March 19, 2026
Kimi vs. DeepSeek: which is better for Chinese translation?
Kimi (Moonshot AI) and DeepSeek are two of the most capable large language models for Chinese. Both are developed by Chinese AI labs, both support Chinese as a primary language, and both have improved substantially in the past year — Kimi K2.5 was released in January 2026, and DeepSeek has been updated through V3.2. If you're translating Chinese into Korean, Spanish, English, or other languages, either is a plausible choice.
The question worth asking before you choose is not just which model is better in general. It's which model you can trust for the specific content you're sending out, and whether a single model's output is enough confidence for that purpose.
Chinese presents a particular challenge for this question. The language is highly context-dependent: word meaning shifts with position, register, and cultural reference. When two competent models translate the same Chinese sentence differently, both outputs can be linguistically plausible. Only knowing which one is right (or which is more likely right) gives you the confidence to send.
This article covers what Kimi and DeepSeek each bring to Chinese translation, where each one fits, and what to do when the stakes of getting it wrong are too high to rely on one model's judgment alone.
In this article
- What is Kimi?
- What is DeepSeek?
- How do they compare on Chinese translation quality?
- Which handles creative and marketing content better?
- Which handles legal and technical content better?
- How do their pricing and API access compare?
- How do both models handle Chinese ambiguity?
- FAQs
What is Kimi?
Kimi is an AI model series developed by Moonshot AI, a Chinese AI lab founded in 2023. The current version, Kimi K2.5, was released in January 2026. It uses a Mixture-of-Experts architecture with 1 trillion total parameters, of which 32 billion are active per request. Kimi K2.5 was trained natively on multimodal data (text, image, and video) from the ground up, rather than adding vision capabilities as a later addition. It supports a 256K-token context window and is available via Kimi.com, the Kimi mobile app, and the Moonshot AI API.
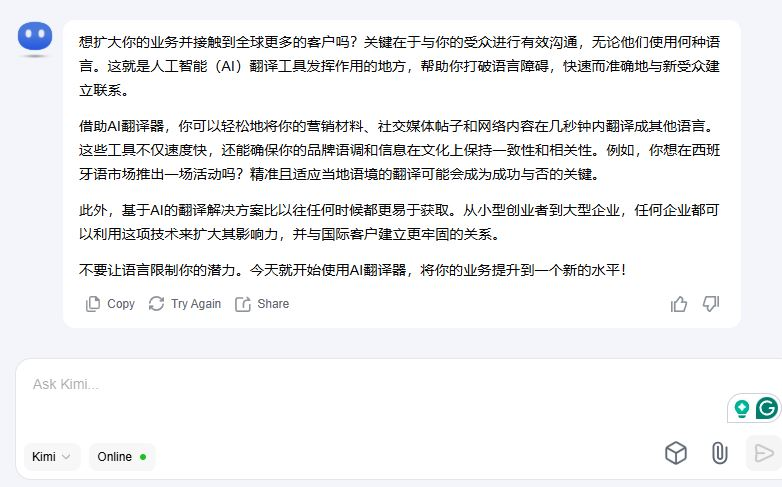
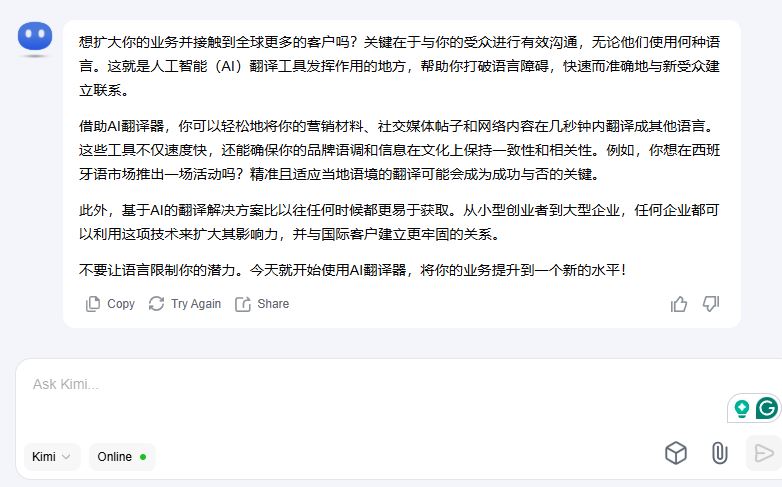
For translation, Kimi's primary strength lies in its deep multilingual training data, particularly for Chinese. It handles idiomatic expressions, culturally specific references, and tone-sensitive content (marketing copy, consumer communications, social content) with more flexibility than models that prioritise formal precision. Kimi K2.5's API is priced at $0.60 per million input tokens and $2.50 per million output tokens.
Moonshot is one of the 22 AI models running inside MachineTranslation.com's SMART consensus system, alongside DeepSeek, Google, OpenAI, Claude, and 17 other models.
What is DeepSeek?
DeepSeek is a large language model developed by DeepSeek AI, a Chinese research lab. The current version, DeepSeek V3 (updated through V3.2 in 2025–2026), uses a Mixture-of-Experts architecture with 671 billion total parameters and 37 billion active parameters per token. It is open-source, which allows self-hosting and custom deployment, and its API pricing is significantly below OpenAI equivalents.
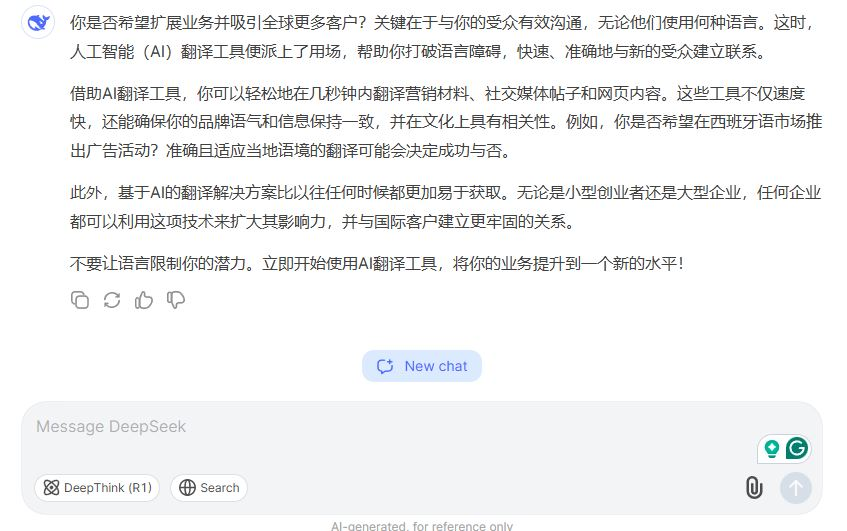
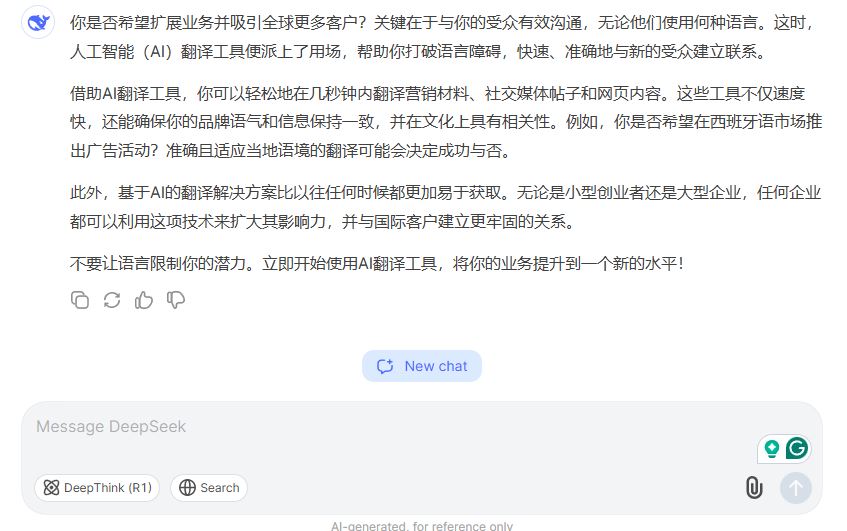
For Chinese translation specifically, DeepSeek V3 is one of the strongest single models available. Its multilingual training data is deep on Chinese-English pairs, and its MoE architecture handles long-context documents efficiently — an advantage for contracts, technical manuals, and research papers where coherence across many pages matters.
DeepSeek V3 is also one of the 22 models in MachineTranslation.com's SMART system. In internal benchmarking, individual top-tier LLMs including models of this tier score around 94.2 out of 100 on translation quality, while SMART's consensus output (aggregating 22 models including both Kimi and DeepSeek) achieves 98.5.
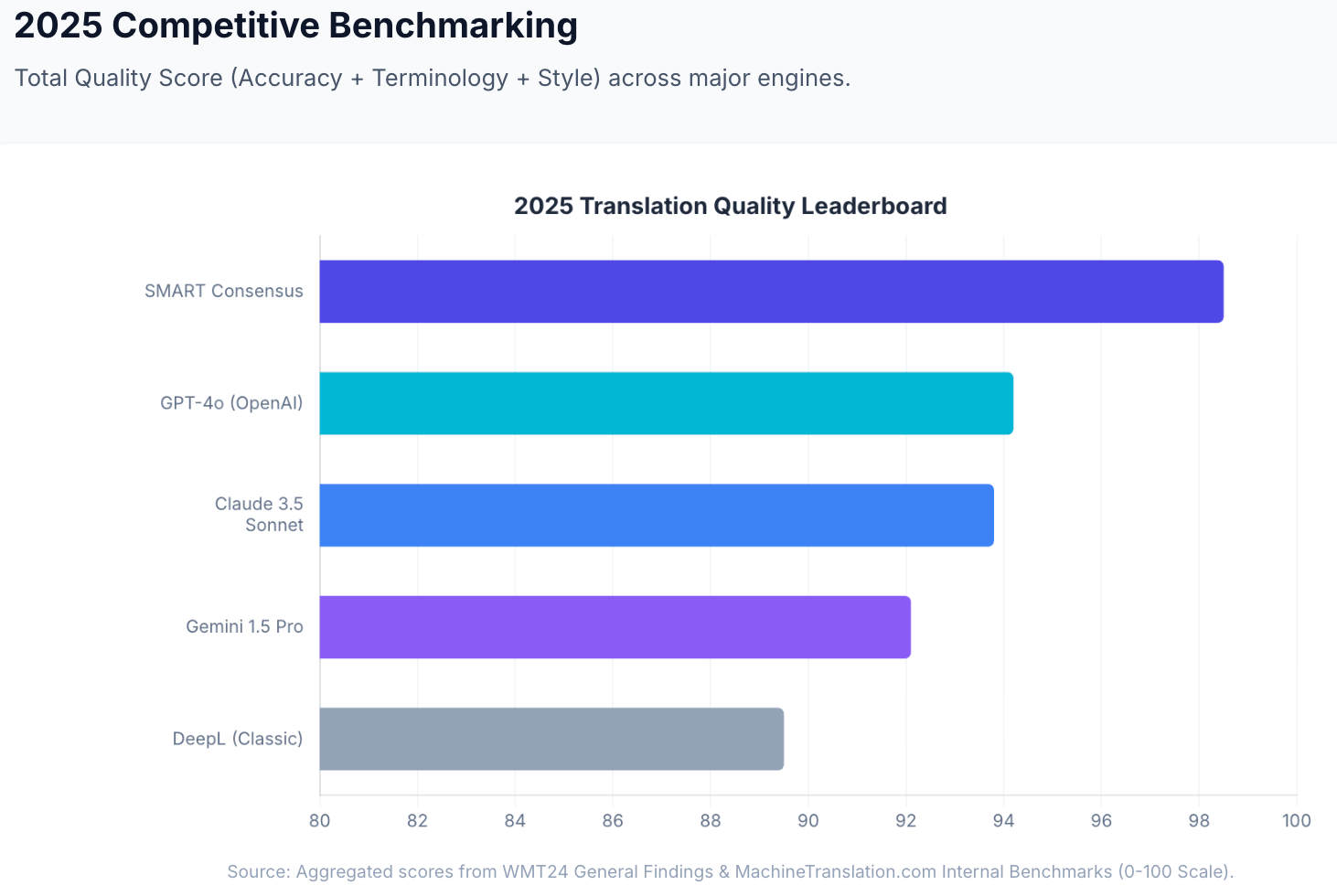
Source: MachineTranslation.com internal benchmarks and WMT24 General Machine Translation Findings.
How do they compare on Chinese translation quality?
Both Kimi and DeepSeek are well-trained on Chinese and produce high-quality output for most general-purpose tasks. The meaningful differences emerge at the edges: tone-sensitive content, culturally embedded expressions, and formal documents where register consistency matters.
Kimi is stronger on content where how something sounds in the target language matters as much as what it says. For Chinese-to-Korean translations involving idiomatic phrases (colloquial expressions, slang, culturally specific encouragement), Kimi tends to produce output that reads naturally rather than technically correct. It handles the ambiguity of Chinese contextual meaning by leaning toward culturally resonant equivalents.
DeepSeek V3 is stronger on content where terminological precision matters above naturalness. For Chinese-to-English or Chinese-to-Spanish translations of legal agreements, engineering documentation, or compliance materials, DeepSeek's output is more consistent in preserving formal register and specific terminology. Its long-context handling is an advantage for documents where terminology must remain consistent across many pages.
Neither tool verifies its own output. A plausible-sounding translation from either model can still be wrong — particularly in Chinese, where a single character shift can change meaning substantially. For a broader review of how AI translation tools hold up across tasks, see the best machine translation software.
| Kimi K2.5 | DeepSeek V3 | |
|---|---|---|
| Best for | Creative, marketing, idiomatic, consumer-facing content | Legal, technical, formal, long-document content |
| Chinese strength | Strong on Chinese idiom, tone, cultural nuance | Strong on Chinese-English precision, long-context coherence |
| Architecture | MoE, 1T params, 32B active | MoE, 671B params, 37B active |
| Context window | 256K tokens | 128K tokens |
| Open source | Yes | Yes |
Which handles creative and marketing content better?
For marketing copy, social media, branding, and any content where the target language needs to feel natural and emotionally resonant, Kimi K2.5's training depth on Chinese cultural context gives it an edge. Expressions that carry connotation in Chinese (idioms tied to cultural values, colloquial encouragement, brand-tone language) translate more fluidly with a model that understands the register being used, not just the words.
DeepSeek handles structured marketing content well (product descriptions with fixed terminology, investor presentations, brand guidelines with consistent phrasing) but its output can feel less natural in conversational or emotionally expressive contexts.
For campaigns, social content, and consumer-facing Chinese translations, Kimi is the stronger starting point. The caveat applies to both: even a strong single-model output should be verified before it goes to a client or goes live. MachineTranslation.com users who switched to SMART spent on average 27% less time checking and correcting outputs than those manually comparing single-model results, according to internal data. Source: MachineTranslation.com internal rollout data.
Which handles legal and technical content better?
For legal contracts, compliance filings, technical specifications, and regulated content, precision in Chinese translation carries real liability. Mistranslating a contractual term, a product safety label, or a regulatory clause is not a style error — it's a business or legal risk.
DeepSeek V3 handles formal Chinese translation well, particularly for Chinese-English pairs in legal and technical domains. Its long-context coherence means terminology introduced on page 1 of a document is likely to remain consistent on page 20. Its open-source architecture also means enterprises with data sovereignty requirements can self-host it rather than sending confidential content to third-party servers.
Kimi handles simpler legal and formal content adequately, but for highly complex or high-stakes legal documents, its tendency toward natural-sounding output can work against strict terminological precision.
For either tool, the risk profile in regulated content is the same: a single-model output carries no built-in verification. MachineTranslation.com's approach to this (running translations through 22 models simultaneously and selecting the consensus output) reduces critical translation errors to under 2% by catching model-specific errors before they reach the output. Source: Lokalise Localization Trends Report (2025) and MachineTranslation.com Industry Benchmarks.

For content where even consensus-level AI is not sufficient, Human Verification is available in-platform, providing a 100% accuracy guarantee from a certified professional reviewer, within the same workflow. See how this applies to English to Chinese translation.
How do their pricing and API access compare?
Both Kimi and DeepSeek are open-source and available via API at significantly lower rates than OpenAI equivalents.
Kimi K2.5 API pricing: $0.60 per million input tokens and $2.50 per million output tokens (Moonshot AI platform).
DeepSeek V3 API pricing is competitive and significantly below GPT-4o rates, though it varies by provider and deployment method. Self-hosted deployment is possible given its open-source availability.
MachineTranslation.com provides access to both Kimi and DeepSeek (alongside 20 other models). No sign-up is required to start. For high-volume translation, the 24-Hour Full Access plan is available at $9.50 for unlimited translations within a 24-hour window.
| Tool | Free access | API pricing |
|---|---|---|
| Kimi K2.5 | Kimi.com free tier | $0.60 / $2.50 per million tokens |
| DeepSeek V3 | Open-source; API varies by provider | Competitive; significantly below GPT-4o |
| MachineTranslation.com | Free plan, no sign-up required | 24-Hour Access $9.50 / monthly plan |
How do both models handle Chinese ambiguity?
Chinese is one of the most context-dependent major languages in the world. A single character can carry different meanings depending on its position in a sentence, the formality register, the implied speaker relationship, and cultural reference. When a single model translates a Chinese sentence, it makes a judgment call based on its training. That judgment is usually good, but it isn't verifiable from the output itself.
This is where the difference between single-model and multi-model translation becomes most visible for Chinese specifically. When Kimi and DeepSeek translate the same Chinese sentence and agree on the output, that agreement is a strong signal the translation is reliable. When they disagree (which happens more often for Chinese than for more structurally predictable languages), the disagreement tells you something important: this sentence warrants a closer look before you send it.
MachineTranslation.com's SMART system runs every translation through 22 AI models simultaneously (including both Kimi (Moonshot) and DeepSeek V3) and selects the output the majority agrees on. For Chinese translation, where ambiguity is structurally inherent in the source language, cross-model consensus is not just a quality mechanism. It's a way to catch the specific class of errors that fluent-sounding single-model output hides.
SMART reduces translation error risk by 90% through mathematical consensus. Both Kimi and DeepSeek are part of that system — meaning you get the benefit of both models' Chinese-language training, cross-checked against 20 others, in every translation.
If you need absolute certainty on a specific Chinese document (a contract clause, a regulatory filing, a public-facing campaign), Human Verification escalates the consensus output to a professional human reviewer within MachineTranslation.com's platform. No external agency. No separate vendor. The same workflow, 100% accuracy guaranteed.
Translate Chinese with 22 AI models checking each other at MachineTranslation.com — free, no sign-up required.
FAQs
1. Is Kimi or DeepSeek better for Chinese translation?
It depends on the content type. Kimi K2.5 is stronger for idiomatic, culturally sensitive, and consumer-facing Chinese translations where natural-sounding output matters. DeepSeek V3 is stronger for formal, legal, and technical Chinese translations where terminological precision and long-context coherence are more important than tone. For professional-grade output in either category, cross-checking both models against each other (and others) through a consensus system produces more reliable results than choosing one.
2. What is Kimi K2.5?
Kimi K2.5 is the latest model in Moonshot AI's Kimi series, released in January 2026. It is a 1 trillion parameter Mixture-of-Experts model with 32 billion active parameters per request, trained natively on 15 trillion visual and text tokens. It supports a 256K-token context window and is available via Kimi.com, the Kimi app, and the Moonshot AI API.
3. What version of DeepSeek should I use for Chinese translation?
DeepSeek V3 (updated through V3.2 in 2025–2026) is the current version for general-purpose and translation tasks. It is open-source and can be accessed via API or self-hosted. For Chinese-English pairs specifically, it is one of the strongest individual models available.
4. Can I use both Kimi and DeepSeek together for Chinese translation?
Yes, MachineTranslation.com includes both Moonshot (Kimi) and DeepSeek V3 among its 22 models. Every translation runs through all 22 models simultaneously and returns the consensus output, so you get the benefit of both models' Chinese-language training without having to compare them manually.
5. Is it safe to use Chinese-origin AI models for sensitive business content?
There are data sovereignty considerations with both Kimi (Moonshot AI) and DeepSeek, as both are Chinese-origin models and data sent to their servers may be subject to Chinese data security laws. For sensitive or confidential business content, enterprises should review each provider's data handling policies. MachineTranslation.com's platform terms cover data handling across all 22 models used. For the highest-sensitivity content, Human Verification with a professional human reviewer adds a further layer of control.
6. How accurate is AI translation for Chinese?
For general-purpose content, top-tier AI models produce high-quality Chinese translations. In internal benchmarking, individual top-tier LLMs score around 94.2 out of 100 on translation quality. SMART (which aggregates 22 models including both Kimi and DeepSeek) achieves 98.5. Chinese is a particularly context-dependent language, which means disagreement between models is more common than for many other languages, and cross-model consensus is a more meaningful quality signal. Source: MachineTranslation.com internal benchmarks and WMT24 General Machine Translation Findings.
7. Do I need to choose between Kimi and DeepSeek for Chinese translation?
No. MachineTranslation.com runs both (and 20 other models) simultaneously for every translation. Rather than picking one and hoping it handles your specific content well, SMART selects the output most models agree on. For Chinese content specifically, where even small contextual differences in the source can produce meaningfully different translations, consensus-based selection is more reliable than any single model's judgment.

By Clarriza Heruela
Clarriza Mae Heruela graduated from the University of the Philippines Mindanao with a Bachelor of Arts degree in English, majoring in Creative Writing. Her experience from growing up in a multilingually diverse household has influenced her career and writing style. She is still exploring her writing path and is always on the lookout for interesting topics that pique her interest.
Share: