June 19, 2026
Claude vs GPT-4.1: We ran both on the same translations. Here's what we found.
The debate about Claude versus GPT-4.1 tends to produce one of two outcomes: a list of benchmarks that don't map to real use cases, or a confident conclusion that turns out to be based on one test in one language on one type of content. Neither is particularly useful if what you actually need is a reliable translation.
We took a different approach. Using MachineTranslation.com — the only AI translation platform that runs Claude and ChatGPT (powered by GPT-4.1) simultaneously on the same input — we ran three tests across two language pairs. Standard business text. Then idioms. The results were not what most comparison articles would lead you to expect, and the most important finding has nothing to do with which model scored higher.
Table of contents
- How we ran the test
- Test 1: A standard business phrase (English → Spanish)
- Test 2: A German idiom (German → English)
- Test 3: A French idiom (French → English)
- What the scores are actually measuring, and where both models fall short
- Why the SMART consensus catches what neither model caught alone
- So which AI model is better for translation?
- Frequently asked questions
How we ran the test
MachineTranslation.com's SMART mechanism runs up to 22 AI models at once on the same input text and selects the translation that the majority agree on. Crucially, it also shows you each model's individual output and score in a single view — no switching tabs, no re-entering text, no wondering whether you tested both models under the same conditions.
For this comparison, we focused on Claude and ChatGPT (GPT-4.1) specifically, alongside the SMART consensus output. We chose three phrases designed to test different translation demands: a standard business expression, a German idiomatic phrase, and a French idiomatic phrase. Each represents a real translation scenario users encounter daily.
The SMART score shown for each model reflects a composite quality signal — fluency, accuracy, and agreement with other models in the pool. The higher the score, the more closely a model's output aligns with what the broader pool determined to be the strongest translation.
Test 1 — A standard business phrase: "Please find attached" (English → Spanish)
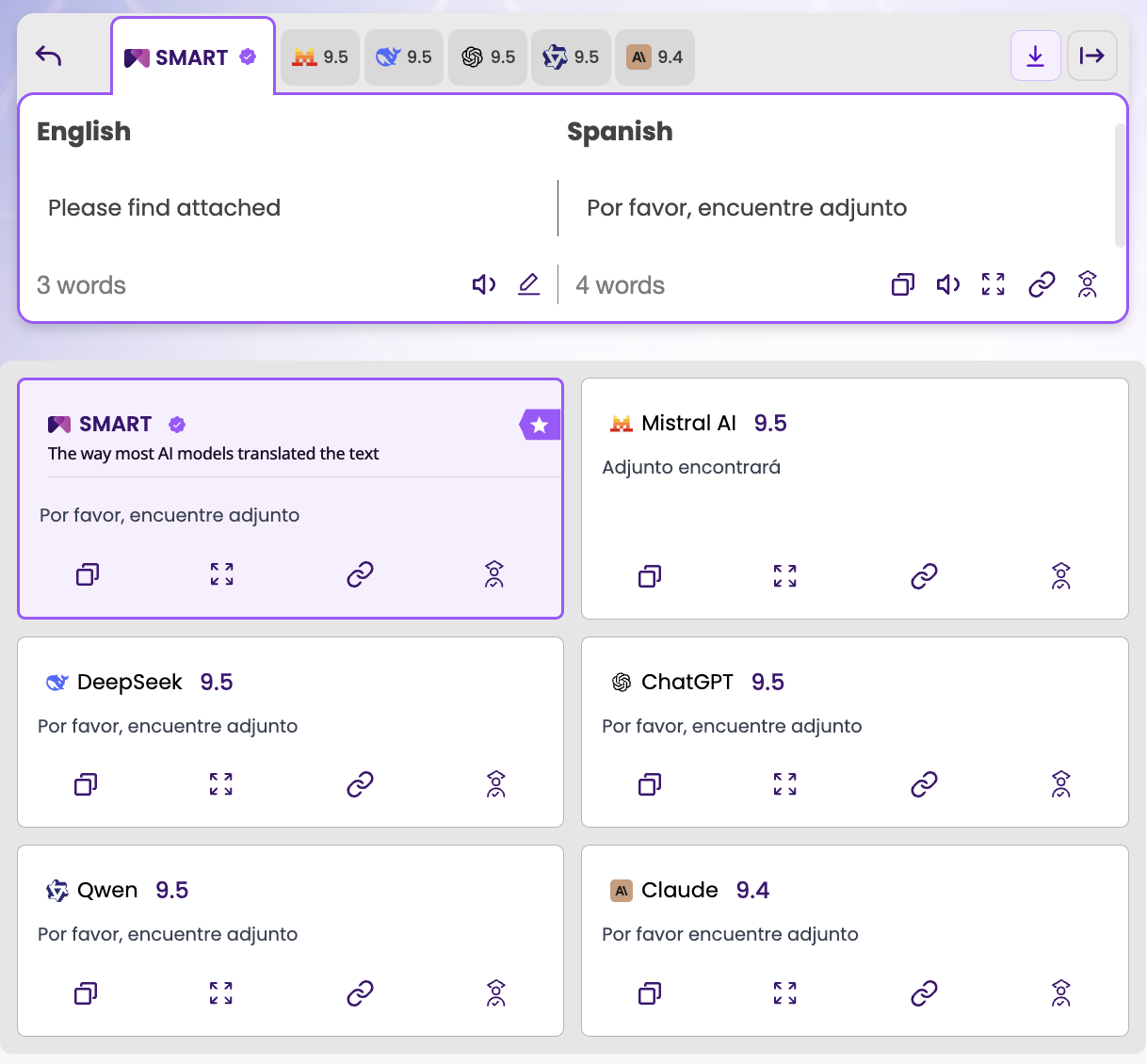
ChatGPT: 9.5.
Output: "Por favor, encuentre adjunto."
Claude: 9.4.
Output: "Por favor encuentre adjunto."
For a standard business email phrase in wide use across industries, both models perform at the top of the quality range. The gap between them is a single punctuation mark: Claude's output drops the comma after "Por favor," — a minor but technically incorrect omission in formal written Spanish.
The SMART output matches ChatGPT's version: "Por favor, encuentre adjunto." Four out of five visible models agreed. Mistral diverged with "Adjunto encontrará", an inverted word order that is grammatically valid but unusual in a business email register. SMART correctly excluded it.
What this test tells you: For everyday business language, Claude and GPT-4.1 are functionally equivalent. The 0.1-point gap reflects a minor precision difference, not a meaningful quality divide. Either model handles standard professional text competently.
Test 2 — A German idiom: "Ich verstehe nur Bahnhof" (German → English)
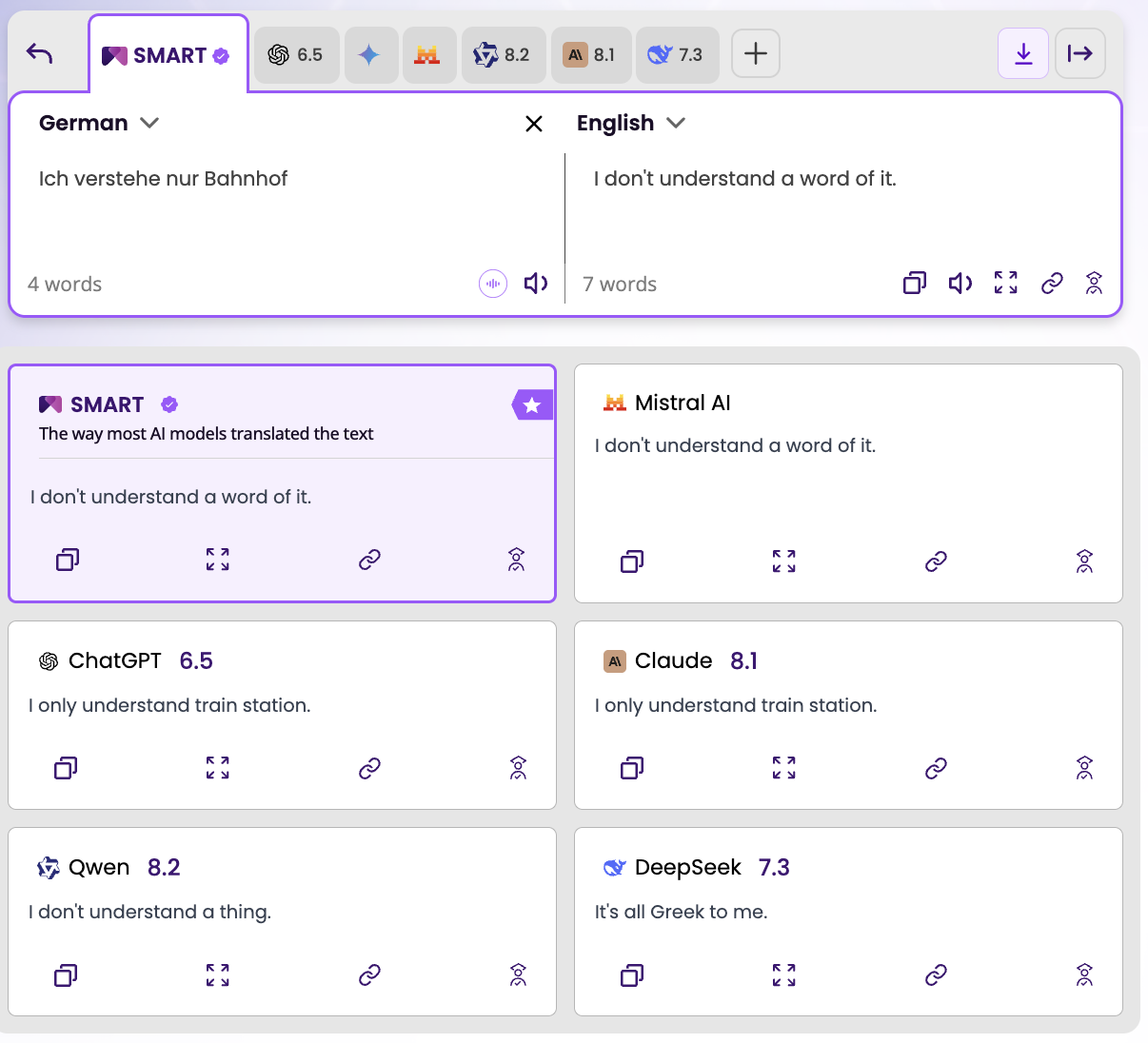
ChatGPT: 6.5.
Output: "I only understand train station."
Claude: 8.1.
Output: "I only understand train station."
"Ich verstehe nur Bahnhof" is a German idiom meaning "I don't understand a word of it." The phrase has nothing to do with train stations — the word Bahnhof is simply the most incongruous, absurd word the speaker can think of, used to express complete incomprehension. It is one of the most commonly used idioms in everyday German.
Both ChatGPT and Claude translated it literally. Word for word. "I only understand train station." The result is grammatically correct, reads as complete nonsense in English, and fails to communicate anything the original speaker intended.
Claude scored marginally higher (8.1 vs ChatGPT's 6.5), suggesting the SMART mechanism weighted something in Claude's output slightly more favourably, but both outputs are functionally wrong for any real-world use. A German speaker who wrote "Ich verstehe nur Bahnhof" to express their confusion would receive an English translation that makes no sense to the recipient.
Meanwhile, Mistral identified the correct idiomatic equivalent: "I don't understand a word of it." DeepSeek found the meaning but used a different English idiom: "It's all Greek to me." Qwen got close with "I don't understand a thing." The SMART consensus selected Mistral's output, the most precise and natural English equivalent.
What this test tells you: On idiomatic German, both Claude and GPT-4.1 share the same failure mode. They translate the words, not the meaning. The 1.6-point gap between them is less meaningful than the fact that they made the same type of error.
Test 3 — A French idiom: "Les carottes sont cuites" (French → English)
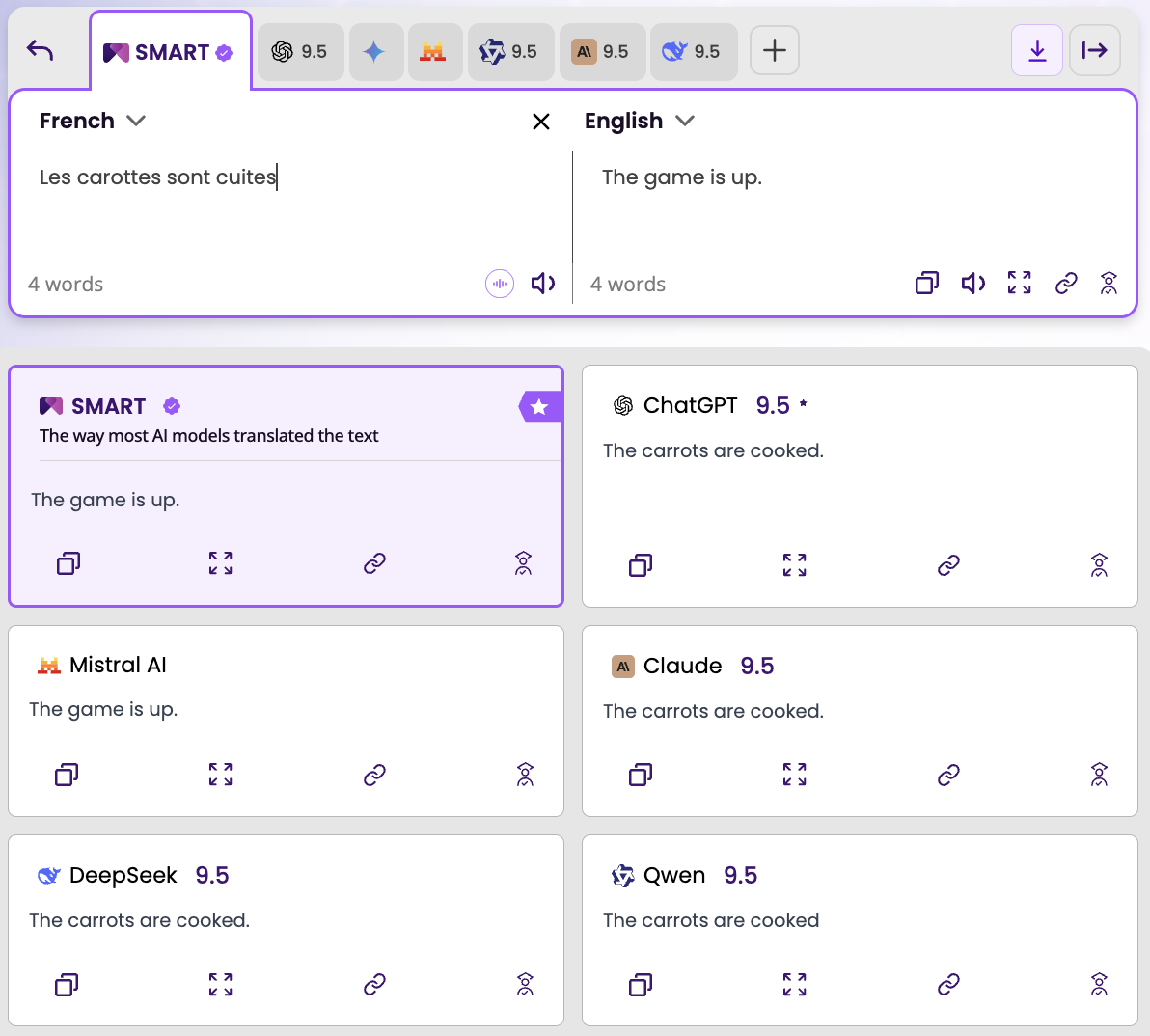
ChatGPT: 9.5.
Output: "The carrots are cooked."
Claude: 9.5.
Output: "The carrots are cooked."
"Les carottes sont cuites" is a French idiom meaning "the game is up" — it's over, there's nothing left to do. It originated from the practice of cooking carrots past the point of saving. In French, it carries a tone of finality, resignation, or dark humour depending on context.
Both Claude and ChatGPT scored 9.5. Both returned "The carrots are cooked." Both were wrong.
This is the most instructive result of the three tests. The high scores reflect that both models produced fluent, grammatically correct output — they just produced a literal translation of a phrase whose meaning is entirely non-literal. A French speaker writing "les carottes sont cuites" to signal that a deal has collapsed, a situation is irretrievable, or a project is dead would receive an English translation about vegetable preparation.
Only Mistral identified the correct English equivalent: "The game is up." SMART selected it.
What this test tells you: High scores do not guarantee correct meaning. When both Claude and ChatGPT score 9.5 on a phrase they've both translated incorrectly, the score is measuring fluency of output, not fidelity to intended meaning. This is the idiom problem in its clearest form.
What the scores are actually measuring, and where both models fall short
Across three tests, Claude and ChatGPT scored within a fraction of each other on standard text (9.4 vs 9.5) and made the same error on both idiom tests. The German idiom produced a larger visible gap (Claude 8.1, ChatGPT 6.5), but both outputs were functionally incorrect. The French idiom produced identical scores (both 9.5) despite both outputs being wrong.
This points to something important about how AI translation quality scores work, and what they don't capture.
As TechBullion's analysis of why the same phrase produces four different translations across AI models found, score-based comparisons between models consistently underreport the scale of idiomatic translation failures because fluency metrics do not detect meaning loss in culturally embedded phrases.
The shared failure mode between Claude and GPT-4.1 has a structural explanation. Both models are trained on vast corpora that include idiom definitions and explanations — but when translating a phrase in isolation, without contextual signals that would flag it as idiomatic, both default to compositional translation: parse the words, translate each one, assemble the result. The meaning encoded in the idiom as a unit does not survive.
This is not a minor edge case. Technology.org's coverage of how five AI models translated the same phrase differently documented the same pattern across a broader model set: idioms and culturally specific expressions represent a systematic weak point for single-model AI translation, regardless of which model is doing the translating.
Why the SMART consensus catches what neither model caught alone
The SMART engine did not choose Claude over ChatGPT or vice versa. In both idiom tests, it selected Mistral's output — a model that correctly identified the idiomatic meaning that the two most prominent models missed.
This is the practical value of running 22 models simultaneously. No single model is universally correct. GPT-4.1 and Claude are among the most capable AI models available, and they are both wrong on phrases that a competent human translator would handle without difficulty. When those two models agree on an incorrect translation, a system that only runs those two models has no way to flag the problem.
According to MachineTranslation.com's internal benchmarking, the SMART consensus approach reduces translation error risk by 90% compared to single-model output. With over 1,500,000 users relying on the platform, that margin is not theoretical — it reflects the systematic advantage of cross-verification over individual model confidence.
As Future of Things reported in their analysis of what separated results when 22 AI models ran on the same text, the models that diverge from the consensus are often the most informative — they surface exactly the kind of precision failures that look fine on the surface but carry real costs in practice.
The divergence score is the signal. When ChatGPT scored 6.5 on the German idiom test, that low score wasn't a penalty — it was MachineTranslation.com telling you that something in that output didn't hold up against the broader model pool. When Claude and ChatGPT both scored 9.5 on the French idiom but SMART still selected a different output, that gap between individual score and consensus choice reveals the limits of evaluating any single model in isolation.
So which AI model is better for translation?
Based on these tests, the honest answer is: neither is reliably better than the other for translation. They perform almost identically on standard text and fail almost identically on idiomatic language. The architecture that makes both models impressive (large-scale pattern matching across enormous training data) produces the same type of translation failure when meaning is encoded in cultural convention rather than compositional grammar.
What does make a measurable difference is whether you are running one model or many. MachineTranslation.com is the only AI translation platform where Claude and GPT-4.1 translate your text at the same time, in the same interface, scored against a consensus of up to 22 models. You see where they agree, which tells you the output is reliable. You see where they diverge, which tells you the text deserves closer attention. And the SMART output resolves the conflict based on what the broader model pool determined, not what any one model was confident about.
The comparison between Claude and GPT-4.1 is a useful question. The more useful answer turns out to be: run both.
Frequently asked questions
1. Is Claude or GPT-4.1 better for translation?
Based on direct testing on MachineTranslation.com, Claude and GPT-4.1 perform at comparable levels for standard business and professional text. Both score in the 9.4–9.5 range on straightforward phrases. On idiomatic language, both models share the same tendency to translate literally rather than idiomatically — and their scores diverge more, with ChatGPT scoring as low as 6.5 on a German idiom where Claude scored 8.1. Neither model consistently outperforms the other; both benefit from being run alongside additional models for cross-verification.
2. How does MachineTranslation.com compare Claude and GPT-4.1?
MachineTranslation.com's SMART mechanism runs both Claude and ChatGPT (GPT-4.1) simultaneously on the same input, alongside up to 20 additional AI models. Each model's output and quality score appears in a single view. The SMART consensus output represents the translation that the majority of models agreed on, which in practice outperforms any single model on culturally complex or idiomatic content.
3. Why did both Claude and ChatGPT get the idiom wrong?
Both models translated idioms literally, rendering the individual words rather than the meaning encoded in the phrase as a unit. This is a known limitation of compositional translation in large language models: without explicit contextual signals that a phrase is idiomatic, models default to word-level translation. The SMART engine resolved this by drawing on models in the pool that did correctly identify the idiomatic meaning.
4. What does the SMART score mean in the comparison panel?
The SMART score reflects a composite of fluency, accuracy, and agreement with the broader model pool. A high score indicates the model's output aligns closely with the consensus. A lower score (like ChatGPT's 6.5 on the German idiom test) signals meaningful divergence from the pool, which is itself a useful quality signal even when individual model confidence appears high.
5. Can I test Claude vs GPT-4.1 on my own text?
Yes. MachineTranslation.com runs both models simultaneously on any text you enter, showing individual scores and outputs side by side. You can test your own phrases, documents, or language pairs and see exactly where the models agree, where they diverge, and what the SMART consensus determines.

By Rachelle Garcia
Connect on LinkedInRachelle leads product and AI at Tomedes, where she runs the experiments that turn internal data into better translation experiences. She writes about what actually happens when you build AI products such as MachineTranslation.com — the numbers, the surprises, and the parts that don't go to plan.
Share: