June 5, 2026
Why "accurate" is the most searched word in AI translation, and what it actually means for your language pair
Every month, more than 250,000 people search some version of the same question. Translate Tagalog to English accurate. Spanish to English accurate. Accurate translator. The word appears in dozens of high-volume queries, typed by people who are not looking for a translation tool — they already know those exist. They are looking for confidence. They want to know whether the tool they are about to use will get it right for their specific language, their specific content, their specific stakes.
Almost none of them find an answer. They land on tool landing pages, comparison listicles, or generic posts about BLEU scores. The actual question (is this accurate for what I need?) goes unanswered.
This post answers it. Not with a quality assurance framework or a definition of post-editing, but with live results from MachineTranslation.com's platform: real language pairs, real documents, real engine disagreements, and what each of them reveals about what "accurate" actually means in practice.
Table of contents
- What people are really asking when they search "accurate translation"
- Accuracy is not a yes or no, what live testing actually shows
- How "under review" in Tagalog exposed a hidden accuracy dimension
- What "as soon as possible" in Spanish revealed about grammatical accuracy
- Why document-scale accuracy is a different problem from phrase accuracy
- How to actually test whether a tool is accurate for your language pair
- FAQ
What people are really asking when they search "accurate translation"
The query "translate Tagalog to English accurate" generates 69,196 impressions a month on Google. "Spanish to English accurate" generates 51,336. Together, the broader cluster of accuracy-intent translation queries produces more than 250,000 monthly impressions — and the click rates across that cluster are nearly zero.
That gap between impressions and clicks is not a technical problem. It is a content problem. The pages that rank for these queries are not answering the question being asked.
"When someone searches 'accurate translator,' they are not asking for a feature list," says William, CMO at Tomedes (the translation company that developed MachineTranslation.com). "They are asking: 'I have something important to translate, and I've been let down before. Can I trust this?' That's a completely different question, and most of the industry hasn't bothered to answer it."
What makes it difficult to answer is that accuracy in translation is not a single, stable property. It is not a score that a tool either has or doesn't. It is a relationship between the source language, the target language, the type of content, and the context in which the translation will be used. Understanding that relationship (for your specific pair, your specific content) is what this post is actually about.
Accuracy is not a yes or no, what live testing actually shows
The cleanest way to understand why "accurate" resists a simple answer is to watch what happens when multiple AI models translate the same input simultaneously.
The Arabic proof: Two correct answers, one register decision
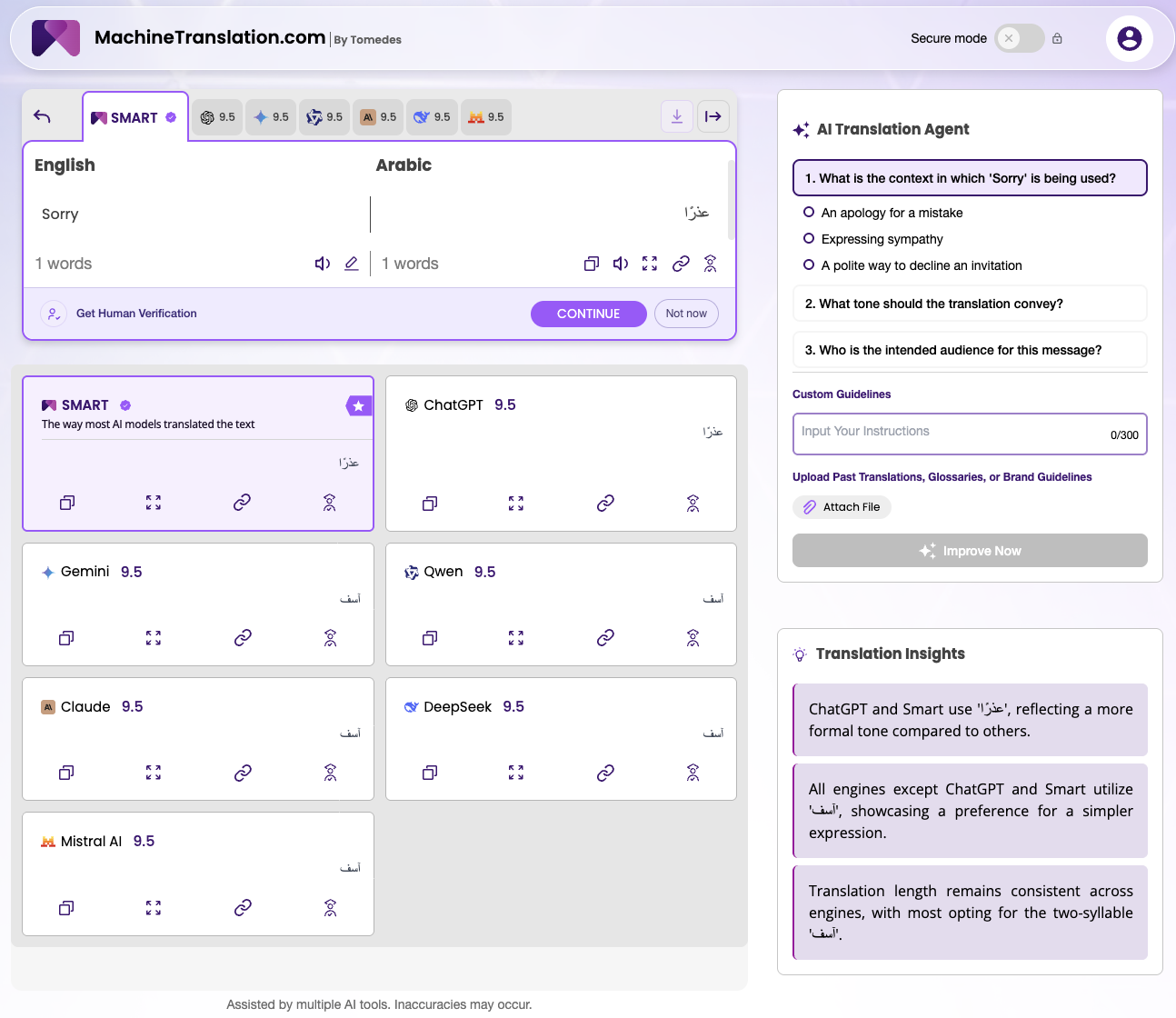
When MachineTranslation.com ran "sorry" through its multi-model platform, the models split almost evenly. SMART and ChatGPT produced عذرًا — the formal, literary Arabic expression used in written correspondence and professional apologies. Gemini, Qwen, Claude, DeepSeek, and Mistral produced آسف — the everyday spoken form used in most real-world interactions. Every model scored 9.5. No model was wrong.
The Arabic word for "sorry" is a register decision, not a lookup. عذرًا belongs in a formal written apology; آسف belongs in a conversation. Neither is more accurate in the abstract. Each is more accurate in a specific context, and context is what the source text alone cannot provide.
"The 'sorry' result is not a failure of the models that chose آسف," says Rachelle, AI Lead at Tomedes. "It's evidence that the phrase carries genuine register weight that English doesn't encode. Five models read it one way, two read it another — both readings are linguistically valid. Showing that split is more useful than hiding it behind a single output that presents one interpretation as the answer."
This is what MachineTranslation.com's verified translation of "sorry" in Arabic documents in full. It is also the clearest illustration of why accuracy, for Arabic, is inseparable from formality level. For the full breakdown of how عذرًا and آسف differ and when to use each, see the verified translation of sorry in Arabic.
Tagalog at document scale: Five models, five different scores
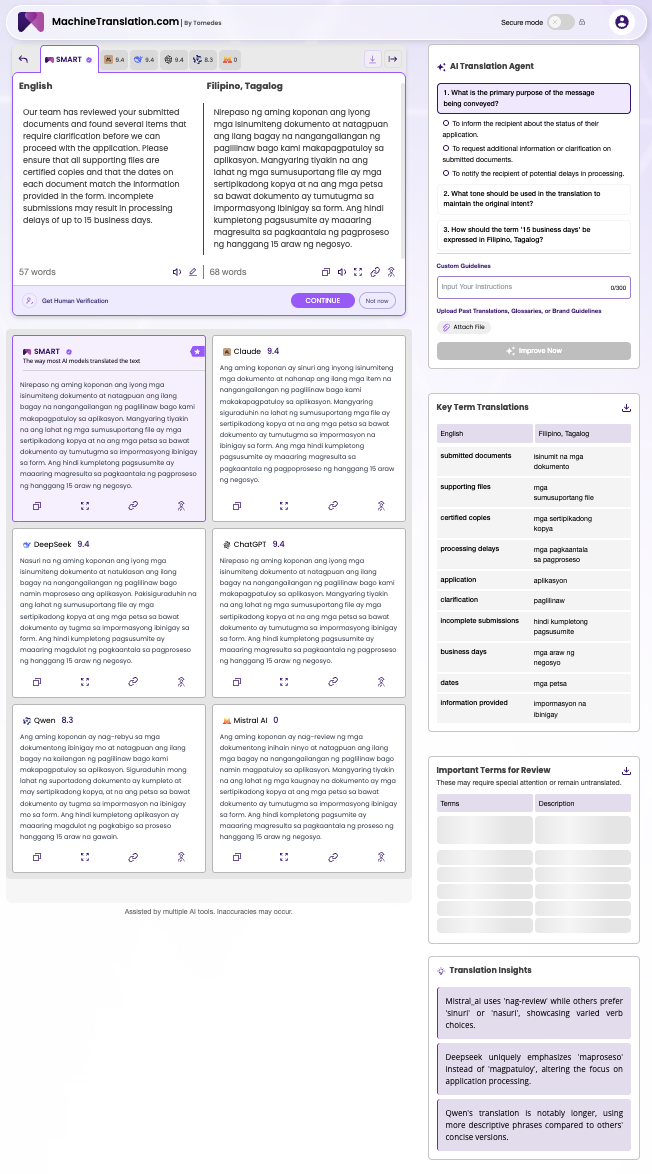
A single paragraph (57 English words about document review, certified copies, and processing delays) produced a range of scores across MachineTranslation.com's models: Claude, DeepSeek, and ChatGPT at 9.4; Qwen at 8.3; Mistral at 0.
The differences between the 9.4 outputs are subtle but real. MachineTranslation.com's Translation Insights flagged that Mistral used nag-review (a direct anglicisation of the English word) while other engines chose sinuri or nasuri, Filipino verbs that carry the same meaning without borrowing the English term. DeepSeek reframed the action as maproseso (to be processed) rather than magpatuloy (to proceed), subtly shifting the emphasis from continuation to completion. Qwen produced a longer, more descriptive output where others were concise.
These are not errors in the traditional sense. They are translation choices — and for a document going to a government agency, a legal authority, or an institutional recipient, the choice between sinuri and nag-review is a professionalism signal, not a stylistic one. The MachineTranslation.com Key Term Translations panel automatically extracted and mapped every operative term in the paragraph (certified copies to mga sertipikadong kopya, processing delays to mga pagkaantala sa pagproseso, business days to mga araw ng negosyo) giving document users a consistency layer that phrase-level accuracy alone cannot provide.
How "under review" in Tagalog exposed a hidden accuracy dimension
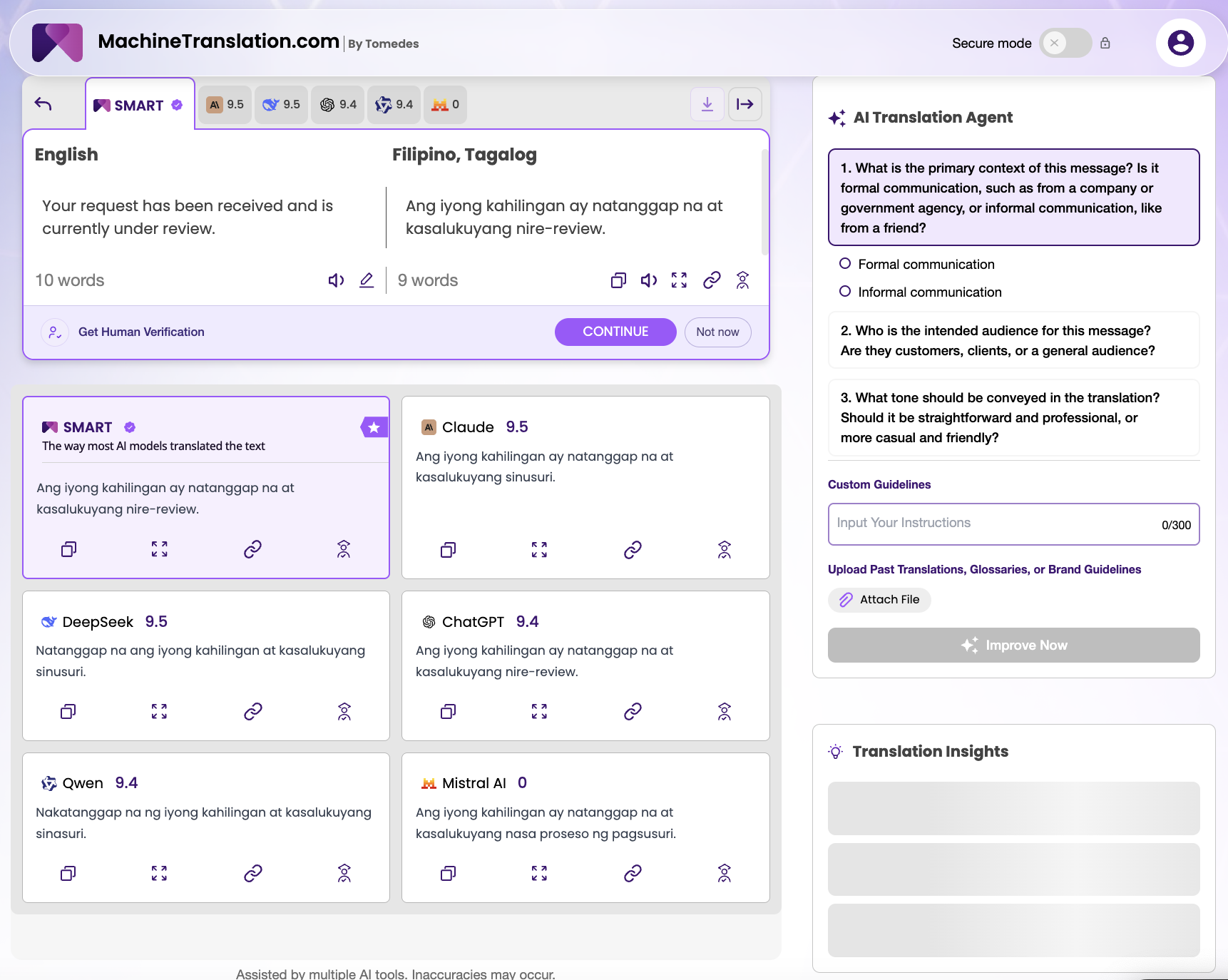
A shorter test revealed something the document paragraph could not: accuracy in Tagalog has a dimension that most tools don't surface at all.
The phrase "currently under review" produced three meaningfully different Tagalog renderings. Claude and DeepSeek chose sinusuri — a Filipino verb meaning to examine or scrutinise, with a formal, institutional tone. ChatGPT kept nire-review, an anglicism that Filipino speakers use in casual and professional digital communication but that signals a less formal register. Qwen used sinasuri, a closely related verb with slightly different aspect. Mistral produced nasa proseso ng pagsusuri — literally "in the process of review," the most explicit and bureaucratic of the options.
All four express the same information. The difference is institutional register. For a message going from a company to a customer, nire-review reads as natural and contemporary. For a message from a government agency or a legal body, sinusuri or nasa proseso ng pagsusuri signals formality that recipients expect.
MachineTranslation.com's AI Translation Agent asked exactly the right questions: is this formal or informal communication? Is the audience a customer, a client, or a general audience? What tone should the translation convey? Those questions are not optional friction, they are the mechanism by which context transforms a technically accurate translation into the right one.
What "as soon as possible" in Spanish revealed about grammatical accuracy
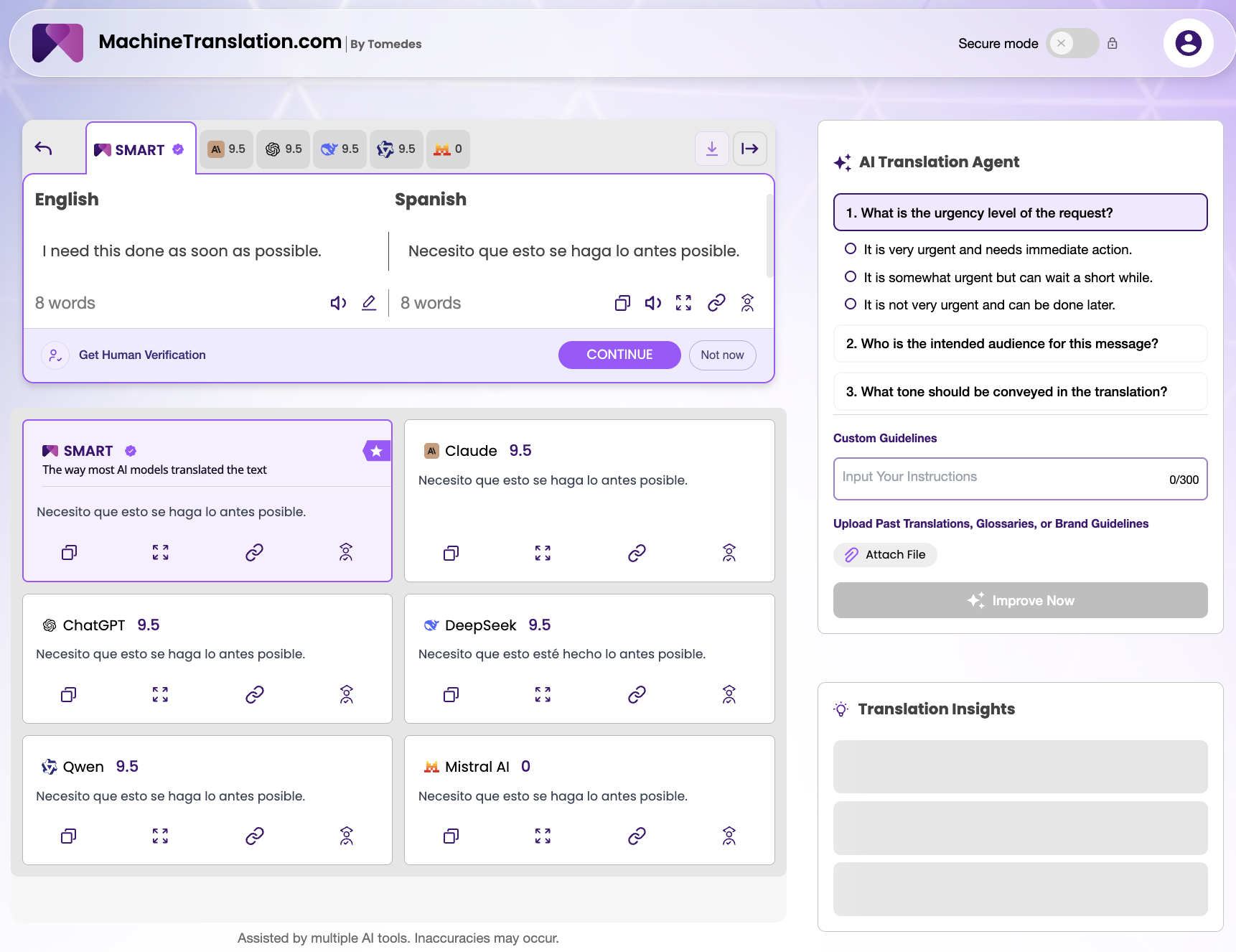
A single sentence produced one of the most instructive divergences across all the tests: four models agreed on se haga, and one (DeepSeek) chose esté hecho.
In Spanish subjunctive grammar, se haga and esté hecho are both correct. But they encode different things. Se haga focuses on the action, the process of doing. Esté hecho focuses on the outcome, the state of completion. In a high-stakes business context where the sender means "I need to see this finished," esté hecho is arguably more precise. In a workplace request where the process matters as much as the endpoint, se haga reads more naturally.
DeepSeek's choice is not a mistake. It is a grammatical interpretation of "done", and it is the kind of interpretation that a human translator would pause on. The AI Translation Agent's question about urgency level captures exactly this: whether the sender means this process should begin immediately or this result should exist immediately changes which Spanish construction is more accurate.
For all the English-to-Spanish translation jobs MachineTranslation.com processed in a single 90-day period, this kind of grammatical precision is not an edge case. It is the difference between a translation that communicates intent and one that technically conveys information.
Why document-scale accuracy is a different problem from phrase accuracy
Every example so far has involved short inputs — a word, a sentence, a short paragraph. But MachineTranslation.com's platform data shows that a significant and growing portion of translation work is happening at a completely different scale.
Users in the platform's document workflow segment (those translating substantial, multi-section content) average 4,841 words per translation job. That is not a phrase or a form. It is a contract, a compliance report, an engineering specification, a medical protocol. And thousands of users on the platform regularly submit documents exceeding 1,000 words in a single session.
"Phrase accuracy and document accuracy are related but not the same problem," says Shashank, Tech Lead at Tomedes. "At the phrase level, the question is whether a word is correctly translated in context. At the document level, the question is whether terminology stays consistent across 50 pages, whether the register holds across sections written in different styles, whether the same named entity is handled the same way every time it appears. A tool that scores 9.5 on a sentence can still produce an inconsistent document if it lacks the architecture to maintain context across length."
This is why document workflow users have the highest lifetime value of any segment on MachineTranslation.com, an average of $14.52 versus under $1 for free users. They are paying precisely because they understand the cost of getting document-scale translation wrong. A mistranslated clause in a supplier contract or a terminology inconsistency in a regulatory submission is not a stylistic inconvenience. It is a liability.
MachineTranslation.com's Key Term Translations panel (visible in the Tagalog document test above) is built specifically for this problem. It extracts operative terminology from the source, maps each term to its translation, and makes the mapping reviewable before the document is finalised. For users translating across English, Spanish, Japanese, and Russian (the four highest-volume pairs on the platform), that consistency layer is the difference between document-level accuracy and phrase-level accuracy assembled into a document.
How to actually test whether a tool is accurate for your language pair
The tests in this post suggest a practical framework for evaluating accuracy that does not require understanding BLEU scores or post-editing workflows. It requires three inputs: a short phrase, a paragraph, and a document sample.
-
Start with a register-sensitive phrase. Choose something that carries formality weight in your target language — an apology, a formal request, a professional greeting. Run it through multiple engines. If all models produce the same output, note whether the tool explains why that output is preferred. If they diverge, note whether the tool shows you the divergence or hides it. Divergence that is shown is information. Divergence that is hidden is a red flag.
-
Test a short professional sentence with urgency or ambiguity. Phrases like "I need this done as soon as possible" or "please confirm receipt" have grammatical options in most target languages. A tool that treats these as single-answer questions is making interpretive decisions silently. A tool that asks about context (urgency level, audience, tone) is doing the work a translator would do.
-
Test a paragraph from your actual document type. Use something representative: a clause from a contract, a section from a compliance document, a product description. Look at the scores across engines, look at the Key Term extractions, and look at whether the output maintains consistent register across the whole paragraph. Sentence-level accuracy that degrades at paragraph level is a document accuracy problem.
"Accuracy is ultimately about whether the translation serves its purpose," says Ofer, CEO of Tomedes. "For a casual message, that might mean readable and natural. For a legal document, it means terminology consistent with the jurisdiction, register appropriate for the authority receiving it, and no interpretive leaps that the original didn't make. Testing at the right scale (for your content type and your stakes) is how you get a meaningful answer."
MachineTranslation.com's multi-model approach (running inputs across multiple models simultaneously and surfacing both consensus and divergence) is designed to make that test visible rather than abstract. For language pairs like Tagalog, where register decisions are embedded in verb choice, and Spanish, where grammatical aspect encodes intent, the consensus score is not the only output worth reading. The divergence is where the accuracy question actually lives. For language-pair-specific translation, see MachineTranslation.com's English to Spanish, English to Japanese, and Tagalog to English translation tools, each of which applies the same multi-model methodology.
FAQ
1. Why do so many people search for "accurate" translation but struggle to find a real answer?
Because most translation tools answer a different question. They show you features, speed comparisons, or supported languages — not evidence of accuracy for your specific language pair and content type. The 250,000+ monthly searches across accuracy-intent translation queries reflect real demand for that evidence, and very few pages provide it.
2. Is AI translation accurate enough to use for professional documents?
For many language pairs and document types, yes — but the answer depends on what "accurate" means for your specific use case. A high SMART consensus score on a phrase test is a strong signal for phrase-level accuracy. Document-scale accuracy requires additional evaluation: terminology consistency across length, register stability across sections, and handling of ambiguous constructions. MachineTranslation.com's Key Term Translations panel and multi-engine comparison view are designed to make both levels of accuracy evaluable before you commit to a final output.
3. Which language pairs are the hardest for AI to translate accurately?
Language pairs that involve high register sensitivity, complex morphology, or significant structural divergence from English present the most translation decisions — which means more opportunities for engines to diverge. Arabic (formal vs. colloquial register), Japanese (formality levels embedded in grammar), and Tagalog (institutional vs. casual verb forms) all showed meaningful engine divergence in MachineTranslation.com's testing. That divergence is not evidence that AI handles these pairs poorly, it is evidence that the pairs carry genuine complexity that rewards a multi-model approach over a single-model answer.
4. What does it mean when engines get different scores on the same translation?
Model scores reflect how well a given output matches the consensus across all models in the run. A score of 9.5 means the output aligns closely with what the majority of models produced. A score of 0 (as Mistral AI received on several tests above) typically means the model's output diverged significantly from the consensus, not necessarily that the output is wrong, but that it took a different interpretive path. For high-stakes content, outputs that diverge from consensus are worth reviewing manually before use.
5. How does MachineTranslation.com define translation accuracy?
Not as a single score, but as fitness for purpose in context. A translation is accurate when it carries the correct meaning, at the correct register, with consistent terminology, for the intended audience and use case. MachineTranslation.com's platform surfaces the information needed to evaluate all four dimensions: consensus output (meaning), model divergence (register decisions), Key Term Translations (terminology), and AI Translation Agent questions (context and audience). Together, these produce a more complete picture of accuracy than any single quality score.