May 15, 2026
ChatGPT o-series vs. Claude for translation: What independent tests actually show
In a 200-sentence translation test across 8 language pairs (scored by native speakers), Claude chose idiomatic equivalents 92% of the time. ChatGPT chose a literal translation 34% of the time on the same set of idioms. When translating "it's raining cats and dogs" into Spanish, Claude produced "está lloviendo a cántaros" — the natural cultural equivalent. ChatGPT produced "está lloviendo gatos y perros" — word-for-word, meaningless in Spanish. Source: AI Tool Clash, February 2026.
The same study found the reverse on technical documentation: ChatGPT scored 8.2/10 versus Claude's 7.8/10, with better code formatting preservation and more consistent terminology over long technical documents.
Neither model dominated. Both have real, documented advantages, and they show up in predictable content categories. This article is about which category you are translating in, and what that means for which model to use.
In this article
- How do the models actually compare in independent testing?
- Where does Claude have a structural advantage?
- Where does the ChatGPT o-series have a structural advantage?
- How have both models evolved since o1 and Claude 3.5?
- What does this mean for professional translation workflows?
- Frequently asked questions
How do the models actually compare in independent testing?
The short answer: Claude leads on idiom, literary tone, and cultural nuance. ChatGPT's o-series leads on technical precision, terminology consistency, and structured document handling. Both score near the top of any individual model evaluation.
The most methodologically rigorous independent test available pits the two models against 200 sentences spanning 8 language pairs (casual conversation, business and formal text, idioms and slang, literary passages, and technical documentation) with three native speakers per language providing scores on accuracy and naturalness.
Results:
- Overall: Claude 8.3/10, ChatGPT 7.9/10
- Idioms and slang: Claude 8% literal error rate; ChatGPT 34% literal error rate. Claude consistently found cultural equivalents. ChatGPT frequently translated the surface-level words.
- Literary passages: A Gabriel García Márquez passage scored by literature professors — Claude preserved magical realism tone, sentence rhythm, and Colombian speech patterns (9.2/10). ChatGPT produced accurate but tonally flat output (7.5/10).
- Technical documentation: ChatGPT 8.2/10, Claude 7.8/10. ChatGPT better at code formatting, consistent domain terminology, and maintaining translations across long technical documents.
- Ambiguous sentences: Given structurally ambiguous source text, Claude provided both interpretations or requested clarification. ChatGPT chose one interpretation and was wrong 60% of the time.
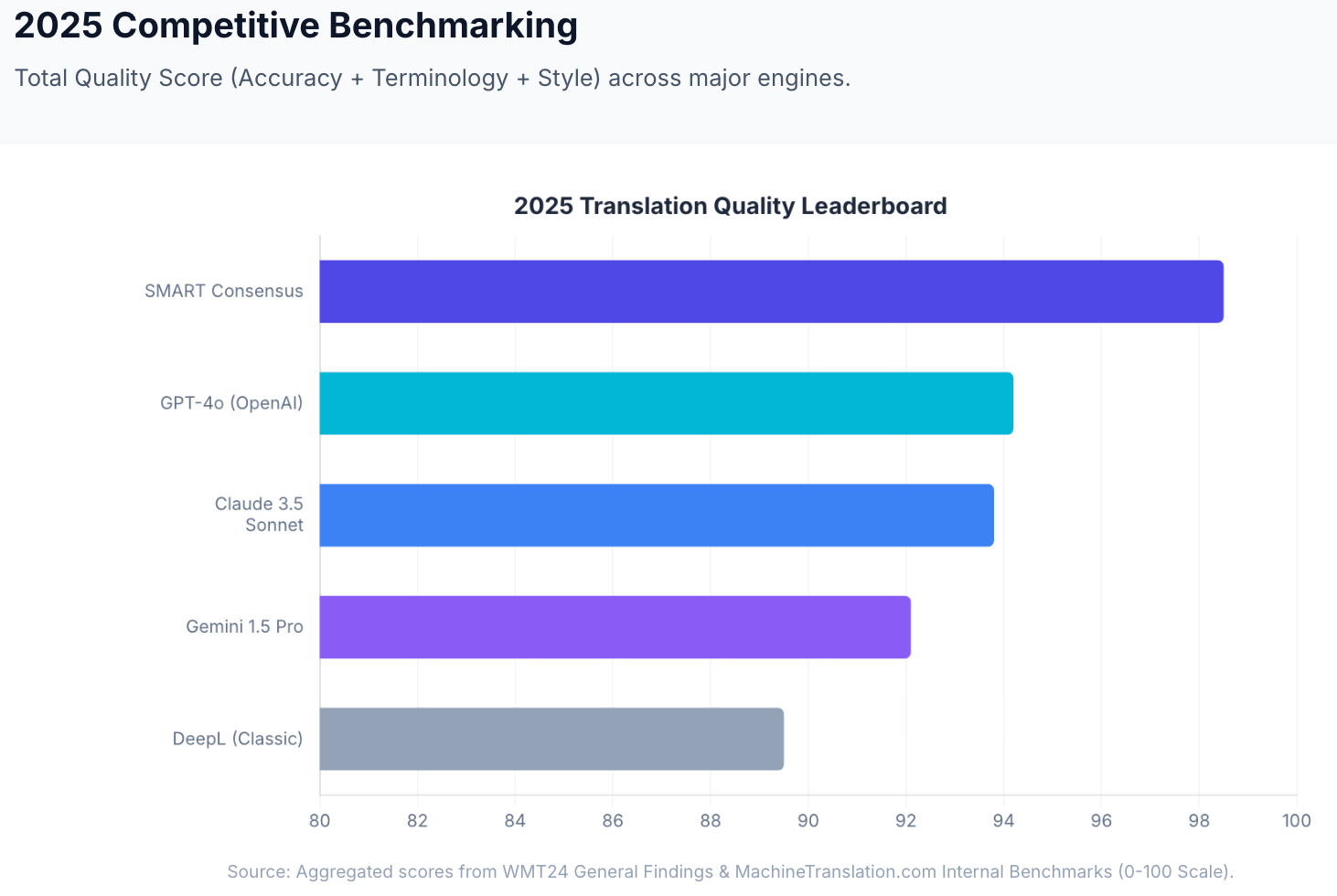
In MachineTranslation.com's internal benchmarks across 5,000 words of mixed technical and marketing text, Claude (3.5 Sonnet tier) scored 93.8/100 and GPT-4o scored 94.2/100 on a combined accuracy, terminology, and style measure — a gap of 0.4 points. The difference in practice is not in the aggregate score. It is in which categories each model handles better, as the independent test above shows.
Where does Claude have a structural advantage?
Claude's advantages are most consistent in content where meaning depends on subtext, cultural context, or tone — not just word-level accuracy.
Idiomatic and culturally embedded language. The 34% vs 8% literal idiom error rate is the clearest documented gap. This is not a minor stylistic preference. A translated marketing campaign in which idioms land as literal phrases is actively confusing to native readers. Claude's training places strong weight on natural language equivalence, producing output that reads as something a native speaker would say rather than something that has been translated.
Literary and tone-sensitive content. The literature professor scoring (9.2 vs 7.5 for a Márquez passage) captures what many professional translators observe: Claude preserves register, rhythm, and emotional tone at a level ChatGPT does not consistently match. For content where voice matters as much as meaning (brand copy, editorial content, creative materials), this difference is commercially significant.
Ambiguous source text. Claude's documented tendency to surface ambiguity rather than resolve it arbitrarily is valuable for professional translation. A translator or reviewer given both interpretations can make the correct call. A single wrong interpretation delivered confidently in fluent target language may go uncorrected.
Long-document coherence on narrative content. Claude's context window (200K tokens for Sonnet 4.6, up to 1M tokens for Opus 4.6 in beta) allows full-document processing without chunking. For narrative or tonally unified content (a novel chapter, a long-form report with a consistent voice) maintaining stylistic coherence across the full document is a genuine advantage. However, the study found ChatGPT maintained more consistent terminology across long documents. The distinction matters: Claude is more consistent on tone; ChatGPT is more consistent on terminology. Different content types need different kinds of consistency.
Where does the ChatGPT o-series have a structural advantage?
ChatGPT's o-series leads where the translation problem is about precision, structure, and terminology — rather than cultural naturalness.
Technical documentation and specialised content. The study's 8.2 vs 7.8 finding on technical content is small but consistent with a broader pattern. ChatGPT showed better code formatting preservation, more stable handling of domain-specific terms, and stronger consistency when translating technical manuals and API documentation. A 2025 analysis by translator Hiroshi Kinoshita across DeepL, GPT-4, and Claude specifically concluded that "for highly exact translations where specialized terms must be used consistently, [Claude is] still a notch below DeepL or GPT-4" — though noting Claude's rapid evolution. Source: Hiroshi Kinoshita, Medium, April 2025.
Reasoning through complex structure. OpenAI's o-series models (o1 and its successors o3 and o3-pro) apply chain-of-thought reasoning before generating output. For translation tasks where the source text has complex structural relationships between clauses, multi-layered conditionals, or embedded technical logic, the deliberation step can produce more structurally accurate outputs. Research on o1-class reasoning models for translation found improvements specifically on content with "complex reasoning dependencies" — not on standard content, but on source text where meaning is structurally ambiguous at a logical level. Source: Evaluating o1-Like LLMs for Translation, arxiv.org, 2025.
Speed and throughput. The study found ChatGPT generates translations approximately 20% faster than Claude. For batch processing large volumes of content where latency and throughput matter, this is a real workflow advantage.
Terminology consistency on long documents. As noted above: the study found ChatGPT maintained more consistent terminology across 5,000-word documents. For technical content where a specific term must be rendered identically throughout (legal definitions, product specifications, medical terminology) ChatGPT's approach reduces drift.
How have both models evolved since o1 and Claude 3.5?
The original article compared two models that have since been superseded by two full generations.
OpenAI o-series evolution:
- o1 (September 2024) — first reasoning model generation
- o1-preview and o1-mini deprecated from the API April 28, 2025
- o3 (April 2025) — successor to o1, making 20% fewer major errors on difficult real-world tasks per OpenAI's internal evaluation
- o3-pro (June 2025) — replaced o1-pro
- o4-mini (April 2025) — cost-efficient reasoning replacement for o3-mini
For translation specifically, the structural advantages of the reasoning approach described above (complex structural translation, ambiguity resolution through deliberation) carry forward from o1 through o3. The generation improvements reduce errors but do not fundamentally change where the model has an architectural advantage.
Anthropic Claude evolution:
- Claude 3.5 Sonnet (June 2024) — the model in the original article
- Claude 3.7 Sonnet (February 2025) — improvements to instruction following and contextual depth
- Claude Sonnet 4.6 (February 2026) — current model; enhanced reasoning capabilities, 200K context window, stronger multilingual performance
- Claude Opus 4.6 (February 2026) — highest-capability tier; 1M token context window in beta
The core strengths (idiomatic naturalness, tonal precision, literary quality) have carried forward through each generation. Both models are meaningfully more capable in 2026 than they were at the original comparison point, but the relative difference in where each leads has remained consistent across the independent testing available.
What does this mean for professional translation workflows?
The practical answer is to match the model to the content type — and know that for any professional output, the verification question matters more than the model selection.
| Content type | Recommended model | Evidence |
|---|---|---|
| Idioms, slang, cultural content | Claude | 8% vs 34% literal error rate (AI Tool Clash 2026) |
| Literary and tone-sensitive content | Claude | 9.2 vs 7.5 professor scoring on Márquez (AI Tool Clash 2026) |
| Technical documentation | ChatGPT o-series | 8.2 vs 7.8 technical score; better terminology consistency |
| Structurally complex / ambiguous text | ChatGPT o-series (reasoning) | Chain-of-thought for logical structure (arxiv 2025) |
| Long narrative / tonal consistency | Claude | Full-document context window, tone coherence |
| Long technical / terminology precision | ChatGPT | Consistent terminology across 5,000+ words (AI Tool Clash 2026) |
| Batch / high-volume processing | ChatGPT | ~20% faster generation (AI Tool Clash 2026) |
Both models are among the 22 in MachineTranslation.com's SMART system. SMART runs Claude and ChatGPT simultaneously alongside 20 other models and returns the output the majority agree on. Critically, when Claude and ChatGPT diverge on an ambiguous passage, that divergence surfaces rather than being hidden in a single model's confident output.
In MachineTranslation.com's internal benchmarks, individual top-tier models reach 93–94/100 on translation quality. The 22-model consensus reaches 98.5/100. The gap between Claude's 93.8 and ChatGPT's 94.2 is 0.4 points. The gap between either model and the consensus is 4–5 points. Source: MachineTranslation.com internal benchmarks.
For content where neither model's specific advantages resolve the stakes (legal documents, clinical materials, regulatory submissions), Human Verification escalates the consensus translation to a certified professional reviewer within the same platform. No external agency, 100% accuracy guaranteed.
Translate with Claude, ChatGPT, and 20 other models at MachineTranslation.com — free, no sign-up required.
Frequently asked questions
1. Is ChatGPT o1 better than Claude 3.5 for translation?
Neither model is categorically better. Independent testing across 200 sentences in 8 language pairs found Claude scored higher overall (8.3 vs 7.9) with significantly fewer literal idiom errors (8% vs 34%). ChatGPT scored higher on technical documentation (8.2 vs 7.8) and showed better terminology consistency over long documents. The better model depends on what you are translating. Note: both o1 and Claude 3.5 have been superseded, o3 and Claude Sonnet 4.6 are the current versions.
2. Why does ChatGPT translate idioms literally more often than Claude?
ChatGPT's architecture optimises for accurate token-level prediction and precision. Claude's training places stronger emphasis on natural language equivalence, producing what a native speaker would say rather than what the source words map to. In the 200-sentence study, ChatGPT chose a literal translation for idioms 34% of the time, while Claude found a cultural equivalent 92% of the time.
3. Is Claude better for literary translation?
Yes, based on available independent evidence. The study had three literature professors score both models' translation of a Gabriel García Márquez passage — Claude scored 9.2/10, preserving the magical realism tone, sentence rhythm, and cultural register. ChatGPT scored 7.5/10, described as accurate but tonally flat. For literary and tone-sensitive content, Claude is the stronger documented choice.
4. Is ChatGPT better for technical translation?
In independent testing, ChatGPT showed marginally better performance on technical documentation (8.2 vs 7.8) and maintained more consistent terminology across long technical documents. For content where specific terms must be rendered identically throughout (product specifications, legal definitions, API documentation), ChatGPT's approach reduces terminology drift. For highly exact technical work, both models benefit from explicit glossary prompting.
5. Are o1 and Claude 3.5 still available?
Claude 3.5 has been superseded by Claude Sonnet 4.6 (February 2026) and Claude Opus 4.6. OpenAI o1-preview and o1-mini were deprecated from the API on April 28, 2025. The full o1 model remains available via API. o3 is the current recommended reasoning model; o3-pro and o4-mini are also available. For current translation workflows, o3 (not o1) and Claude Sonnet 4.6 (not Claude 3.5) are the relevant comparison points.
6. Do both models work on MachineTranslation.com?
Yes. Both Claude and ChatGPT (OpenAI's models) are among the 22 models in MachineTranslation.com's SMART system. Every SMART translation runs both simultaneously alongside 20 other models, returning the output the majority agree on. Rather than choosing between them, you see what they collectively agreed on — along with a quality score showing how strong that agreement was.
7. What happens when Claude and ChatGPT disagree on a translation?
When two strong models diverge on an output, that divergence is informative — it often marks a genuinely ambiguous source phrase or a content type where architectural differences produce different valid interpretations. This is more useful than either model presenting its confident interpretation without surfacing the uncertainty.

By Clarriza Heruela
Clarriza Mae Heruela graduated from the University of the Philippines Mindanao with a Bachelor of Arts degree in English, majoring in Creative Writing. Her experience from growing up in a multilingually diverse household has influenced her career and writing style. She is still exploring her writing path and is always on the lookout for interesting topics that pique her interest.
Share: