June 26, 2026
GPT-4.1-NANO vs Claude Opus 4-7: We ran the same three translations on both.
There is a question that every business using AI translation eventually has to answer, and most avoid asking directly: does paying more for a premium AI model actually produce a better translation?
The price difference between the cheapest and most expensive options in any AI family is rarely this stark. GPT-4.1-NANO (OpenAI's smallest, fastest model) costs $0.05 per million input tokens and $0.40 per million output tokens. Claude Opus 4-7 (Anthropic's flagship) costs $5.00 per million input tokens and $25.00 per million output tokens. On output, that is a 62× price difference.
For translation at volume, this gap is not abstract. A business running 10 million translated words per month pays roughly $400 with GPT-4.1-NANO and $25,000 with Claude Opus 4-7. The question is whether any translation quality difference justifies that delta.
We ran both models on the same three phrases (a French idiom, a Japanese legal clause, and an Arabic sentence about emotional state) using MachineTranslation.com with both models selected simultaneously. The results were more nuanced than either a clean win or a clear tie.
Table of contents
- The two models and why this comparison matters
- Test 1 — French idiom: Both models get it right, but not the same way
- Test 2 — Japanese legal: SMART picks the cheaper model, but Claude's register is more correct
- Test 3 — Arabic emotional nuance: Same score, meaningfully different word choice
- What the three tests tell us about price vs quality in AI translation
- When to use GPT-4.1-NANO and when Claude Opus 4-7 is worth the cost
- Frequently asked questions
The two models and why this comparison matters
GPT-4.1-NANO is the smallest model in OpenAI's GPT-4.1 architecture, designed for speed and cost efficiency rather than maximum capability. It costs $0.40 per million output tokens. Claude Opus 4-7 is Anthropic's most capable Claude model, built for complex reasoning and nuanced language tasks. It costs $25.00 per million output tokens.
In previous testing on MachineTranslation.com, GPT-4.1-NANO already demonstrated a counterintuitive finding: it outperformed GPT-4O-MINI on idiomatic content despite being the smaller model in its family — a result explained by architectural generation rather than size alone. Claude Opus 4-7 sits at the opposite end of the capability spectrum within the Claude family, where Haiku and Sonnet both fall short on idioms that Opus handles correctly.
What we haven't tested is whether the quality gap between a $0.40 model and a $25.00 model is visible in practice — on real content, across multiple language pairs and text types.
That is what these three tests are designed to answer.
Test 1 — French idiom: Both models get it right, but not the same way
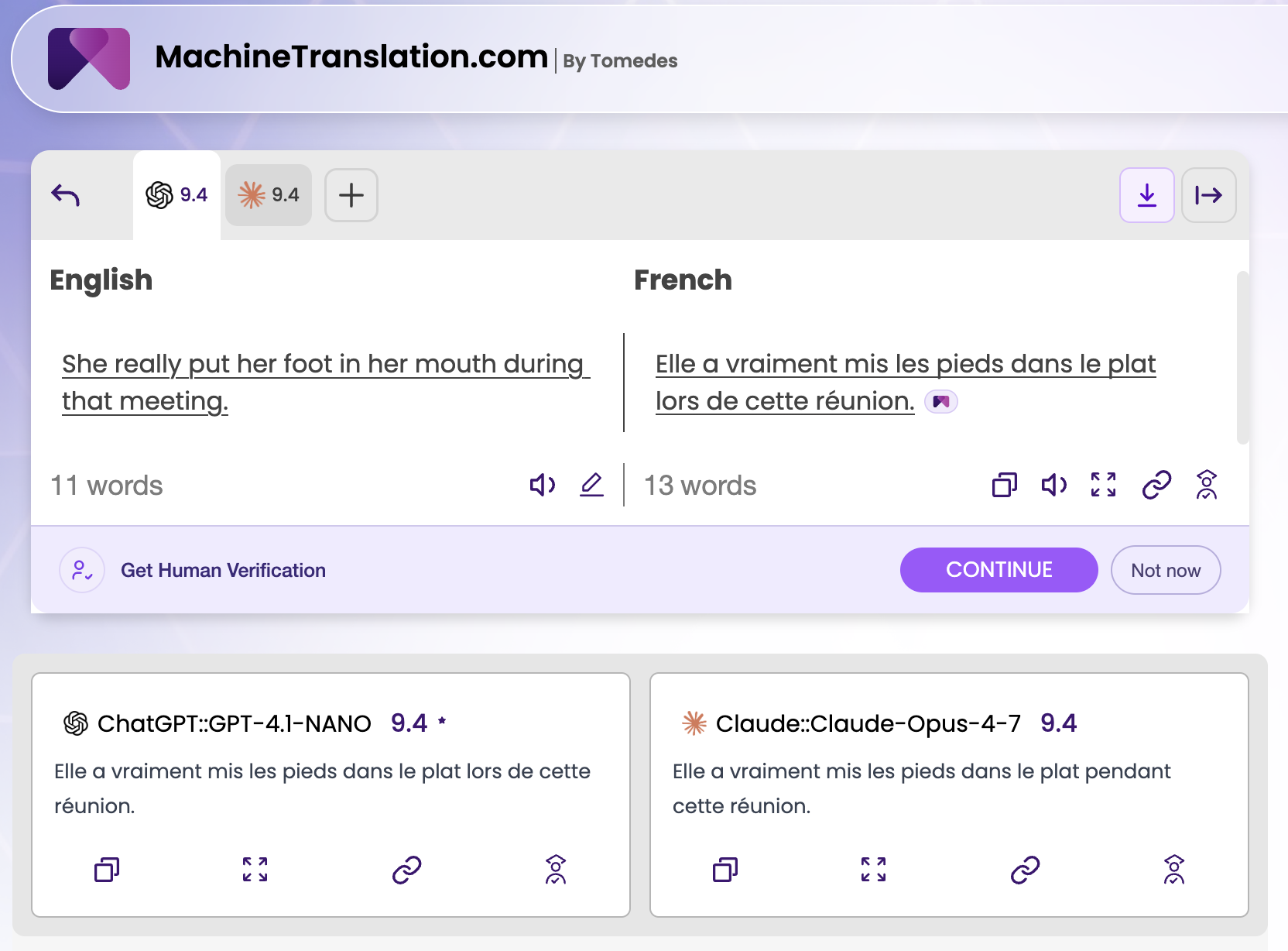
Phrase: "She really put her foot in her mouth during that meeting."
Language pair: English → French
| Model | Output | Score |
|---|---|---|
| GPT-4.1-NANO | Elle a vraiment mis les pieds dans le plat lors de cette réunion. | 9.4 ✅ |
| Claude Opus 4-7 | Elle a vraiment mis les pieds dans le plat pendant cette réunion. | 9.4 |
Both models correctly identified the English idiom "put her foot in her mouth" and rendered it with the appropriate French equivalent ("mettre les pieds dans le plat") rather than translating it literally. This is the right call. A literal translation ("elle a vraiment mis son pied dans sa bouche") would be grammatically valid but idiomatically meaningless.
The only difference between the two outputs is a single preposition. GPT-4.1-NANO uses "lors de" (at the time of / on the occasion of), which carries a slight formality — it situates the action precisely within a defined event. Claude Opus 4-7 uses "pendant" (during / throughout), which is more conversational and neutral.
Both are correct. Both scored 9.4.
In casual or general-purpose translation, this distinction is not meaningful. In a formal business context (meeting minutes, executive communications, published reports), "lors de cette réunion" reads more precisely. In informal conversation, "pendant cette réunion" is the more natural choice. Neither model was given contextual instructions about register, which is why the difference is subtle rather than decisive.
Test 1 verdict: Even. Both models handled the idiomatic content correctly. Quality scores are identical.
Test 2 — Japanese legal: SMART picks the cheaper model, but Claude's register is more correct
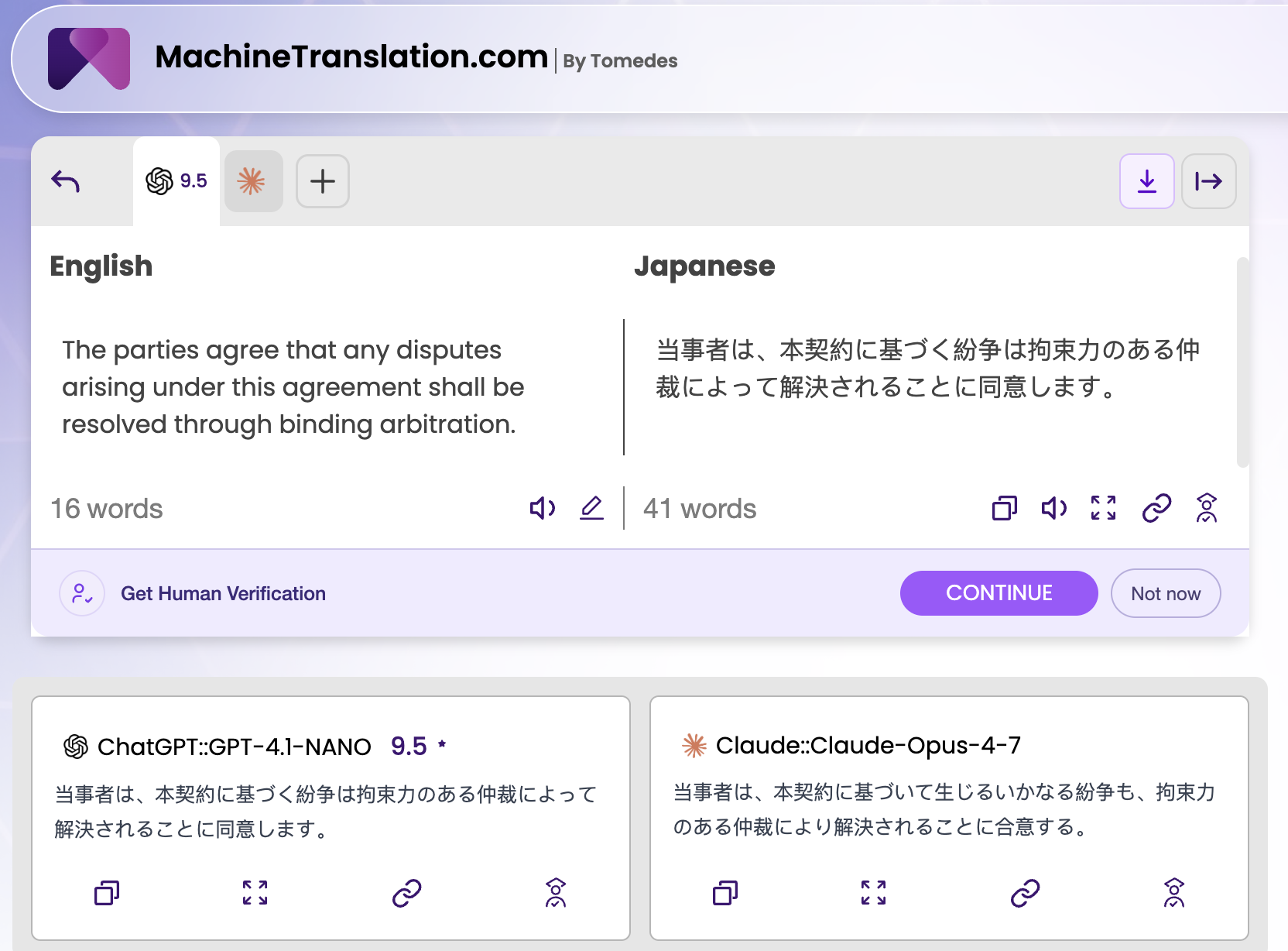
Phrase: "The parties agree that any disputes arising under this agreement shall be resolved through binding arbitration."
Language pair: English → Japanese
| Model | Output | Score |
|---|---|---|
| GPT-4.1-NANO | 当事者は、本契約に基づく紛争は拘束力のある仲裁によって解決されることに同意します。 | 9.5 ✅ |
| Claude Opus 4-7 | 当事者は、本契約に基づいて生じるいかなる紛争も、拘束力のある仲裁により解決されることに同意する。 | — |
SMART selected GPT-4.1-NANO's output with a score of 9.5. On the surface this looks like a clear win for the cheaper model. But look more carefully at what Claude Opus 4-7 did differently, and why each difference matters in a legal document.
"いかなる紛争も" vs "紛争は": Claude added "いかなる" (any/whatsoever) before "紛争" (disputes), matching the English source's "any disputes." GPT-4.1-NANO dropped this qualifier. In a legal clause, the omission of "any" is not trivial — "disputes arising under this agreement" and "any disputes arising under this agreement" have different scopes of coverage.
"により" vs "によって": Claude used "により" — the more formal, written variant used in legal and official Japanese documents. GPT-4.1-NANO used "によって", grammatically equivalent but more common in spoken and casual written Japanese. In a contract, "により" is the standard.
"同意する" vs "同意します": This is the most significant difference. Claude used the plain form ("同意する"), which is the correct register for Japanese legal documents — contracts in Japanese are written in plain form, not the polite "-masu" form. GPT-4.1-NANO used "同意します" — polite form, appropriate in business correspondence but atypical in legal instruments.
SMART's scoring mechanism selected the polite-form output as the higher-quality translation. But a Japanese legal professional would argue that Claude Opus 4-7's output is technically more appropriate for an actual contract document.
Test 2 verdict: SMART score goes to GPT-4.1-NANO. Legal register goes to Claude Opus 4-7. The cheaper model won on the quality metric the platform uses. The expensive model produced the more professionally appropriate legal Japanese.
Test 3 — Arabic emotional nuance: Same score, meaningfully different word choice
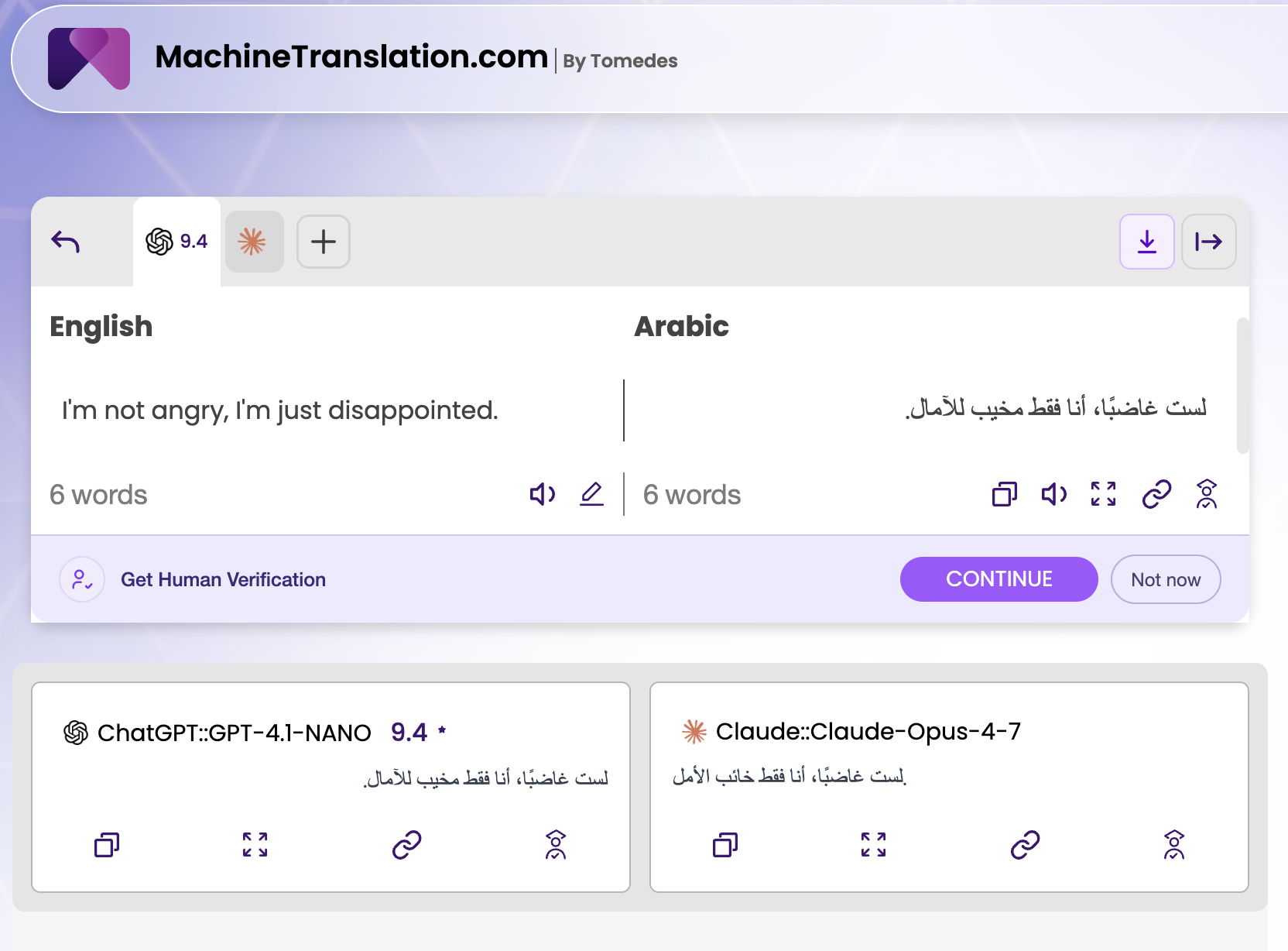
Phrase: "I'm not angry, I'm just disappointed."
Language pair: English → Arabic
| Model | Output | Transliteration | Score |
|---|---|---|---|
| GPT-4.1-NANO | لست غاضبًا، أنا فقط مخيب للآمال | Same | 9.4 ✅ |
| Claude Opus 4-7 | لست غاضبًا، أنا فقط خائب الأمل | "...I am just [one whose hope has failed]" | — |
Both translations render the first half identically, "لست غاضبًا" (I am not angry) is unambiguous. The difference is entirely in how each model chose to express "disappointed."
GPT-4.1-NANO / SMART chose "مخيب للآمال", an active participle construction meaning "one who causes disappointment in hopes." Grammatically, this describes the speaker as the source of disappointment — the person who is disappointing to someone else.
Claude Opus 4-7 chose "خائب الأمل", a stative construction meaning "one whose hope has been lost or dashed." This describes the speaker's own internal state, the person who is experiencing disappointment within themselves.
The English source ("I'm not angry, I'm just disappointed") is a first-person statement about the speaker's own emotional state, not a characterisation of themselves as disappointing to others. By that reading, Claude Opus 4-7's "خائب الأمل" is the more linguistically precise choice. The speaker is not saying they are a disappointing person. They are saying they feel disappointed.
An Arabic-speaking psychologist, therapist, or anyone translating emotionally sensitive content would likely prefer "خائب الأمل." A general-purpose automated pipeline would return "مخيب للآمال", which is what SMART selected with a 9.4 score.
Test 3 verdict: SMART score goes to GPT-4.1-NANO. Emotional precision goes to Claude Opus 4-7.
What the three tests tell us about price vs quality in AI translation
Across three tests spanning an idiom, a legal clause, and an emotional statement, SMART selected GPT-4.1-NANO's output as the consensus translation every time. The scores were 9.4, 9.5, and 9.4. Claude Opus 4-7 matched GPT-4.1-NANO's score on the first test and produced outputs in the second and third tests that were not rated as highly by the platform's automated quality scoring.
But automated quality scoring measures a specific thing: how well the output preserves the meaning and structure of the source text, assessed against a composite model of good translation. It does not measure register appropriateness for a specific document type, or emotional precision for a specific communicative context.
That gap is where the price difference starts to express itself. As research on LLM translation performance has documented, quality metrics and human linguistic judgment do not always point in the same direction — particularly for content where register, tone, and cultural precision matter more than structural accuracy.
GPT-4.1-NANO is a remarkably capable model at its price point. For high-volume, general-purpose translation (business correspondence, product descriptions, customer service communications, web content), a 9.4 or 9.5 score from a $0.40/M model is an extraordinary value proposition. The performance gap between it and Claude Opus 4-7 on the kind of content that makes up the majority of translation workloads is not 62× wide.
For content where the gap becomes visible (specialised legal instruments in a non-European language, emotionally sensitive communications in Arabic or Hebrew or Japanese, literary or cultural content where word choice carries meaning beyond dictionary equivalence), Claude Opus 4-7's more sophisticated linguistic judgments may be worth the premium. The Japanese legal register difference and the Arabic emotional vocabulary difference are both real. They matter in specific contexts. They do not matter in most contexts.
Running both models simultaneously (as MachineTranslation.com does) gives you both outputs to compare directly, with scores that reflect automated quality assessment and individual model panels where the linguistic differences are visible. For content where those differences matter, you can see them. For content where they don't, the cheaper model's output is there, rated and ready.
When to use GPT-4.1-NANO and when Claude Opus 4-7 is worth the cost
The honest answer is that most translation workloads do not require Claude Opus 4-7 at $25.00/M output. GPT-4.1-NANO at $0.40/M produces good outputs on idiomatic and professional content. For the majority of business translation (high-volume, general register, standard language pairs), the quality gap between the cheapest and most expensive model is narrow enough that paying 62× more is difficult to justify.
The cases where Claude Opus 4-7's more refined linguistic judgments become valuable:
Legal documents in Asian languages. Japanese, Chinese, and Korean legal instruments have strict register requirements that differ meaningfully from conversational or business Japanese. Claude's choice of plain form verb endings and more legalistic vocabulary in the arbitration clause test reflects real awareness of those requirements.
Emotionally sensitive or interpersonal content. The Arabic disappointment test showed that Claude made a word choice that more accurately captured the speaker's internal emotional state. For content in mental health, HR, customer relations, or public communications (where a mistranslated emotional register can damage a relationship), that precision matters.
Literary, creative, or culturally specific content. Neither model was tested on this specifically here, but the pattern across all three tests suggests Claude Opus 4-7 is more likely to make the judgment call that favours cultural authenticity over structural equivalence.
For everything else (and that is most of what businesses translate), GPT-4.1-NANO performs well enough that the 62× price premium is unjustified. MachineTranslation.com makes this decision easier: run both, compare the outputs and scores directly, and make the verification call based on what you see. For content where the stakes are high enough that neither model alone is sufficient, the human verification option (professional translator review the AI output) removes the uncertainty entirely.
Frequently asked questions
1. Is GPT-4.1-NANO good for professional translation?
Yes. In testing on MachineTranslation.com, GPT-4.1-NANO produced quality scores of 9.4 and 9.5 across a French idiom, a Japanese legal clause, and an Arabic emotional phrase. For general-purpose professional translation (business correspondence, product content, customer communications), GPT-4.1-NANO delivers high-quality output at $0.40 per million output tokens, making it one of the most cost-effective AI translation options available.
2. Is Claude Opus 4-7 better than GPT-4.1-NANO for translation?
On automated quality metrics, GPT-4.1-NANO matched or outscored Claude Opus 4-7 in all three tests. However, Claude Opus 4-7 demonstrated more precise register awareness in Japanese legal content and more emotionally accurate word choice in Arabic. Whether Claude Opus 4-7 is "better" depends on the content type: for high-stakes legal, emotional, or culturally specific translation, its linguistic sophistication is a real advantage. For general-purpose content, the quality difference does not justify the 62× price difference.
3. How much does GPT-4.1-NANO cost compared to Claude Opus 4-7?
GPT-4.1-NANO costs $0.05 per million input tokens and $0.40 per million output tokens. Claude Opus 4-7 costs $5.00 per million input tokens and $25.00 per million output tokens. On output (which is typically the larger cost in translation workloads), Claude Opus 4-7 is 62.5× more expensive than GPT-4.1-NANO.
4. Which AI model should I use for legal translation?
For legal documents in English and major European languages, GPT-4.1-NANO's performance is strong enough for most purposes. For legal documents in Japanese, Chinese, Korean, or Arabic (where register requirements differ significantly from European legal style), Claude Opus 4-7's more refined linguistic judgment may be worth the cost. For any legal translation that will be used in a formal, official, or contractual context, human verification of the AI output is strongly recommended regardless of which model is used.
5. Does MachineTranslation.com let you compare GPT-4.1-NANO and Claude Opus 4-7 side by side?
Yes. MachineTranslation.com allows you to select any combination of supported AI models and run them simultaneously on the same input. Both GPT-4.1-NANO and Claude Opus 4-7 are available, and their outputs appear in separate panels beneath the SMART consensus result, with individual quality scores where available. This makes it straightforward to compare the two models on your specific content before deciding which output to use.

By Rachelle Garcia
Connect on LinkedInRachelle leads product and AI at Tomedes, where she runs the experiments that turn internal data into better translation experiences. She writes about what actually happens when you build AI products such as MachineTranslation.com — the numbers, the surprises, and the parts that don't go to plan.
Share: