March 27, 2026
Claude vs. ChatGPT for translation: what the benchmarks show
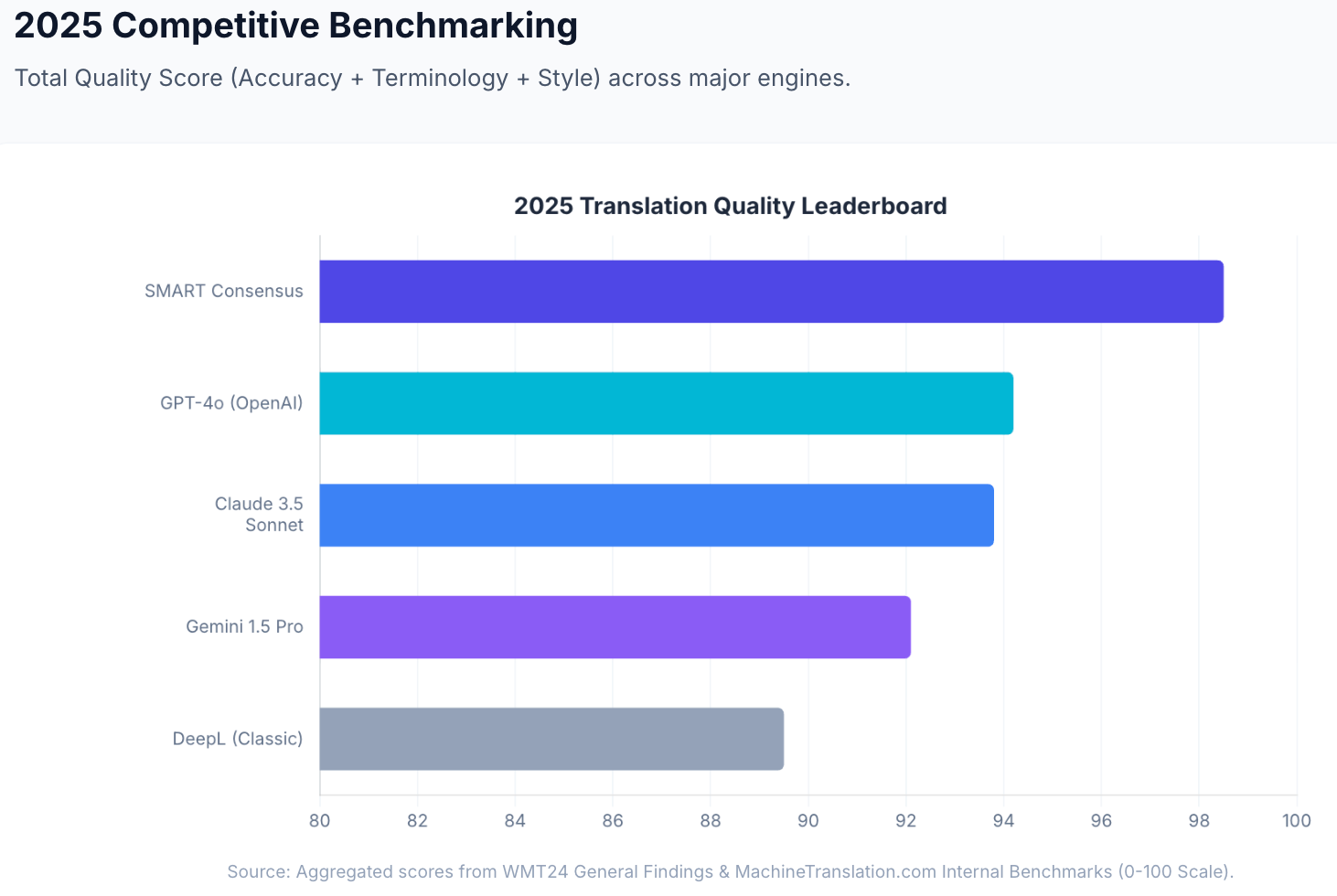
Claude (Anthropic) and ChatGPT (OpenAI) are the two most commonly compared AI models for translation. In MachineTranslation.com's internal benchmarks, Claude 3.5 Sonnet scores 93.8 out of 100 on translation quality; GPT-4o scores 94.2. The gap between them (0.4 points) is smaller than the gap between either model and the ceiling a single model can reach.
At WMT24, the translation industry's primary annual benchmark competition, Claude 3.5 ranked first in 9 out of 11 language pairs evaluated, ahead of GPT-4 and dedicated NMT engines. In Lokalise's 2025 blind study, professional translators rated 78% of Claude 3.5 translations "good" — the highest of any LLM tested, including ChatGPT. These results don't make Claude categorically better than ChatGPT for translation. They make the case that both models are operating at the top tier of what individual AI translation can produce — and that the real question is which one fits your specific content, workflow, and stakes.
This article covers what each model genuinely does better, where their documented differences matter for translation, and what to do when either model's output isn't sufficient on its own.
In this article
- How do Claude and ChatGPT actually compare on translation quality?
- Where does Claude have a genuine advantage?
- Where does ChatGPT have a genuine advantage?
- How do they compare on language support and pricing?
- What to use when one model isn't enough
- FAQs
How do Claude and ChatGPT actually compare on translation quality?
The short answer: they are much closer than most comparison articles suggest, and both are at the top of what any individual model can reliably produce.
The benchmark picture:
In MachineTranslation.com's internal benchmarks (testing translation quality across accuracy, terminology, and style), GPT-4o scores 94.2/100 and Claude 3.5 Sonnet scores 93.8/100. Both are among the highest scores of any individual model tested. Source: MachineTranslation.com internal benchmarks and WMT24 General Machine Translation Findings.
At WMT24, Claude 3.5 ranked first in 9 of 11 language pairs against the full competitive field, including GPT-4. In Lokalise's 2025 blind evaluation by professional translators, Claude 3.5 achieved the highest "good" rating (78%) of any LLM tested.
In Intento's State of Translation Automation 2025 (the most rigorous independent evaluation, covering 46 engines across 11 language pairs), both Anthropic Claude models (Opus 4 and Sonnet 3.7) and OpenAI GPT-4.1 appear among the 14 solutions that show the best results across all language pairs. Neither model dominates the other across all pairs.
What this means in practice: Both models are capable of producing translations that professional translators rate positively in blind evaluation. Neither is consistently better at "translation" as a single capability. Documented differences emerge at the edges (specific content types, specific language pairs, and specific workflows), which is where a direct comparison actually helps.
| Model | MT.com internal score | WMT24 standing | Lokalise 2025 "good" rating |
|---|---|---|---|
| Claude 3.5 Sonnet | 93.8 / 100 | 1st in 9/11 pairs | 78% (highest of any LLM) |
| GPT-4o | 94.2 / 100 | Top tier | Strong but below Claude 3.5 |
Source: MachineTranslation.com internal benchmarks; WMT24 General MT Findings; Lokalise 2025.
Where does Claude have a genuine advantage?
1. Long-document coherence. Claude's context window (200K tokens for Sonnet, 1M tokens in beta for Opus 4.6) allows it to process extremely long documents in a single pass. For a 200-page contract, a multi-chapter technical manual, or a full clinical trial report, Claude can maintain terminology consistency and tonal coherence across the full document without chunking. GPT-4o's 128K context window is also large, but the difference matters at the extreme end of document length.
2. Tone-sensitive and nuanced content. Professional translators in the Lokalise study favored Claude's output in blind testing (the highest "good" rating of any LLM), which reflects Claude's documented strength in producing natural-sounding output that preserves authorial voice. For literary translation, marketing copy, creative content, or formal communications where register precision matters, Claude's contextual depth tends to produce output that requires less post-editing.
3. Instruction precision. Claude 4.6 Sonnet's improvements in following complex instructions make it particularly responsive to explicit translation requirements — terminology constraints, register specifications, domain-specific style guides. When you need the output to conform to specific requirements and stay there across a long document, Claude handles instruction compliance reliably.
For how Claude's specific model tiers and pricing compare for translation use, see how good is Claude for translation.
Where does ChatGPT have a genuine advantage?
1. Iterative translation workflows. ChatGPT's conversational interface makes it particularly strong for workflows where the translator needs to iterate (adjusting tone, asking for alternatives, refining specific passages) within the same session. The back-and-forth refinement loop in ChatGPT's interface is more natural than starting new sessions. For translators who work interactively with AI output rather than accepting first drafts, ChatGPT's workflow is better suited.
2. Real-time and API integration breadth. ChatGPT's API is the most widely integrated in the developer ecosystem. More third-party tools, plugins, and platforms have native ChatGPT integration than any other LLM. For teams building translation into existing products or workflows, GPT-4o's API is typically the fastest path from decision to deployment.
3. Broad general-purpose coverage. For translation tasks that span a very wide range of content types (customer support, product descriptions, general business communications, quick informal translations), GPT-4o's breadth of training data gives it solid performance across diverse inputs. It is the more versatile choice for mixed-content workflows where the translation task is not specialized.
For detailed MachineTranslation.com benchmark data comparing GPT-4o against other models, see ChatGPT translate vs. Google Translate.
How do they compare on language support and pricing?
Language support:
Both Claude 4 and ChatGPT (GPT-4o) support translation across most world languages, with particularly strong performance in high-resource languages. Neither model publishes a definitive language count, both handle most standard Unicode languages at varying quality levels. Performance drops for both in lower-resource languages, with Claude showing approximately 72–78% accuracy for Southeast Asian languages versus 88–92% for Romance languages. GPT-4o has similar variation. For the languages most commonly needed in professional translation (European, East Asian, major world languages), both models perform at comparable quality levels.
Pricing:
| Plan | Claude | ChatGPT |
|---|---|---|
| Consumer (monthly) | Pro: $20/month | Plus: $20/month |
| API input (per M tokens) | Sonnet 4.6: $3 | GPT-4o: $2.50 |
| API output (per M tokens) | Sonnet 4.6: $15 | GPT-4o: $10 |
| Free tier | Yes (rate-limited) | Yes (rate-limited) |
For high-volume translation via API, GPT-4o's lower per-token cost gives it an advantage at scale. For consumer plan use, both are $20/month at the paid tier.
What to use when one model isn't enough
At 93.8 and 94.2 out of 100, Claude and ChatGPT are both operating near the practical ceiling for any individual translation model. The 0.4-point difference between them is real but small. Both are single-model systems with a structural limitation they share equally: neither can catch errors in its own output. A confident, fluent translation from either model can still be semantically wrong — and without a cross-check, neither the user nor the model has a way to know.
Both Claude and ChatGPT are among the 22 AI models inside MachineTranslation.com's SMART consensus system. SMART runs every translation through all 22 models simultaneously (including both GPT-4o and Claude) and selects the output the majority agrees on. The individual model scores (94.2 for GPT-4o, 93.8 for Claude) represent what each model achieves alone. SMART's consensus output reaches 98.5/100. The gap between any individual model and consensus isn't explained by one model being better, it's explained by model-specific errors being outvoted before they reach the output. Source: MachineTranslation.com internal benchmarks and WMT24 General Machine Translation Findings.
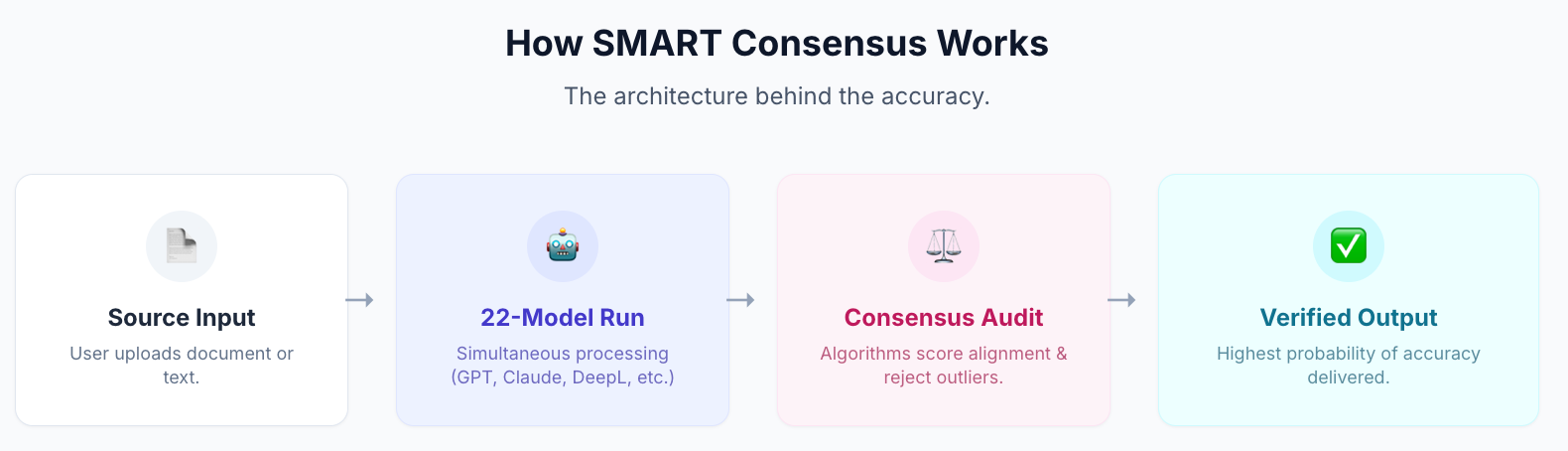
What this means for the Claude vs. ChatGPT question: if you're using either model for professional translation (client deliverables, published content, legal or regulated documents), the more productive question is not which single model to trust, but how to know the output you're looking at is right. MachineTranslation.com's SMART tells you how strongly the 22 models agreed on the result, providing the confidence signal neither Claude nor ChatGPT can produce alone.
For content requiring absolute certainty (a contract, a regulatory submission, a clinical instruction), Human Verification escalates any translation to a certified professional reviewer within MachineTranslation.com's platform: no external agency, no separate vendor, 100% accuracy guaranteed.
Translate with both Claude and ChatGPT (and 20 other models) at MachineTranslation.com, free, no sign-up required.
FAQs
1. Is Claude better than ChatGPT for translation?
In independent benchmark testing, Claude 3.5 and GPT-4o are extremely close — 93.8 vs. 94.2 out of 100 in MachineTranslation.com's internal benchmarks. Claude 3.5 ranked first in 9 of 11 language pairs at WMT24 and received the highest "good" rating (78%) in Lokalise's 2025 blind study by professional translators. GPT-4o edges it on the aggregate benchmark score. At this level of parity, documented differences in use-case fit (long-document coherence for Claude; iterative workflow and API breadth for ChatGPT) matter more than the overall quality gap.
2. Which is better for translating legal documents, Claude or ChatGPT?
Both models produce strong output for legal content, but neither should be the final step for submitted legal documents. Claude's long-context window gives it an advantage for very long legal documents (contracts, regulatory filings) where terminology must remain consistent across many pages. For either model, legal translation requires a verification step — MachineTranslation.com's Human Verification provides 100% accuracy from a certified professional reviewer within the same platform.
3. Does Claude or ChatGPT support more languages?
Both models support most major world languages and a broad range of others. Neither publishes a definitive count. For high-resource language pairs (European, East Asian, major world languages) both perform comparably. For lower-resource languages, performance drops for both. MachineTranslation.com supports 330+ languages, including both Claude and ChatGPT as part of the 22-model system.
4. How do Claude and ChatGPT compare on pricing?
At the consumer level, both Claude Pro and ChatGPT Plus are $20/month. At the API level, GPT-4o is slightly cheaper: $2.50 per million input tokens vs. $3.00 for Claude Sonnet 4.6 (output: $10 vs. $15 per million). For high-volume translation via API, GPT-4o has a cost advantage. MachineTranslation.com's free plan includes SMART consensus across 22 models including both, with no sign-up required.
5. Are both Claude and ChatGPT available on MachineTranslation.com?
Yes. Both are among the 22 models in MachineTranslation.com. Every translation on MachineTranslation.com runs Claude, GPT-4o, and 20 other models simultaneously, returning the output the majority agrees on alongside a Translation Quality Score. Rather than choosing between Claude and ChatGPT, you get the cross-validated output of both — free, on the same platform.
6. What should I use for creative or marketing translation?
Both models handle creative content well, but Claude's documented strength in tone preservation and instruction precision gives it an edge for creative translation where authorial voice and cultural resonance matter. In Lokalise's 2025 blind study, professional translators preferred Claude 3.5's output at the highest rate. For high-stakes marketing campaigns, consensus translation through SMART adds a cross-model check that neither model alone provides.
7. What is the single most practical difference between Claude and ChatGPT for translation?
Claude's advantage is most visible in long-document coherence and tone-sensitive content. ChatGPT's advantage is most visible in iterative translation workflows and API integration breadth. For most professional translation tasks (especially anything client-facing or published), both models perform at a level where the single-model limitation they share is more consequential than the gap between them.

By Clarriza Heruela
Clarriza Mae Heruela graduated from the University of the Philippines Mindanao with a Bachelor of Arts degree in English, majoring in Creative Writing. Her experience from growing up in a multilingually diverse household has influenced her career and writing style. She is still exploring her writing path and is always on the lookout for interesting topics that pique her interest.
Share: