June 26, 2026
The French idiom every AI model agreed on, and the one they didn't
I've been running idiom tests on MachineTranslation.com for a while now. The pattern is almost always the same: put a figurative expression in, get four or five different outputs back, watch the models pull in different directions. That divergence is usually where the story is — which model understood the cultural register, which one translated too literally, which one landed closest to what a native speaker would say.
So when I ran "poser un lapin à quelqu'un" through every GPT and DeepSeek model we support and every single one came back with the same answer, I didn't feel reassured. I felt suspicious.
The first test: "poser un lapin à quelqu'un"
"Poser un lapin à quelqu'un" is a French idiom meaning to stand someone up, to fail to show up for a meeting or date without warning. Literally, it means "to put a rabbit on someone," which tells you nothing. The phrase has been documented, analysed, and cited in French-English linguistic resources for decades. It has a single clean English equivalent that any anglophone who has spent time around French people would know.
I ran it French → English through GPT-4.1-NANO, GPT-4.1-MINI, GPT-4O-MINI, GPT-5.4, GPT-5.4-MINI, DeepSeek V4-Pro, and DeepSeek V4-Flash. The quality score came in at 9.4.
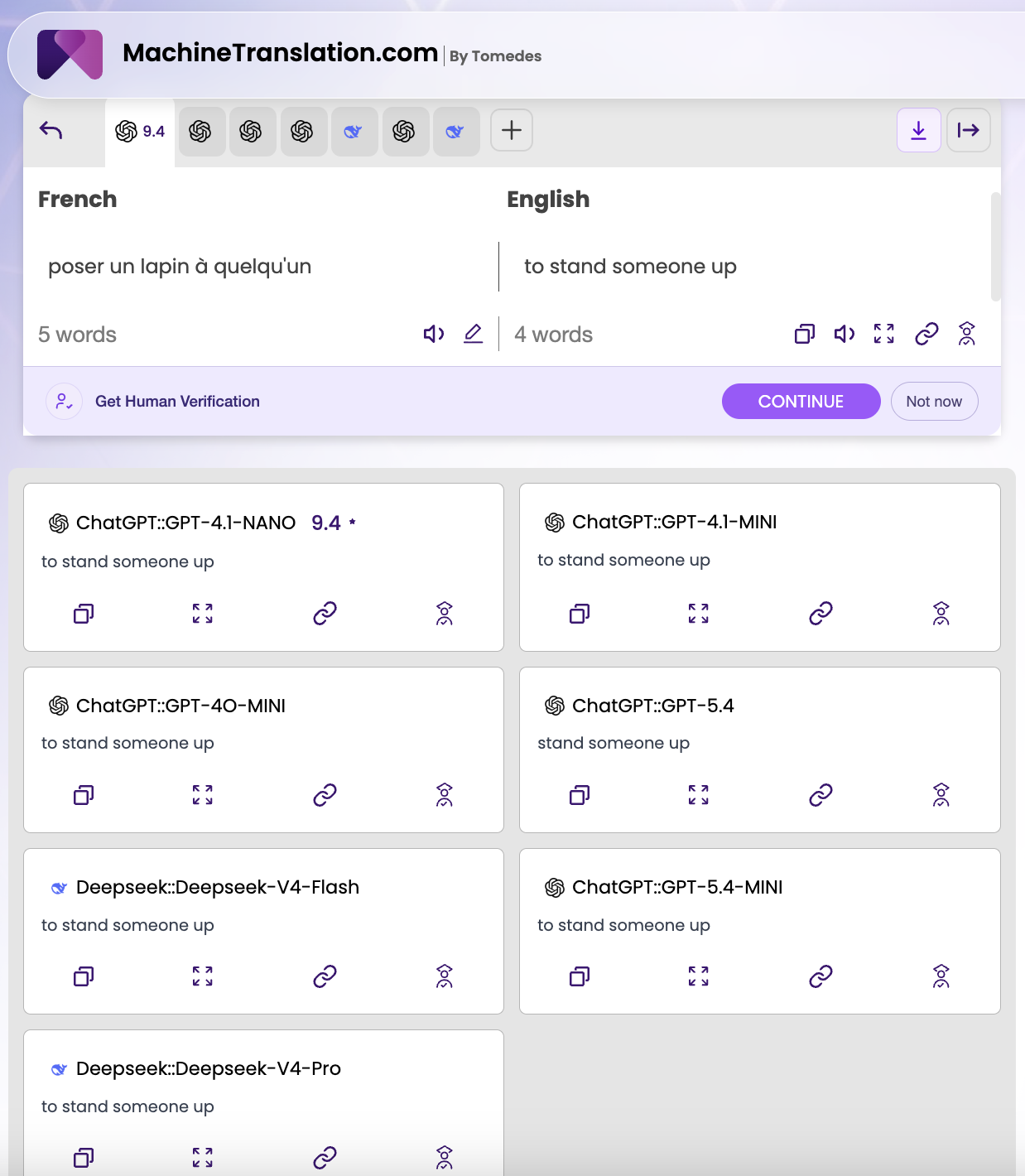
Every model returned: "to stand someone up."
All seven. Across two completely different AI families, developed by two different organisations, trained on different corpora, running on different architectures. The only variation was GPT-5.4, which returned "stand someone up" — dropping the infinitive "to." A one-word difference that changes nothing about the meaning and everything about the grammar.
I stared at the results for a moment. Then I went looking for something harder.
When every model agrees, is that a good sign?
The short answer is: yes, but not for the reason you might think.
When AI models converge on the same translation, it is not necessarily because they all understood the idiom. It may be because they all read the same reference. "Poser un lapin" is one of the most documented French idioms in existence. It appears in every French-English dictionary, every idiom guide, every "learn French expressions" resource on the internet. A model trained on enough French and English text will have encountered this phrase and its English equivalent thousands of times. The consensus is a measure of documentation, not comprehension.
That distinction matters in practice. If every model agrees because the answer is well-established in their training data, the agreement is reliable — but it is reliable in the same way a lookup table is reliable. Ask these same models about an idiom that has not been catalogued to the same degree and the consensus will not hold.
I wanted to see where it broke.
The second test: "avoir le cafard"
"Avoir le cafard" means to feel depressed, low, or melancholy. Literally, it means "to have the cockroach." The phrase has a well-documented origin (it is attributed to the French poet Charles Baudelaire, who used the word cafard to describe the crushing, crawling feeling of depression) but unlike "poser un lapin," it does not have a single canonical English equivalent. You can translate it as "to feel blue," "to feel down," "to have the blues," or "to be in low spirits." All four are correct. None is the only correct answer.
I ran the same test: French → English, same seven models. This is what came back.
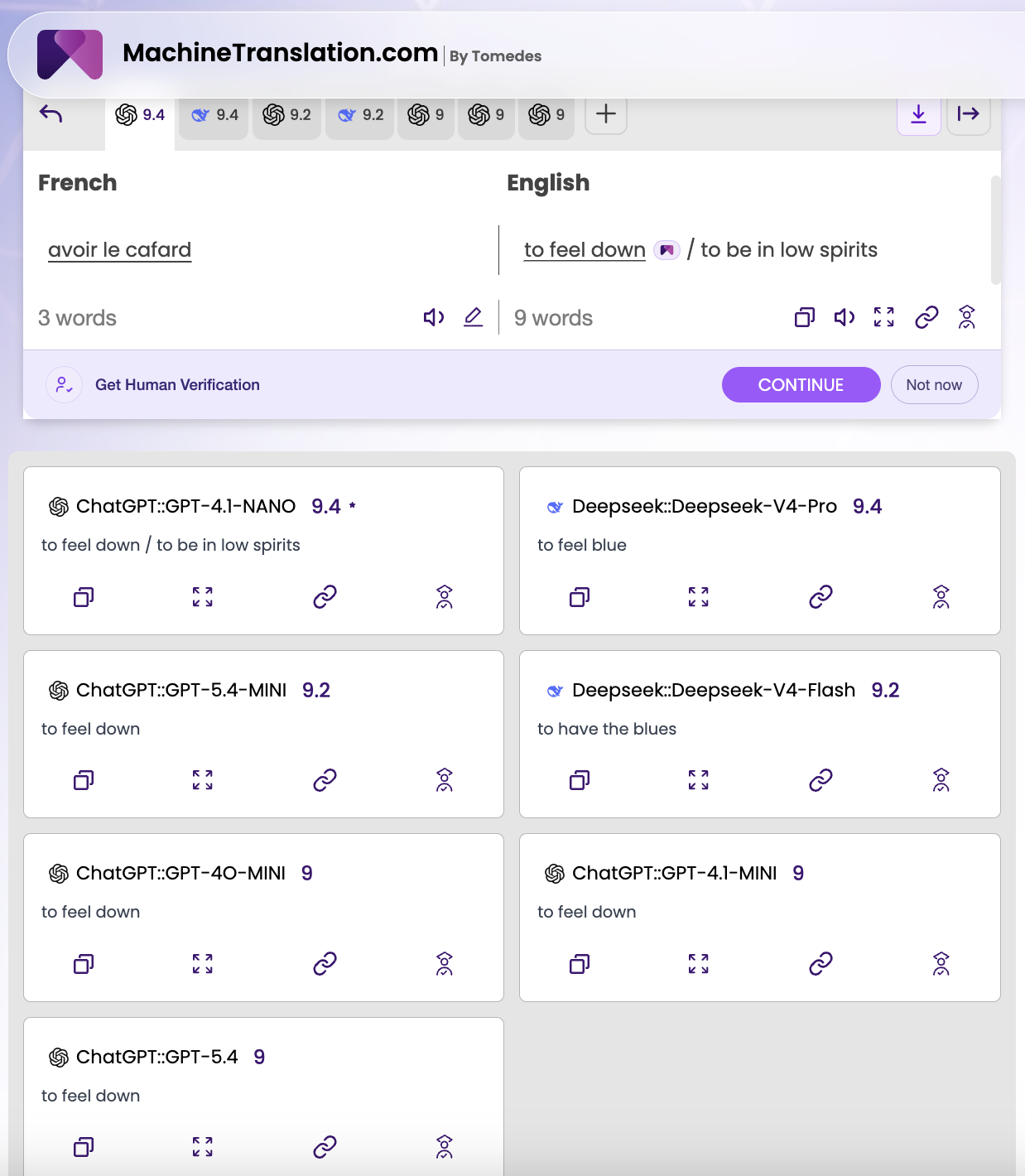
SMART output: "to feel down / to be in low spirits."
The individual model results split along model family lines in a way I did not expect.
The GPT models — GPT-4.1-NANO (9.4), GPT-5.4-MINI (9.2), GPT-4O-MINI (9), GPT-4.1-MINI (9), GPT-5.4 (9) — all returned "to feel down." Consistent across the entire GPT lineage, from the cheapest variant to the most capable. Every one chose the same phrase. Every one chose the most neutral, everyday option.
The DeepSeek models went somewhere else entirely.
DeepSeek V4-Pro (9.4) returned: "to feel blue." DeepSeek V4-Flash (9.2) returned: "to have the blues."
"To feel blue" and "to have the blues" are not wrong. They are, if anything, closer to the emotional register of Baudelaire's original usage — the image of heaviness and gloom that cafard was meant to convey. But they carry different cultural weight in English. "To have the blues" has a specific American resonance — it is the language of music, of Delta blues, of a tradition of expressing suffering through art. "To feel blue" is more literary. "To feel down" is more conversational. All three point at the same emotional state. None of them is interchangeable.
Why DeepSeek and GPT diverged, and why both were right
This is the part that interested me most. The disagreement between GPT and DeepSeek on "avoir le cafard" is not a translation error on either side. Both families identified the idiom correctly. Neither produced a literal translation ("to have the cockroach" does not appear anywhere in the results). The divergence is about which of several valid English expressions each model weighted most heavily in its training.
GPT's consistent choice of "to feel down" suggests a weighting toward contemporary, colloquial English — the kind of language most commonly used in everyday writing, digital communication, and modern media. It is the safest choice: broadly understood, no cultural specificity, no register complications.
DeepSeek's choices are more expressive. "To feel blue" and "to have the blues" both carry emotional depth that "to feel down" does not. If I were translating a passage of Baudelaire, DeepSeek's output would be closer to what I would want. If I were translating a customer support email, GPT's would be more appropriate.
The right answer depends on context neither model was given.
What SMART does when there's no single correct answer
On the first test, the models agreed because the answer was established. On the second test, SMART selected GPT-4.1-NANO's output ("to feel down / to be in low spirits") as the consensus output. The choice of that output is itself instructive: rather than picking a single phrase, GPT-4.1-NANO offered two, covering both the conversational and the more formal register. SMART selected it precisely because it acknowledged the ambiguity rather than resolving it arbitrarily.
That is the difference between a consensus mechanism and a single model in a case like this. A single model gives you one answer and no indication that other valid answers exist. A platform running multiple models in parallel shows you the full spread — and when the spread is this meaningful, it is information you need before you decide which translation fits your context.
What these two idioms revealed about how AI learns language
Between these two tests, I came away with something I did not expect to find.
The complete consensus on "poser un lapin" is not a sign that AI has solved French idiom translation. It is a sign that AI has memorised the most documented French idioms. There is a large overlap between those two things, but it is not a complete overlap. The further you move from the canonical, frequently cited expressions, the more the consensus thins and the more you start to see the seams.
"Avoir le cafard" is not an obscure phrase. It appears in every intermediate French textbook. And even here, the models split across register lines in a way that has genuine translation consequences.
The question that follows is one I keep returning to: if this is where things stand on well-known idioms, what happens with the expressions that have never been catalogued? The regional phrases, the generational slang, the professional or industry-specific figurative language that exists in a language but has not been indexed by the resources AI systems train on?
Those are the translations I find most interesting to run. And they are also, predictably, the ones where the results are most worth examining before you use them.
This post is based on internal testing on MachineTranslation.com's development platform. The multi-model version testing shown here is not yet publicly available. I'm sharing the finding because I think the observation is useful regardless of where you run your translations.

By Ofer Tirosh
Connect on LinkedInOfer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
Share: