April 10, 2026
How academics are using AI translation in 2026: A practical guide
The question of whether academics should use AI translation tools has been largely settled by practice. Across disciplines (history, medicine, linguistics, theology, classical studies, social science), researchers are already using these tools routinely for source reading, literature review, data collection, and document processing. The more productive question, the one this guide addresses, is how to use them well: which workflows produce reliable results, where the failure modes concentrate, and what the difference is between AI translation as a research accelerator and AI translation as a source of quiet errors.
The answer varies by use case. The decisions that matter (which tool, which level of scrutiny, when to escalate to human expertise) are not uniform across disciplines. A historian reading 19th-century German correspondence and a clinical researcher processing multilingual trial data face structurally different translation problems, even though both are reaching for the same category of tool.
This guide maps the four most active academic translation contexts, identifies the shared structural problem that cuts across all of them, and provides a practical framework for making the right call at each stage of a research workflow.
Table of contents
Four research contexts where AI translation has become a standard tool
The shared problem across all four contexts: confidence without verification
Why inter-rater reliability is the right frame for evaluating AI translation
What the Key Term Translations panel gives researchers that no other feature does
The academic translation decision matrix: matching tool to task
A note on research integrity and citing AI-assisted translation
FAQs
Four research contexts where AI translation has become a standard tool
Reading across foreign-language literature at scale
The growth of multilingual publishing in almost every academic field has outpaced the reading capacity of individual researchers. A historian of early modern Europe needs to work across German, French, Italian, Latin, and occasionally Dutch sources. A sociologist doing comparative policy research reads across legislative texts in languages that may be entirely outside their training. A classicist building a research database needs to process hundreds of texts before identifying the dozen that will receive close scholarly attention.
For all of these tasks, AI translation has become the first-pass tool of choice because it solves a throughput problem that no other approach addresses efficiently. The researcher does not need a publishable translation of every source they scan – they need to know what the source says, whether it is relevant, and which passages require closer attention. AI translation, used for this triage function, is a legitimate and well-established research practice.
A 2025 survey of professional translators found that AI tools are helping achieve faster turnaround times and greater efficiency, particularly by supporting research and comprehension of technical content – a finding that generalises directly to academic reading workflows, where the bottleneck is often comprehension volume rather than final translation quality.
Translating primary sources for archival and historical research
Primary source translation is a different use case from reading foreign-language literature. When a researcher translates a primary source for inclusion in an argument, for quotation in a published paper, or for use as evidence in a thesis, the translation is not a triage output – it is a scholarly claim. The standard shifts from "is this close enough to proceed?" to "is this exact enough to stand behind?"
This distinction is where most academic AI translation goes wrong. Researchers who use AI appropriately for reading-at-scale apply the same tool to citation-quality translation without changing their scrutiny level, and the errors that do not matter for triage matter enormously when a term's precise rendering becomes the basis of an argument. Research across academic users found that while AI translation software is commonly employed because of convenience and accessibility, users invariably acknowledged shortfalls particularly in dealing with words of ambiguity, cultural sensitivity, and technical or specialized text – exactly the categories most likely to appear in primary sources with scholarly weight.
For historical primary source translation, the appropriate workflow is: AI consensus translation as a first draft, followed by close review of every term flagged as low-confidence or split-decision by the translation system, and human expert review for any passage being directly quoted or cited as evidence.
Multilingual data collection and survey instruments
Cross-cultural research increasingly involves collecting survey data in multiple languages (questionnaires, interview instruments, rating scales) that must maintain conceptual equivalence across language versions. This is one of the most demanding translation contexts in academic research, because the failure mode is not a single mistranslated word but a systematic measurement error that invalidates the comparison between language groups.
Research comparing AI-supported translations of survey materials across 33 languages found that the statistical similarity between machine-generated and human translations varied considerably between target languages – highest for languages in the same language family as the source, and considerably lower for more distant language pairs. For researchers using AI to translate survey instruments into related European languages, the results are often good enough for a working draft that a native speaker can refine. For more distant language pairs, or for constructs with culturally loaded terminology (scales measuring trust, agency, honour, or identity), AI translation requires substantive expert review before deployment.
The practical implication is that AI translation for survey instruments should always be treated as a back-translation candidate: translate the instrument, then have an independent translator render it back into the source language, and compare the back-translation to the original. Divergences identify the items that need expert reworking, regardless of how fluent the forward translation looked.
Clinical and medical research documentation
Clinical research generates translation demands across two distinct document types that carry entirely different stakes. The first is internal research documentation (clinical notes, trial protocols, laboratory reports, imaging results) where translation supports comprehension and team coordination. The second is documentation with formal evidentiary status (consent forms, regulatory submissions, published trial data) where translation accuracy directly affects patient safety and regulatory compliance.
For internal documentation, AI translation is broadly appropriate with standard review practices. For formal evidentiary documents, individual top-tier AI models carry a hallucination rate of 10-18% during translation tasks, according to data synthesized from the Intento State of Translation Automation 2025 and MachineTranslation.com internal benchmarks – a rate that is entirely unacceptable for a clinical consent form or a regulatory submission. The appropriate tool for such documents is a consensus architecture that reduces that error rate to under 2%, combined with human verification for any document that will be cited in a formal proceeding or submitted to a regulatory authority.

The shared problem across all four contexts: confidence without verification
What connects these four very different use cases is a structural problem that individual AI models share regardless of their quality: they produce confident output without any signal of where that confidence is warranted and where it is not.
A single AI model translating a medieval theological term, a survey scale item, or a clinical imaging report will produce fluent output in every case – including the cases where it has paraphrased rather than translated, borrowed from adjacent vocabulary rather than using the technically correct term, or smoothed over an ambiguity the source text deliberately preserved. The fluency of the output contains no error signal. The researcher reading it sees a sentence that sounds right and proceeds.
Internal MachineTranslation.com data makes the cost visible: in a recent study, 34% of users admitted they were not confident enough in an AI translation to use it without checking. Among non-linguists (which describes the majority of researchers working outside their native language), 46% said they spent more time manually comparing outputs across tools than the AI translation saved them. The tool that was supposed to eliminate verification had simply relocated it.
The solution is not more scrutiny of a single model's output. It is an architecture that performs the verification structurally, before the output reaches the researcher. MachineTranslation.com's SMART system runs every translation through 22 AI models simultaneously (including ChatGPT, Claude, Gemini, DeepL, and 18 others) and returns the translation the majority agreed on, alongside a documented record of where they diverged. The divergence is the signal. It tells the researcher precisely where to apply scholarly judgment rather than requiring them to apply it uniformly to every word.
Why inter-rater reliability is the right frame for evaluating AI translation
Researchers across disciplines are already familiar with the concept of inter-rater reliability: the degree to which independent coders, raters, or reviewers agree on an interpretation when working from the same source material. In qualitative research, low inter-rater reliability on a coding scheme is a methodological concern. In clinical research, disagreement between independent readers of a diagnostic image triggers review. Agreement among independent assessors is treated as evidence of reliability; disagreement surfaces where the measure needs refinement.
This is precisely the epistemic logic behind consensus AI translation. When 22 independent AI models (each trained separately, each with its own tendencies and biases) converge on the same rendering of a term, that convergence is a reliability signal in the same sense that inter-rater agreement is a reliability signal. It does not guarantee correctness, but it provides the strongest available probabilistic basis for the output being right.
When those same models split (some rendering virtus as "virtue," others as "courage," others as "valour"), the split is not a defect in the tool. It is the tool performing its most important academic function: identifying the terms where the source material is genuinely ambiguous, where different scholarly traditions reach different conclusions, and where the researcher's judgment is required rather than a model's default.
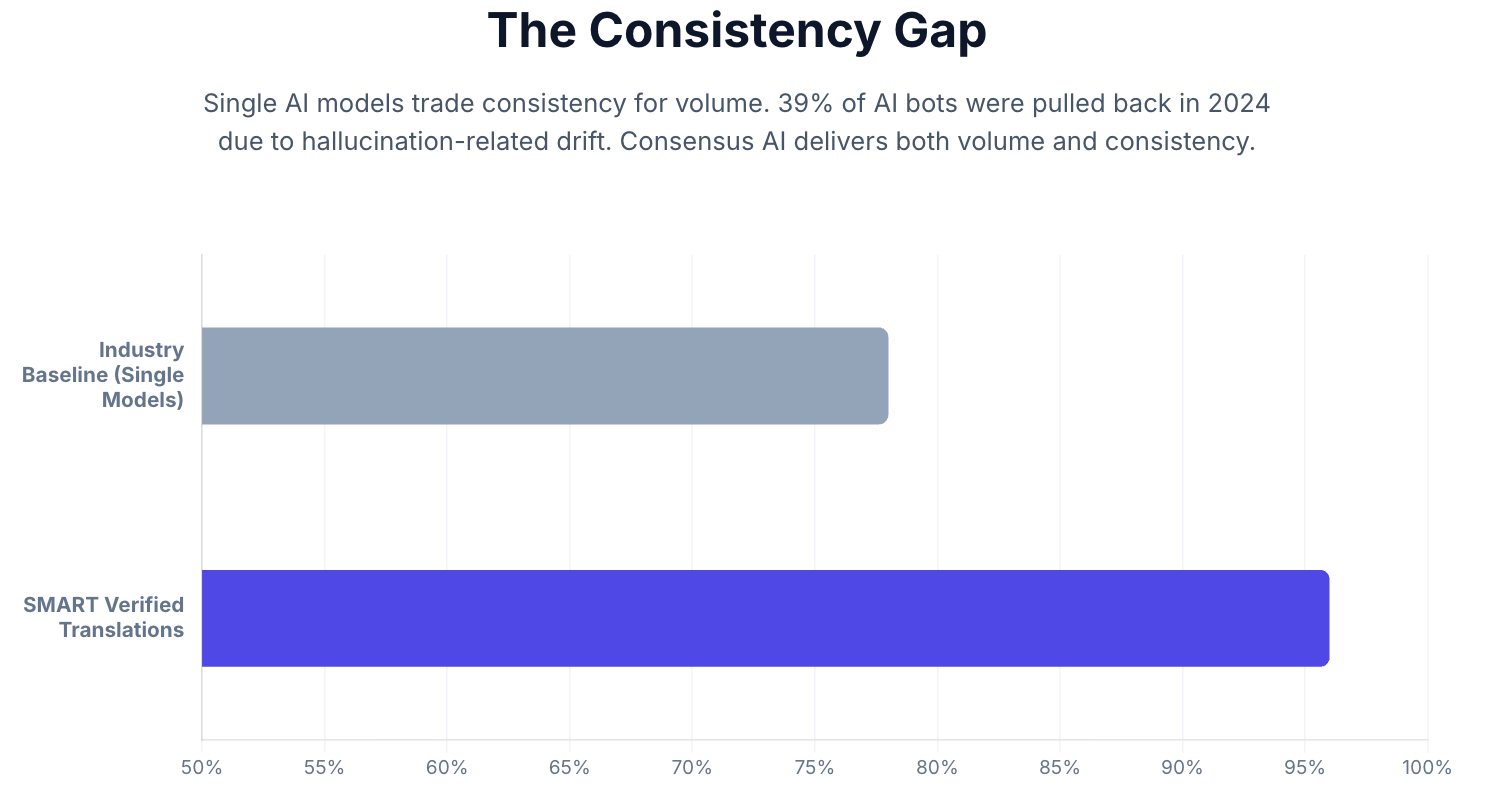
SMART-verified translations maintain consistent terminology and register at a rate exceeding 96% across multi-document workflows, compared to an industry baseline of approximately 78% for single-model outputs at equivalent volume. For researchers working across large corpora (multiple texts, multiple languages, extended time periods), this consistency gap is the difference between a reliable translation database and a collection of individually plausible but collectively inconsistent renderings.
Source: Lokalise Localization Trends Report (2025); Nimdzi Buyer Research (2025); MachineTranslation.com internal consistency benchmarks.
What the Key Term Translations panel gives researchers that no other feature does
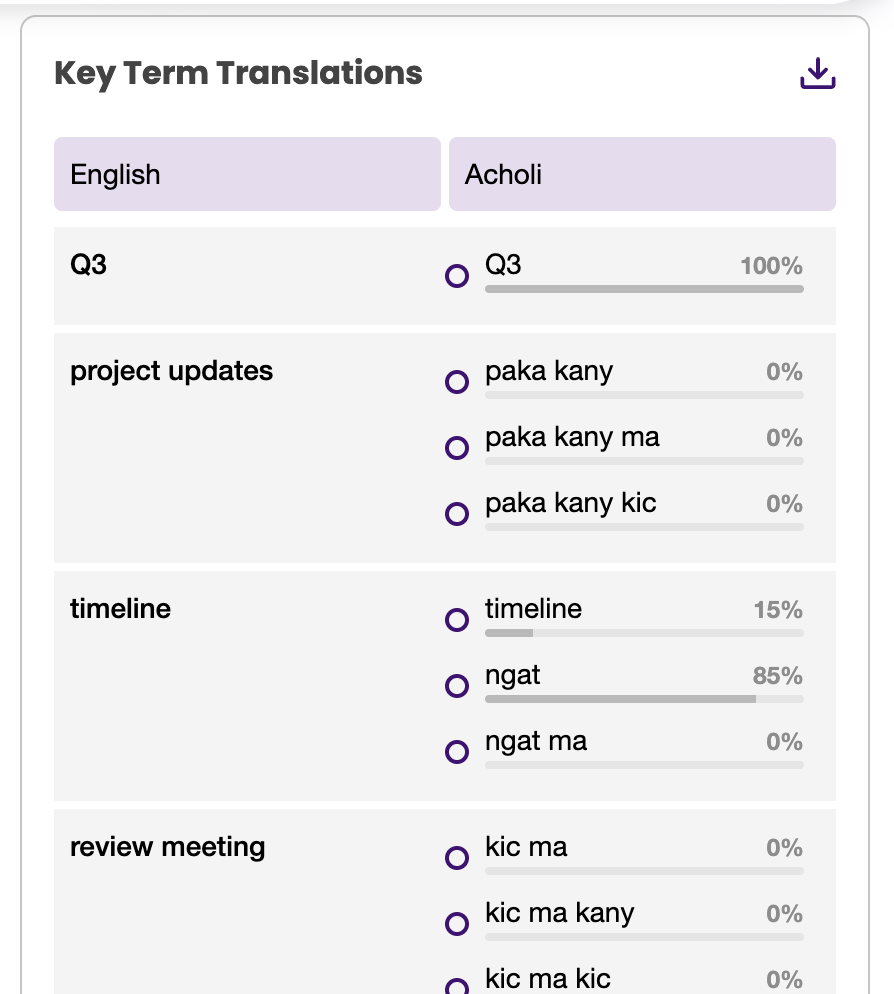
For academic use, the most underused feature in AI translation tools is not the primary translation output – it is the term-level confidence data that shows which renderings were uncontested and which were split decisions.
MachineTranslation.com's Key Term Translations panel shows every significant term in the source text alongside the percentage of the 22 models that agreed on each rendering. For a researcher working on a primary source, this panel is a map of the text's terminological complexity. Terms at 95%+ agreement can be used with confidence. Terms at 50/50 (the cases where the models genuinely disagreed) are the terms that require a scholar's attention before they appear in a published argument.
This is not a feature that replaces philological expertise. It is a feature that directs that expertise precisely where it is needed, rather than requiring it everywhere uniformly. A historian working through 400 pages of archival documents does not have the time to apply close philological attention to every word. The Key Term Translations panel identifies the 30 terms across those 400 pages that actually need it.
For survey researchers, this same panel identifies the scale items that produced cross-model disagreement (the constructs that even AI systems find semantically unstable) and flags them as candidates for back-translation review before the instrument is deployed. For clinical researchers, it surfaces the terminology where even top-tier AI models are unsure, which in a medical context is precisely the information needed to route a document to expert review.
The academic translation decision matrix: matching tool to task
Research task | Translation stakes | Recommended approach |
Foreign-language literature triage | Low – comprehension only | Single AI or SMART consensus; no additional review needed |
Identifying relevant passages in archival sources | Low-medium | SMART consensus; Key Term panel scan for flagged terms |
Translating sources for note-taking and reference | Medium | SMART consensus with Key Term panel review |
Translating primary sources for citation in argument | High – appears in published work | SMART consensus + expert review of all flagged terms |
Survey instrument translation (related language pairs) | High – measurement validity | SMART consensus + native speaker refinement + back-translation check |
Survey instrument translation (distant language pairs) | Very high | SMART consensus + expert review + back-translation required |
Clinical notes and internal research documentation | Medium | SMART consensus; human review for flagged technical terms |
Consent forms and regulatory submissions | Very high – patient safety | SMART consensus + human verification (ISO 18587:2017 certified) required |
Classical or archaic language primary sources | High | SMART consensus; human Latinist/specialist review for cited passages |
Theological texts with community-specific terminology | High – reputational stakes | SMART consensus + community expert review before publication |
A note on research integrity and citing AI-assisted translation
The use of AI tools in academic research has generated genuine debate about attribution, transparency, and integrity. For translation specifically, the relevant question is not whether AI was used (it almost certainly was, given current research practice), but whether its use was disclosed and its limitations acknowledged.
The emerging standard across most disciplines is to disclose AI-assisted translation in the methods section or notes, specify the tool used, and indicate the level of review applied to the AI output. A statement such as "Primary sources were translated using MachineTranslation.com's SMART consensus system (22-model consensus); all translated passages cited in argument were reviewed by [expert name/credentials]" provides the transparency that allows readers to evaluate the reliability of the translation evidence.
What academic integrity frameworks universally reject is the use of unreviewed AI translation for cited evidence, presenting a single model's confident output as a scholarly translation without acknowledgment or expert review. The combination of AI consensus translation and documented human review of cited passages satisfies both the efficiency demands of modern research and the evidentiary standards of scholarly publication.
FAQs
1. Is it acceptable to use AI translation in academic research?
Yes, with appropriate disclosure and review practices. AI translation is now standard for literature reading, source triage, and preliminary comprehension across most disciplines. For translation that appears in published arguments (cited sources, quoted primary material, survey instruments), AI output requires expert review before publication, and the use of AI tools should be disclosed in the methods or notes. The combination of consensus AI translation (which provides a stronger evidential basis than any single model) and documented expert review of cited passages meets the standards of scholarly practice.
2. What is the difference between using AI translation for reading versus for citing?
Reading-at-scale uses translation for comprehension and triage, determining what a source says and whether it is relevant. The standard is "close enough to proceed." Citing uses translation as scholarly evidence, the rendering must be exact enough to stand behind in an argument. Most academic translation problems arise from applying the reading standard to citation-quality work. SMART consensus translation raises the reliability floor for both, but human expert review remains appropriate for any passage that will be published as cited evidence.
3. How does consensus AI translation reduce the risk of terminology errors in research?
Single AI models produce confident output even when guessing, and the confidence signal is uniform regardless of accuracy. Consensus AI runs the same text through 22 independent models and returns the majority-agreed rendering. Where models agree strongly, the output is reliable. Where they split, the disagreement is shown explicitly – flagging the specific terms where scholarly judgment is required. This is structurally equivalent to inter-rater reliability in research methodology: high agreement signals reliability; disagreement surfaces where the measure needs refinement.
4. Should AI-translated survey instruments be back-translated?
Yes, as a standard practice for any survey being used in published research. Back-translation (translating the instrument from the target language back into the source language by an independent translator) identifies items where the forward translation introduced semantic drift, regardless of how fluent it appeared. AI consensus translation reduces the number of items that will fail back-translation review, but does not eliminate the need for the review itself. For distant language pairs or culturally loaded constructs, expert review of the original translation is also recommended before back-translation.
5. When does clinical translation require human verification rather than AI consensus?
Any clinical document with formal evidentiary status (patient consent forms, regulatory submissions, published trial protocols, diagnostic reports cited in a clinical record) requires human verification. Individual AI models carry a hallucination rate of 10-18% for translation tasks, and consensus AI reduces this to under 2%, but for documents where a remaining error creates patient safety risk or regulatory non-compliance, human verification is the appropriate additional step. MachineTranslation.com offers human verification within the same platform workflow, without requiring a separate agency.
6. How should AI-assisted translation be cited in academic work?
The emerging standard is transparency about tools and review level. Include in your methods or notes: the tool used (e.g., MachineTranslation.com SMART consensus system), the language pair, the review process applied (e.g., "all cited passages reviewed by [credentials]"), and any limitations applicable to the specific text type. Avoid presenting AI translation as equivalent to expert human translation without qualification, and avoid using AI output for cited evidence without any human review.