cost compounds quickly. The model is not available for self-hosting, which means every token carries an API fee that cannot be reduced through infrastructure investment.
DeepSeek V3's cost profile is fundamentally different. Via the DeepSeek API, it is significantly cheaper per token than GPT-4.1. Self-hosted, the economics shift further: organisations with GPU infrastructure can run DeepSeek V3 at a cost determined primarily by compute rather than per-token licensing. For high-volume translation operations (global e-commerce catalogues, multilingual content pipelines, regulatory document processing), the difference can represent hundreds of thousands of dollars annually at enterprise scale.
DeepSeek V3's open-source licence also matters for data-sensitive sectors. Legal, financial, and healthcare organisations that cannot send client documents to external APIs can deploy DeepSeek V3 on-premises. GPT-4.1 offers no equivalent option.
The decision rule is relatively clean: if your workload is high-volume, your language pairs are well-supported, and your data governance policies allow for API services or on-premises deployment, DeepSeek V3 delivers competitive quality at materially lower cost. If your workload involves constrained translation, long-document fidelity, or low-resource language pairs, GPT-4.1's reliability may be worth the premium.
How to test both models without committing to either
The practical obstacle to model selection for most localization teams is not understanding the benchmarks — it is the friction of setting up independent API integrations with both models, designing comparable test conditions, and running a meaningful evaluation on your own content.
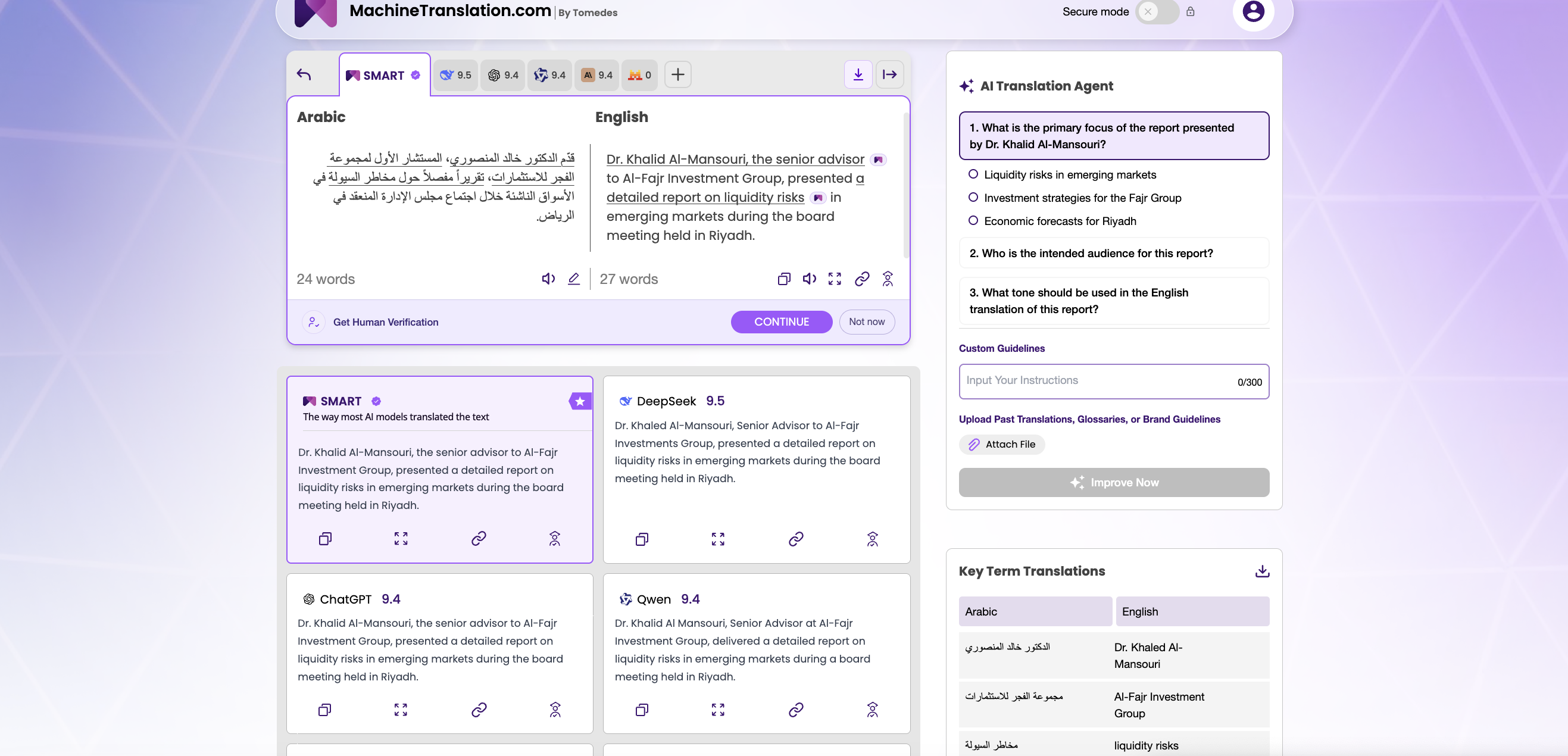
MachineTranslation.com removes that obstacle. The platform runs GPT-4.1 and DeepSeek V3 side-by-side, giving professional translators and localization managers the ability to submit the same source text to both models simultaneously and compare outputs in real time — without a separate API key, without a procurement process, and without committing to either model.
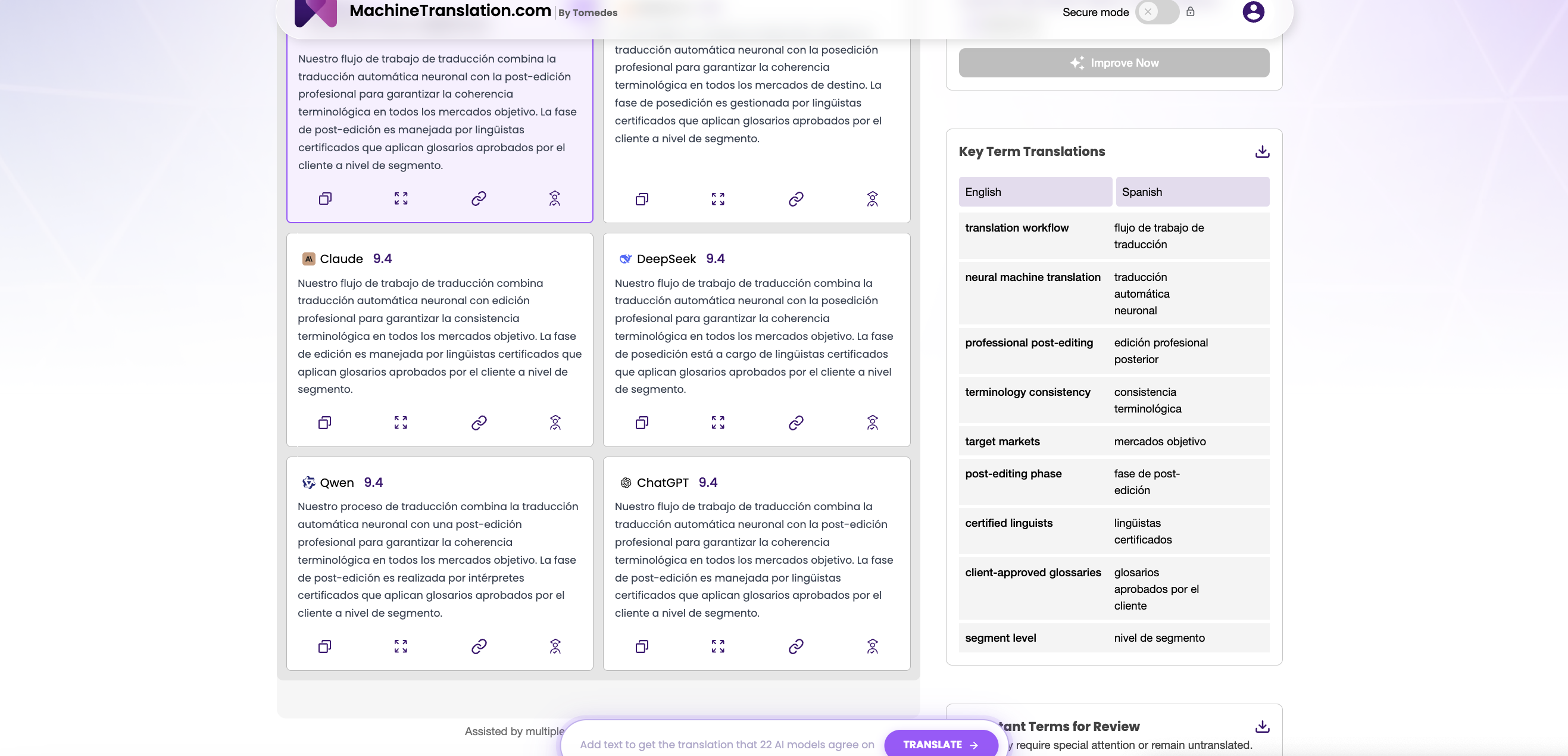
This matters because benchmark performance at the dataset level does not always predict performance on your specific content. A model that posts strong COMET scores on WMT24 Chinese→English news text may underperform on your company's specific terminology or domain. The only evaluation that is decision-relevant is one conducted on your own documents, with your own constraints, in your own language pairs.
MachineTranslation.com's positioning as a neutral multi-model platform means it has no commercial incentive to favour either GPT-4.1 or DeepSeek V3. The platform's role is to give you the comparison data to make that call yourself, and then to run whichever model you select at production scale once the evaluation is complete. Although of course, it also gives you the translation that most AI models agree on as the default best translation.
For teams also evaluating across the OpenAI model tier, how GPT-4.1 compares to other OpenAI models (including GPT-4.5 and GPT-4o) provides useful context before committing to a model version. And for teams who evaluated how DeepSeek V3 compares to GPT-4o earlier in 2025, this article covers what has changed with GPT-4.1's release.
Which model should you choose for your translation workflow?
Rather than a single recommendation, the following framework reflects the decision logic that most professional translation teams will find useful:
Start with your language pairs. If your portfolio is concentrated in Chinese↔English, Arabic, or Korean, DeepSeek V3's WMT24 performance makes it the natural first test. If you are working primarily in European languages with constrained terminology, GPT-4.1 is likely to produce more consistent output from day one.
Assess your constraint complexity. Single-level constraints (one glossary, one register) are handled adequately by either model. Multi-level constraints (glossary + format + do-not-translate list + QA scoring), GPT-4.1 is more reliable at present.
Map your volume against the cost differential. Under 500,000 words per month, the absolute API cost difference may not materially affect your budget. Over that threshold, DeepSeek V3's cost advantage becomes increasingly difficult to ignore.
Factor in your data governance requirements. If documents cannot leave your infrastructure, DeepSeek V3 self-hosted is currently the only viable option of the two.
Run the evaluation on your content, not on benchmarks. Use MachineTranslation.com to submit representative samples from your actual workload to both models and score the outputs against your own quality criteria before committing.
For a broader view of where these models sit in the current AI translation landscape, the best AI translation tools in 2026 covers the full competitive field, including how LLMs compare to purpose-built translation infrastructure.
Frequently asked questions
1. Is GPT-4.1 better than DeepSeek V3 for translation?
Neither model is universally better. GPT-4.1 outperforms DeepSeek V3 on constrained translation tasks, long-document fidelity, and low-resource language pairs where hallucination risk is higher. DeepSeek V3 matches or outperforms GPT-4.1 on several WMT24 benchmarks (particularly Chinese↔English, Arabic, and Korean) and is significantly cheaper to run at scale or self-hosted.
2. Does DeepSeek V3 hallucinate more than GPT-4.1?
On high-resource language pairs, the hallucination difference is relatively small. The gap widens on low-resource pairs and domain-specific content with rare named entities, where DeepSeek V3 has shown higher rates of source-unsupported additions or substitutions. GPT-4.1 demonstrates reduced hallucination compared to GPT-4o, particularly on longer documents.
3. Can I use DeepSeek V3 commercially?
Yes. DeepSeek V3 is released under the MIT licence, which permits commercial use including fine-tuning and self-hosting. Organisations that cannot send documents to external APIs can deploy DeepSeek V3 on their own infrastructure. GPT-4.1 requires use of the OpenAI API under OpenAI's terms of service and is not available for self-hosting.
4. Which model is better for Chinese to English translation?
DeepSeek V3 has an edge on Chinese↔English based on WMT24 benchmark results. However, for Chinese→English translation involving constrained terminology, legal precision, or complex formatting, GPT-4.1's instruction-following capability makes it more reliable in production workflows where a human translator will post-edit the output.
5. Can I test GPT-4.1 and DeepSeek V3 side-by-side before choosing?
Yes — MachineTranslation.com runs both models simultaneously (and 20+ more) and lets you compare outputs on your own content in real time, without separate API accounts or a procurement process.
6. How does DeepSeek V3 compare to Claude for translation?
For teams also evaluating Anthropic's model, the Claude vs DeepSeek V3 comparison covers the key differences in architecture, accuracy, and deployment options across translation-relevant scenarios.
Related comparisons
- How DeepSeek V3 compares to GPT-4o — the benchmark that established DeepSeek V3's competitive position before GPT-4.1 was released
- How GPT-4.1 compares to other OpenAI models — including GPT-4.5 and GPT-4o, for teams evaluating across the OpenAI tier
- Claude vs DeepSeek V3 — Anthropic's flagship vs DeepSeek V3 across translation and general task performance
- Best AI translation tools in 2026 — the full competitive landscape for AI-assisted translation workflows