June 5, 2026
Same AI, different model — and the translations couldn't be more different
I've been running internal tests on something we don't talk about enough in the translation industry: not whether different AI systems translate differently, but whether different versions of the same AI translate differently — and by how much.
Last week I ran a single Spanish idiom through five versions of ChatGPT simultaneously on MachineTranslation.com's internal testing platform. What came back stopped me.
Two versions produced a translation that is, genuinely, nonsense in English. Three versions produced correct idiomatic translations. And the three correct ones didn't agree with each other.
All five are ChatGPT. All five are OpenAI. Same AI, different model — and the outputs couldn't be more different.
I'm sharing this now because I think it matters, not because I have clean answers. I don't. But the observation is interesting enough to put into the world.
Table of contents
- The test: One Spanish idiom, five GPT versions
- Why this idiom makes a good test case
- What the literal-to-idiomatic split tells us about how these models were trained
- The implication that nobody seems to be talking about
- Even the "correct" translations disagreed with each other
- What I don't know yet
- Two research questions worth sitting with
The test: One Spanish idiom, five GPT versions
The phrase I tested was llevarse el gato al agua.
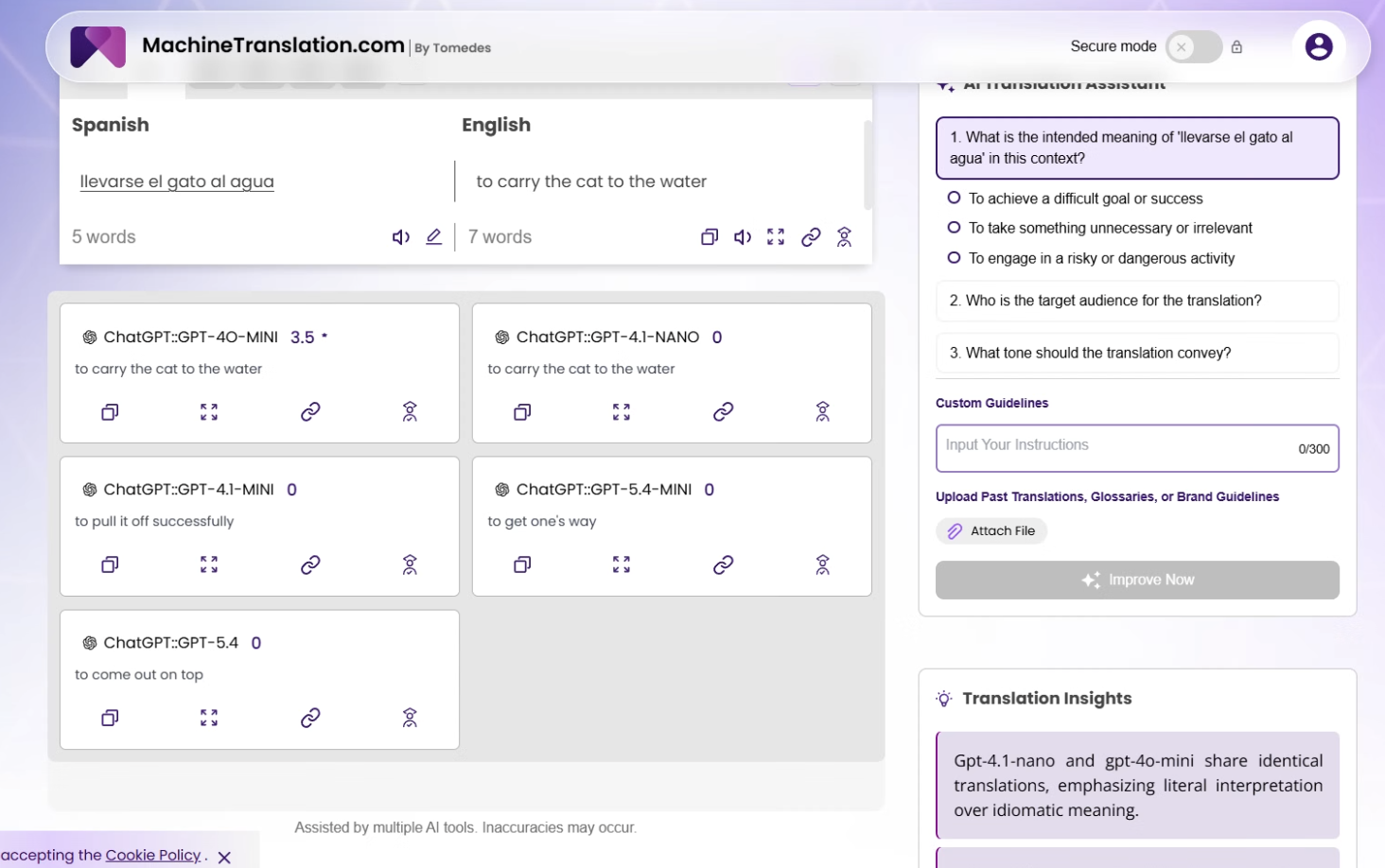
Here is what each version produced:
| Model | Output | Idiomatic? |
|---|---|---|
| ChatGPT::GPT-4o-MINI | "to carry the cat to the water" | ❌ Literal |
| ChatGPT::GPT-4.1-NANO | "to carry the cat to the water" | ❌ Literal |
| ChatGPT::GPT-4.1-MINI | "to pull it off successfully" | ✅ Correct |
| ChatGPT::GPT-5.4-MINI | "to get one's way" | ✅ Partial |
| ChatGPT::GPT-5.4 | "to come out on top" | ✅ Correct |
The phrase means to achieve something difficult against the odds, to pull off a hard win. It has nothing to do with cats or water. The literal translation is not a translation. It is a word-by-word transcription of a phrase the model failed to recognise as an idiom.
GPT-4o-MINI and GPT-4.1-NANO produced identical outputs. Not similar, identical. Our Translation Insights flagged this directly: "GPT-4.1-nano and GPT-4o-mini share identical translations, emphasizing literal interpretation over idiomatic meaning."
GPT-4.1-MINI, GPT-5.4-MINI, and GPT-5.4 each produced something recognisably correct — but not the same as each other.
Why this idiom makes a good test case
I want to be precise about why llevarse el gato al agua is a useful test input rather than a cherry-picked one.
It is a well-established idiom. It appears in literature, journalism, and everyday speech. It is not obscure. Any model trained on a reasonable corpus of Spanish text should have encountered it. The question is not whether the model has seen the phrase. The question is what it does with it.
The worst failure mode in idiom translation is not producing a bad translation. It is producing a literal translation that looks acceptable to someone who doesn't know the target language.
"To carry the cat to the water" is grammatically correct English. It is well-formed. It sounds like something that could mean something. A user who doesn't speak Spanish might read it, nod, and move on — never knowing the original meaning was lost entirely.
That is the failure mode I care about. Not the obvious error. The invisible one.
What the literal-to-idiomatic split tells us about how these models were trained
The pattern here is not random. The two models that produced literal translations (GPT-4o-MINI and GPT-4.1-NANO) are both smaller, lighter models optimised for speed and cost efficiency. The three models that produced idiomatic translations (GPT-4.1-MINI, GPT-5.4-MINI, GPT-5.4) represent a different generation or parameter scale.
This suggests something that I think is underexplored: idiomatic competence in translation scales with model capacity in ways that are not visible in general benchmarks.
General language benchmarks test reasoning, knowledge, coding, mathematics. They do not typically test whether a model can identify that it's raining cats and dogs is not about weather conditions, or that llevarse el gato al agua is not about hydrating a cat. Idioms sit at the intersection of cultural knowledge, contextual inference, and pattern recognition — and that intersection seems to require a threshold of model capacity that smaller models don't consistently clear.
What I'm not claiming: that larger models are always better translators. I don't have evidence for that as a general rule. What I am observing: that for idiomatic content specifically, the within-family version gap was larger than I expected.
The implication that nobody seems to be talking about
Most users who use an AI translation tool don't know which version of that AI they're using. They open a product, select a language pair, and get an output. The model routing is invisible to them.
This matters at scale. MachineTranslation.com processed over hundreds of thousands of English-to-Spanish translation jobs in a single 90-day period. If a significant portion of those jobs touched idiomatic content (marketing copy, legal language, literary text, casual communication) and the tool routing those jobs was directing users to a smaller model without their knowledge, then "to carry the cat to the water" was appearing in real outputs, in real documents, for real people who trusted the result.
The translation industry has spent years comparing AI providers. DeepL versus Google. Claude versus ChatGPT. Those comparisons are useful. But within a single provider, the version gap may be just as significant — and it's a gap that most comparison frameworks don't measure because they don't test at the model-version level.
When someone says "I use ChatGPT for translation," that sentence is not specific enough to be meaningful. Which ChatGPT? Nano? 4o-mini? 4.1-mini? 5.4? The answer changes the output in ways that are non-trivial, at least for idiomatic content.
Even the "correct" translations disagreed with each other
This is the part I find most interesting, and I haven't fully worked out what to make of it yet.
The three models that produced idiomatic translations gave three different ones:
- GPT-4.1-MINI: "to pull it off successfully"
- GPT-5.4-MINI: "to get one's way"
- GPT-5.4: "to come out on top"
All three are defensible English renderings of llevarse el gato al agua. But they are not equivalent.
"To pull it off" emphasises execution against difficulty, you did something hard and it worked. "To get one's way" emphasises the outcome you wanted being achieved, with less emphasis on the difficulty. "To come out on top" emphasises competitive victory, winning relative to others.
The original Spanish idiom sits closest to the first of these. The phrase carries the connotation of overcoming resistance, not simply preferring one outcome and having it materialise. But "to get one's way" and "to come out on top" are not wrong, they are just imprecise in different directions.
This raises a question I find genuinely difficult: when three models each produce a correct but distinct idiomatic translation, how do you evaluate which is best? BLEU scores compare against a reference translation — but who wrote the reference, and which of these three would they have chosen?
Our AI Translation Agent, to its credit, asked the right question before committing to any output: What is the intended meaning of 'llevarse el gato al agua' in this context? Three options were offered — to achieve a difficult goal, to take something unnecessary, or to engage in a risky activity. That question is not decorative. It is the mechanism by which the contextual ambiguity gets resolved before the translation is finalised.
But the point stands: three correct answers, three different shades of meaning. Translation evaluation tools are not built for this kind of nuance.
What I don't know yet
I want to be honest about the limits of what this test shows.
One idiom, one language pair, one day of internal testing. That is not a study. It is an observation. I don't know whether this pattern (smaller models defaulting to literal, larger models achieving idiomatic) holds consistently across:
- Other Spanish idioms
- Other language pairs with rich idiomatic traditions (Arabic, Japanese, Russian all come to mind)
- Non-idiomatic content where the distinction doesn't apply
- Edge cases where a smaller model gets the idiom right and a larger one misses it
I also don't know whether this is a stable property of these models or something that shifts with updates and fine-tuning. Model providers don't publish translation-specific changelogs. A model version that handles llevarse el gato al agua correctly today might be updated next month, and we'd have no way of knowing.
What I do know: this test produced a result interesting enough that I want to run more of them, more systematically, across more language pairs and content types. When I have more to share, I will.
Two research questions worth sitting with
I'll close with the two questions this test left me with. I'm not going to answer them, I don't have the data to do that yet. But I think they're the right questions to ask.
First: at what parameter threshold does idiomatic competence become reliable?
The jump from GPT-4o-MINI and GPT-4.1-NANO (both literal) to GPT-4.1-MINI (idiomatic) suggests there is a threshold somewhere in the parameter range between those model sizes where idiom recognition turns on. Is it consistent? Does it apply to idioms across all languages, or does it depend on how well-represented a language is in the training data? I don't know. But knowing would be useful for anyone building translation workflows.
Second: what does model version opacity cost users at scale?
If a user routes 1,000 documents per month through a tool that doesn't disclose which model version is being used (and some of those documents contain idiomatic content), how often is the literal failure happening invisibly? How would they know? What is the cost, in real terms, of never finding out?
I think this is a more important question than most of the "which AI is best for translation" comparisons currently circulating. The answer is not "use the biggest model." The answer might be: know what you're using, run your own tests on your own content, and don't assume that one provider's name is a guarantee of consistent behaviour across their model range.
That is, at least, what I'm taking from this test.
Research questions
1. Does model size reliably predict idiomatic translation quality?
Based on this single test: smaller, efficiency-optimised models within the same AI family defaulted to literal translation of a well-established Spanish idiom, while larger/newer versions of the same model produced correct idiomatic renderings. Whether this holds across idiom categories and language pairs is the next question. I'll run more tests.
2. Why did three "correct" idiomatic translations produce three meaningfully different outputs?
GPT-4.1-MINI, GPT-5.4-MINI, and GPT-5.4 all translated llevarse el gato al agua idiomatically — but into different English expressions with subtly different connotations. This suggests that idiomatic translation quality has at least two dimensions: whether the model recognises the idiom at all, and which equivalent expression it selects from the target language's available options. Standard translation quality metrics don't cleanly separate these two dimensions. I think they should.
This post is based on internal testing on MachineTranslation.com's development platform. The multi-model version testing shown here is not yet publicly available. I'm sharing the finding because I think the observation is useful regardless of where you run your translations.

By Ofer Tirosh
Connect on LinkedInOfer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
Share: