April 10, 2026
LLM time to first token for translation: MachineTranslation.com benchmark
MachineTranslation.com measures Time to First Token (TTFT) across the AI models available on the platform as part of ongoing performance monitoring. This benchmark (covering 10 models currently active in MachineTranslation.com) gives a direct picture of how long each model takes to start responding, and what that means for translation workflows.
This article explains what TTFT means for translation specifically, presents the current benchmark data, and covers how latency should factor into model selection for different use cases.
In this article
- What is Time to First Token (TTFT)?
- LLMs ranked by TTFT: MachineTranslation.com benchmark
- What affects TTFT in translation tasks?
- Why speed alone doesn't determine translation quality
- How SMART handles latency across 22 models
- Frequently asked questions
What is Time to First Token (TTFT)?
Time to First Token measures how long an AI model takes to produce the first output token (the first word or character) after receiving a prompt. It is one of the primary latency metrics used to evaluate LLM responsiveness.
For translation specifically, TTFT matters differently depending on the use case:
Real-time and conversational translation — live customer support chat, real-time speech translation, messaging integrations — feels TTFT directly. A high TTFT creates a visible pause before any output appears, which affects perceived responsiveness in interactive contexts.
Document translation — contracts, technical manuals, product catalogs — is more sensitive to total generation time than to TTFT alone. Whether the first token appears in 0.2 seconds or 0.8 seconds is less consequential when the full document takes considerably longer to process.
API and batch translation workflows — where translation runs inside a product or automated pipeline — typically optimizes for throughput rather than TTFT, since no user is waiting in real time.
Understanding which metric applies to your use case helps you read the benchmark data below productively.
LLMs ranked by TTFT: MachineTranslation.com benchmark
The following data reflects MachineTranslation.com's internal TTFT measurements across AI models currently active in the MachineTranslation.com system. Models without confirmed TTFT data are not included.
Source: MachineTranslation.com internal TTFT measurement study.
AI models on MachineTranslation.com ranked by TTFT (fastest to slowest)
| Rank | Model (SMART name) | TTFT (seconds) | Notes |
|---|---|---|---|
| 1 | Gemini | 0.15–0.40 s | Highly optimized for speed, leveraging Google's TPU infrastructure |
| 2 | ChatGPT | 0.20–0.50 s | Optimized for low latency, especially in API deployments |
| 3 | DeepSeek | 0.20–0.50 s | Optimized for low latency and high efficiency in multilingual tasks |
| 4 | Claude | 0.25–0.55 s | Strong multilingual support with competitive latency |
| 5 | Qwen | 0.30–0.70 s | Competitive latency, optimized for Chinese and multilingual tasks |
| 6 | AI21 | 0.40–0.70 s | Optimized for enterprise use, moderate latency |
| 7 | Grok | 0.40–0.80 s | Improving across model generations; current versions faster than early releases |
| 8 | Mistral AI | 0.40–0.80 s | Lightweight and efficient; latency varies with deployment setup |
| 9 | GLM | 0.40–0.80 s | Strong on Chinese and multilingual tasks; latency depends on deployment |
| 10 | Llama | 0.50–1.00 s | Open-source model; latency depends on deployment hardware |
The remaining 12 models available in MachineTranslation.com (Amazon, Amazon Nova, DeepL, Facebook, Google, LibreTranslate, Lingvanex, Microsoft, Modern MT, Moonshot, Niutrans, Royalflush) are not included in this table pending TTFT measurement data.
What affects TTFT in translation tasks?
Several factors determine how quickly a model produces its first output token:
Model size and architecture. Larger models generally have higher TTFT due to greater computational load per forward pass. Mixture-of-Experts architectures (used by DeepSeek and Mistral AI) reduce active parameter load while maintaining high total parameter counts, which helps latency without sacrificing capability.
Infrastructure and hardware. Models running on optimized cloud infrastructure consistently achieve lower TTFT. Google's TPU cluster and OpenAI's managed API deployment place Gemini and ChatGPT at the top of the rankings regardless of model size. Open-source models like Llama show more variable TTFT depending on deployment hardware and serving configuration.
Language pair complexity. Translating between structurally similar languages (Spanish to Portuguese) involves less structural transformation than translating between very different languages, such as English to Japanese. More complex pairs require additional processing before the model can begin generating output, which can increase TTFT slightly.
Context length. Models processing longer context windows for document coherence may show higher TTFT for the first translation pass. For long documents where full-context processing improves terminology consistency, this trade-off is generally worth it.
API vs. self-hosted deployment. Models accessed via managed APIs (ChatGPT, Claude, Gemini) benefit from infrastructure optimization at the provider level. Open-source models deployed by teams themselves (Llama, Mistral AI) show latency that varies with the hardware and serving setup used.
Why speed alone doesn't determine translation quality
The TTFT rankings above measure one dimension of model performance. For translation specifically, speed is often the least consequential factor once a basic threshold is met.
Contextual vs. literal translation. Models that prioritize speed by mapping tokens directly may sacrifice the contextual understanding needed for accurate output. A phrase like "kick the bucket" needs to render as its meaning ("pass away") in the target language, not as a literal word-for-word equivalent that confuses native speakers. This contextual reasoning takes slightly longer and produces substantially better results.
Industry-specific terminology. Legal, medical, and technical translation requires precision that generic fast-output models can sacrifice. A medical translation error (a drug dosage, a contraindication) has consequences that far outweigh the seconds saved by a faster model. In these domains, TTFT is not a meaningful selection criterion. Accuracy and verification are.
Structural complexity of the target language. German, Japanese, and Finnish, among others, require more contextual processing to produce natural output. A model optimized for TTFT that begins generating immediately may produce early tokens that require correction as the sentence structure develops, increasing post-editing time and negating the speed gain.
The practical implication: for real-time conversational translation, TTFT is a valid and useful selection criterion. For professional document translation, the time spent correcting a fast model's errors typically exceeds the time saved by lower TTFT. Matching the model to the use case (rather than optimizing for TTFT across all scenarios) produces better outcomes.
How SMART handles latency across 22 models
MachineTranslation.com's SMART system runs 22 AI models simultaneously for every translation (including all 10 models measured above) and returns the output the majority agree on.
A common question is whether running 22 models multiplies the wait time. It does not.
SMART uses parallel execution: all 22 models process the same input at the same time. The total wall-clock time is determined by the slowest model in the batch, not the sum of all 22. Based on the benchmark data above, the slowest confirmed model (Llama) sits at 0.50–1.00 seconds TTFT — meaning the full 22-model consensus result begins arriving within approximately 1 second on standard text.
What this means in practice: instead of waiting for one model's output with no way to verify it, you receive the translation that 22 models agreed on (cross-checked, with a quality score showing how confident that consensus was) in approximately the same time as a single LLM call.
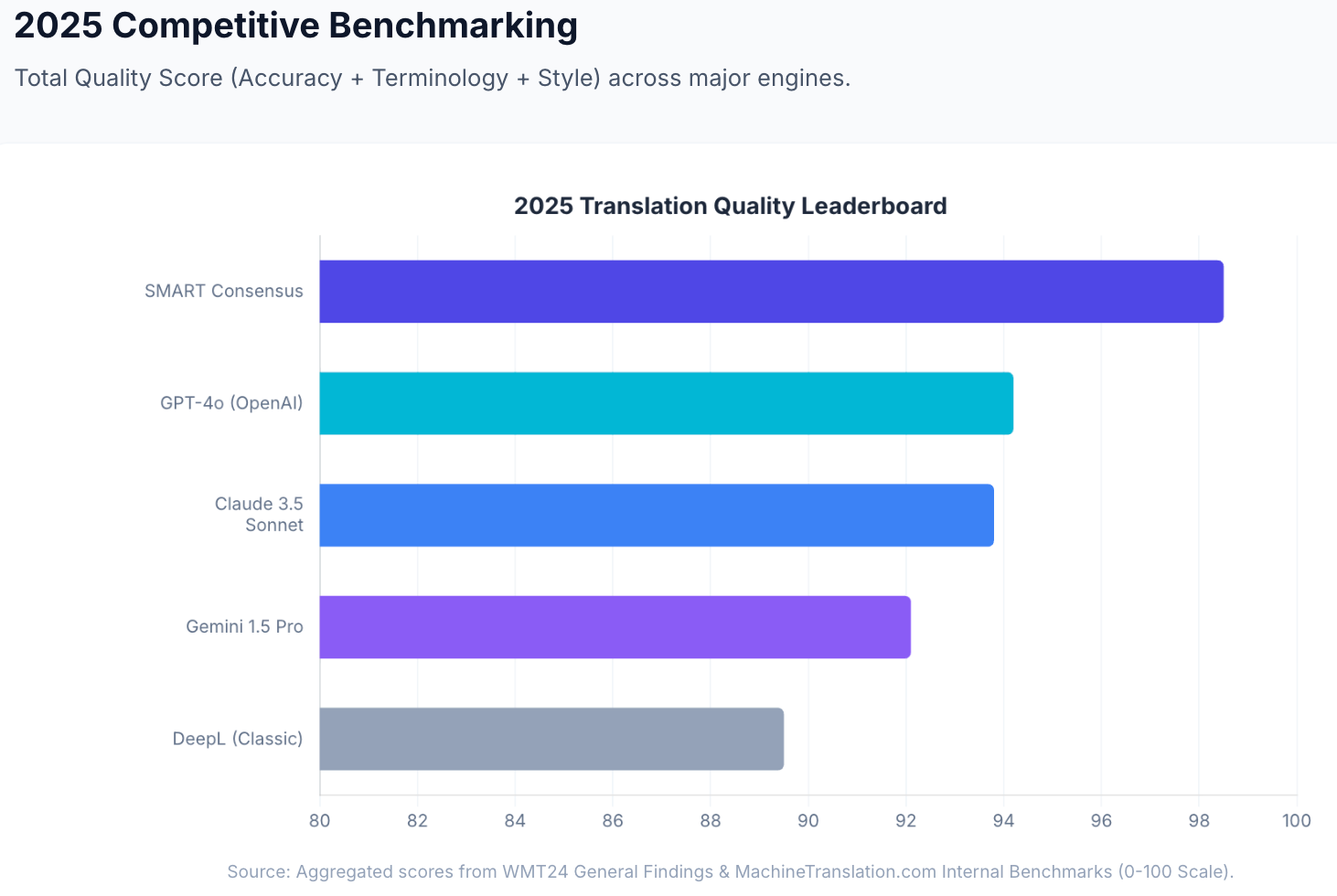
In MachineTranslation.com's internal benchmarks, individual top-tier models score 93–94 out of 100 on translation quality. SMART's consensus output reaches 98.5/100. The quality gain comes with no meaningful latency penalty relative to using a single model. Source: MachineTranslation.com internal benchmarks and WMT24 General Machine Translation Findings.
Users who switched from single-model use to SMART spent 27% less time verifying and correcting outputs, meaning the post-translation time savings consistently outweigh any perceived latency difference. Source: MachineTranslation.com internal data.
For high-stakes content (legal filings, clinical documentation, regulatory submissions), Human Verification escalates the consensus output to a certified professional reviewer within the same platform. No external vendor, 100% accuracy guaranteed.
Translate with 22 AI models at MachineTranslation.com — free, no sign-up required.
FAQs
1. What is Time to First Token (TTFT) in AI translation?
TTFT measures the time between sending a request to an AI model and receiving the first output token, the first character of the response. For translation, TTFT is most relevant for real-time and interactive use cases. For document translation, total generation time and throughput are typically more important metrics than TTFT alone.
2. Which model on MachineTranslation.com has the lowest TTFT?
According to MachineTranslation.com's internal measurements, Gemini achieves the lowest measured TTFT at 0.15–0.40 seconds, followed by ChatGPT and DeepSeek at 0.20–0.50 seconds each. These results reflect the optimized infrastructure behind Google's TPU-based deployment and OpenAI's managed API respectively.
3. Does a lower TTFT mean better translation quality?
No. TTFT measures responsiveness, not accuracy. Several of the highest-TTFT models in the benchmark are among the strongest performers on translation quality. Translation quality depends on contextual understanding, terminological precision, and language pair depth — none of which correlate directly with TTFT. For professional translation use cases, accuracy and output certainty matter far more.
4. Does running 22 models in SMART mean waiting 22 times longer?
No. SMART runs all 22 models in parallel, not in sequence. The total wait time is determined by the slowest model in the batch (approximately 0.50–1.00 seconds based on the confirmed benchmark data) not the sum of all model response times. The practical latency of SMART is equivalent to a single call to the slowest model in the set.
5. When does TTFT actually matter for translation?
TTFT matters most for genuinely real-time applications: live customer support chat, speech translation interfaces, and interactive translation tools where a user is actively waiting for a response. For document translation, API batch processing, and professional workflows where a complete output is needed before review, total generation time and throughput are more relevant metrics than TTFT.
6. Why do some AI models not appear in the TTFT table?
MachineTranslation.com currently has TTFT measurement data for 10 of the 22 models in it. The remaining 12 models (Amazon, Amazon Nova, DeepL, Facebook, Google, LibreTranslate, Lingvanex, Microsoft, Modern MT, Moonshot, Niutrans, and Royalflush) are not included pending formal measurement. The table will be updated as data becomes available.