May 8, 2026
Grok vs. Claude for translation: what the benchmarks show (2026)
Grok (xAI) and Claude (Anthropic) are both capable AI translation tools, but they have structurally different strengths. For most general translation tasks, you will not notice a meaningful difference between them. For two specific scenarios (translating content about recent events, and translating formal documents requiring precision), the difference is real and grounded in how each model was built.
This article covers what each model actually offers for translation, where independent benchmarks place them, and what to use when either model's output on its own is not sufficient.
In this article
- How do Grok and Claude compare on translation quality?
- Where does Grok have a genuine advantage?
- Where does Claude have a genuine advantage?
- How do they compare on language support and pricing?
- Which is better for specific content types?
- What to use when one model is not enough
- Frequently asked questions
How do Grok and Claude compare on translation quality?
The short answer: Claude leads on independent professional translation benchmarks. Grok's specific advantage is real-time knowledge access, not overall translation quality.
In MachineTranslation.com's internal benchmarks, Claude (3.5 Sonnet tier) scores 93.8 out of 100 on translation quality — accuracy, terminology, and style combined. Grok does not appear in the top 14 solutions in Intento's State of Translation Automation 2025, which evaluated 46 MT engines and LLMs across 11 language pairs. Claude Opus 4 and Claude Sonnet 3.7 both appear in the top 14. Source: MachineTranslation.com internal benchmarks; Intento State of Translation Automation 2025.
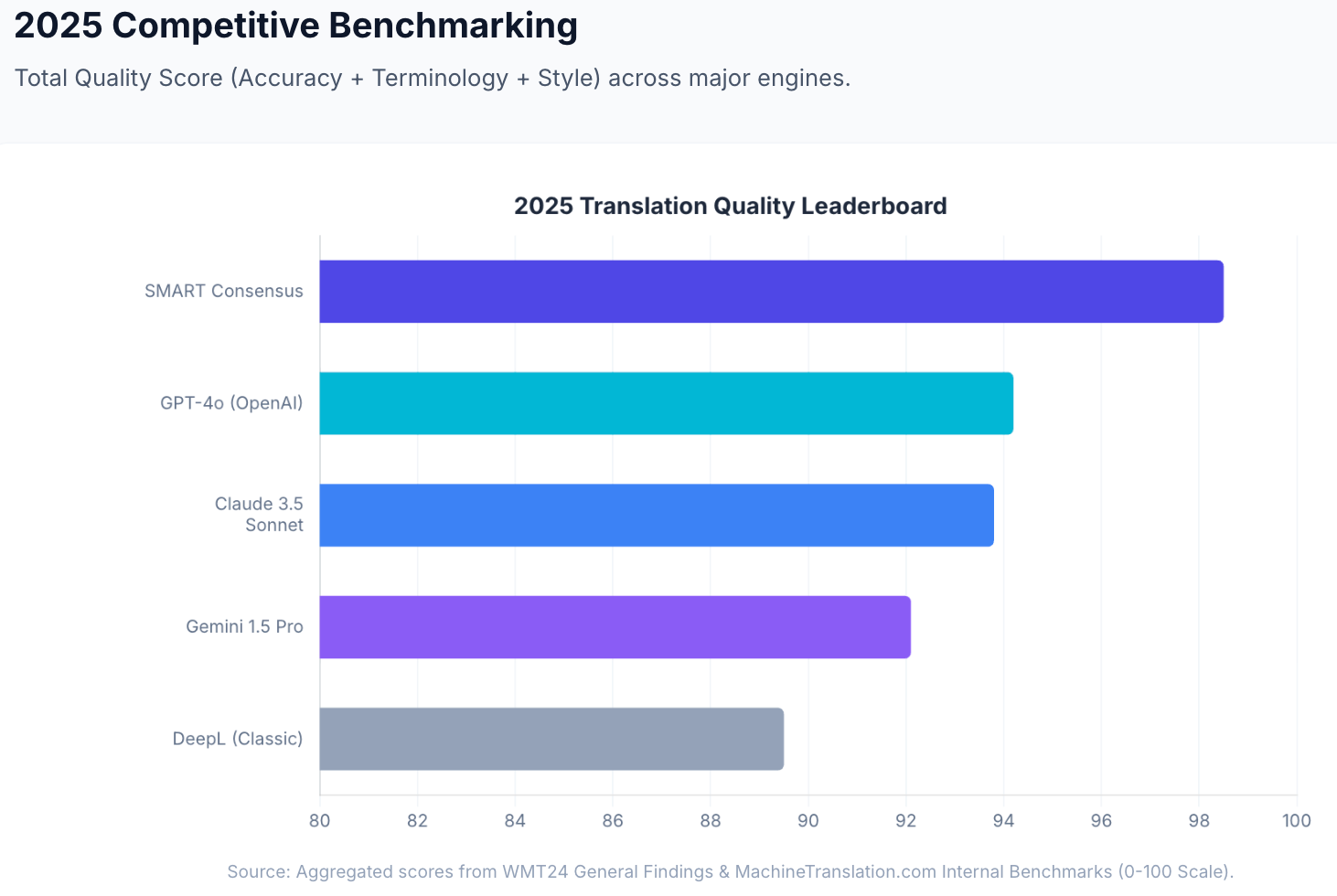
At WMT24 (the translation industry's primary independent benchmark competition), Claude 3.5 ranked first in 9 of 11 language pairs, ahead of GPT-4 and dedicated neural MT engines. In Lokalise's 2025 blind study by professional translators, 78% of Claude 3.5 translations were rated "good" — the highest of any LLM tested.
Grok has not been evaluated in WMT24 or Intento's independent LQA evaluation at a comparable level. The Slator Pro Guide (2025) lists Grok as one of the general-purpose LLMs used for translation in professional environments, alongside GPT and Claude, but does not rank it above either.
| Benchmark | Grok | Claude |
|---|---|---|
| MachineTranslation.com internal quality score | Not measured at benchmark level | 93.8/100 (3.5 Sonnet tier) |
| Intento 2025 top 14 solutions | Not listed | Claude Opus 4, Sonnet 3.7 both listed |
| WMT24 language pairs | Not evaluated | 1st in 9/11 language pairs |
| Lokalise 2025 blind study | Not evaluated | 78% "good" (highest of any LLM) |
Source: MachineTranslation.com internal benchmarks; Intento State of Translation Automation 2025; WMT24 General MT Findings; Lokalise 2025.
Where does Grok have a genuine advantage?
Real-time and current-events translation. Grok's defining architectural characteristic is its integration with X (formerly Twitter) platform data and live internet search. Unlike Claude and most other LLMs, which are trained on static datasets with fixed knowledge cutoffs, Grok incorporates real-time information into its outputs. For translation tasks involving recent events, newly released products, emerging political terminology, current news, or content referencing things that happened within the past weeks, Grok has access to context that Claude does not.
This matters specifically for: translating news articles about recent events, localizing product announcements for fast-moving markets, handling newly coined terminology or slang that postdates other models' training data, and any content where the meaning depends on knowing what happened recently.
Emerging and evolving terminology. Technical fields, industries, and cultural contexts continuously produce new terminology. For translation tasks involving recently coined terms, new regulatory language, or new product nomenclature, Grok's updated training and real-time search give it access to usage patterns that older training data snapshots do not capture.
Grok 4.1 context window and reasoning. Grok 4.1 (as of late 2025) features a 131K-token context window and improved reasoning capabilities, making it capable on complex, multi-layered documents where clause relationships and logical coherence matter.
Where does Claude have a genuine advantage?
Translation quality on independent benchmarks. Claude's advantage is documented by independent professional evaluation rather than self-reported claims. WMT24 ranked Claude 3.5 first in 9 of 11 language pairs against the full competitive field. Lokalise's 2025 blind study found professional translators preferred Claude 3.5 output at a 78% "good" rate — higher than GPT-4, DeepL, and Google Translate in the same evaluation. These are blind evaluations: professional translators assessed output without knowing which model produced it.
Specific language pairs per Intento 2025. Claude Opus 4 and Sonnet 3.7 appear in the "best" category for English to German, English to Japanese, English to Italian, English to Korean, English to Dutch, English to Arabic, and English to French in Intento's human LQA evaluation. For these pairs, Claude is the stronger documented choice among the two.
Tone precision and nuanced content. Professional translators in the Lokalise study preferred Claude's output at the highest rate of any LLM — reflecting Claude's documented strength in preserving register, authorial voice, and contextual meaning. For literary translation, legal documents, formal communications, and marketing copy where how something is said matters as much as what is said, Claude consistently performs well across independent evaluations.
Long-document coherence. Claude 4.6 Sonnet supports a 200K-token context window, with Claude Opus 4.6 supporting 1M tokens in beta. For long formal documents (contracts, technical manuals, clinical trial reports), Claude can process the full document in a single pass, maintaining terminology consistency throughout. Documents processed in fragments show a 28% higher rate of terminology inconsistency compared to whole-document processing. Source: MachineTranslation.com internal data.
How do they compare on language support and pricing?
Language support: Both Grok 4.1 and Claude 4.6 support translation across most major world languages. Claude has been independently evaluated across European and East Asian language pairs with strong results. Grok's multilingual support has improved across successive versions. For low-resource languages, both models degrade in quality — human review is appropriate for content in low-resource language pairs regardless of which model is used.
Pricing:
| Plan | Grok (xAI) | Claude (Anthropic) |
|---|---|---|
| Consumer (monthly) | SuperGrok: $30/month | Claude Pro: $20/month |
| API input (per M tokens) | Grok 4.1: $2 | Sonnet 4.6: $3 |
| API output (per M tokens) | Grok 4.1: $10 | Sonnet 4.6: $15 |
| Free tier | Yes (rate-limited via X/Grok.com) | Yes (rate-limited via claude.ai) |
At the consumer tier, Claude Pro ($20/month) is cheaper than SuperGrok ($30/month). At the API level, Grok 4.1 has a slight cost advantage over Claude Sonnet 4.6 for input-heavy translation workflows.
Which is better for specific content types?
| Content type | Recommended model | Reason |
|---|---|---|
| Recent news / current events | Grok | Real-time data access; static-trained models lack current context |
| Emerging terminology / new product launches | Grok | Live search integration captures recent usage patterns |
| Formal legal documents | Claude | WMT24 and Lokalise 2025 independent evaluation; tone precision |
| Medical / clinical content | Claude | Independent benchmark standing; register preservation |
| Marketing copy / creative content | Claude | Lokalise 2025 blind study preference; tonal nuance |
| Technical documentation (long) | Claude | 200K-1M context window; terminology consistency across length |
| Social media / conversational content | Either | Both handle high-resource conversational pairs well |
| Developer / API integration | Either | Both offer API access; Grok slightly cheaper on input tokens |
What to use when one model is not enough
Both Grok and Claude are single-model tools. Every individual AI model (regardless of how capable it is) produces errors it cannot detect in its own output. A fluent, confident translation from either Grok or Claude can still be semantically wrong, and without a cross-check there is no way to know.
Both Grok and Claude are among the 22 models in MachineTranslation.com's SMART system. SMART runs all 22 models simultaneously (including Grok and Claude) and returns the output the majority agrees on.
What this means for the Grok vs. Claude question: Grok's real-time strength and Claude's contextual depth both contribute to the same consensus. When they agree, that agreement is a strong quality signal.
In MachineTranslation.com's internal benchmarks, individual top-tier models score 93-94 out of 100 on translation quality. SMART's consensus output reaches 98.5/100. Source: MachineTranslation.com internal benchmarks and WMT24 General Machine Translation Findings.
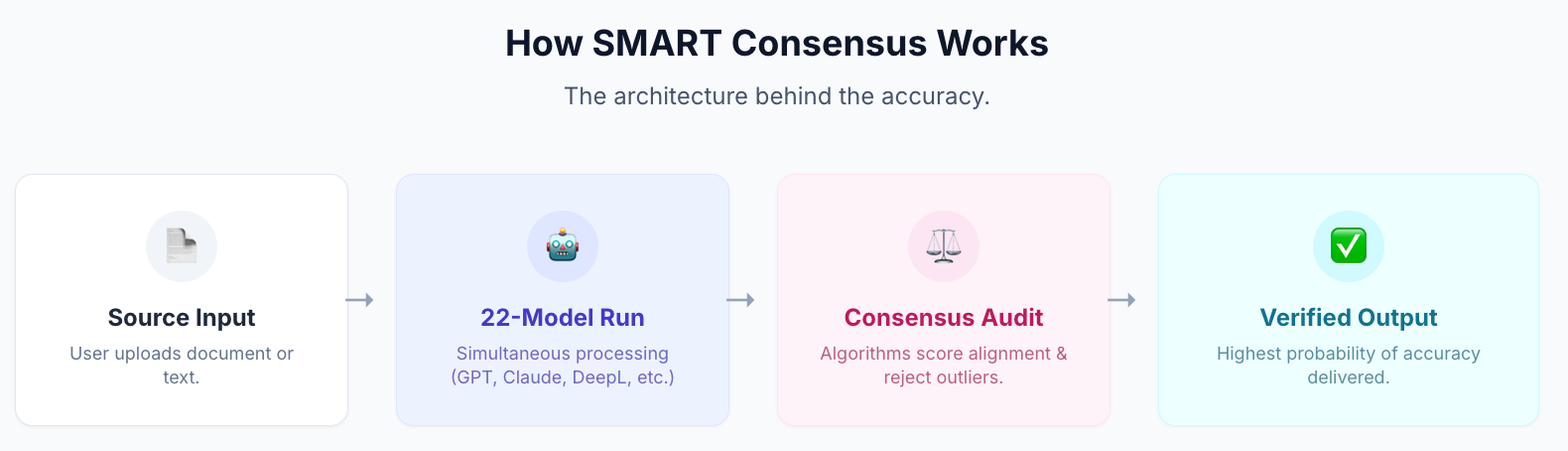
Users who switched from single-engine translation to SMART spent 27% less time verifying and correcting outputs. Source: MachineTranslation.com internal data.
For high-stakes content (legal documents, regulatory filings, medical instructions), Human Verification escalates the SMART consensus to a certified professional reviewer within the same platform. No external agency. 100% accuracy guaranteed.
Translate with Grok, Claude, and 20 other models at MachineTranslation.com — free, no sign-up required.
Frequently asked questions
1. Is Grok better than Claude for translation?
For most standard translation tasks, Claude leads on independent benchmarks: first in 9 of 11 language pairs at WMT24, 78% "good" rating in Lokalise's 2025 blind study, and 93.8/100 in MachineTranslation.com's internal quality benchmarks. Grok's specific advantage is for content requiring current-events knowledge, its real-time data access gives it context that static-trained models including Claude do not have. For recent news, emerging terminology, and time-sensitive content, Grok is the stronger choice.
2. What is Grok's advantage over Claude for translation?
Grok integrates real-time data from X (formerly Twitter) and live internet search. Unlike Claude and most other LLMs trained on static datasets, Grok can access information about recent events, newly coined terminology, and current context when generating translations. This makes it specifically stronger for translating news content, recently released products, and any material where the meaning depends on events or language patterns from the past few weeks.
3. What is Claude's advantage over Grok for translation?
Claude's advantage is documented through independent professional evaluation. Claude 3.5 ranked first in 9 of 11 language pairs at WMT24, and professional translators in Lokalise's 2025 blind study preferred its output at a 78% "good" rate — the highest of any LLM tested. Claude also appears in Intento's top 14 solutions across multiple language pairs in human LQA evaluation, while Grok does not. For formal, professional, and high-stakes translation tasks, Claude's independent benchmark standing is the documented differentiator.
4. Which is better for legal translation, Grok or Claude?
Claude is the stronger choice for legal translation based on independent evaluation. Claude 3.5 ranked first across most high-resource European language pairs at WMT24 and received the highest blind-study preference ratings from professional translators. For legal content requiring certified accuracy, neither model alone is sufficient — MachineTranslation.com's Human Verification provides 100% accuracy from a certified professional reviewer within the same platform, no external vendor required.
5. Are both Grok and Claude available on MachineTranslation.com?
Yes. Both are among the 22 models in MachineTranslation.com's SMART system. Every SMART translation runs Grok, Claude, and 20 other models simultaneously, returning the output the majority agrees on. Rather than choosing between them, you receive the consensus of all AI models.
6. How do Grok and Claude compare on pricing?
At the consumer tier, Claude Pro costs $20/month versus SuperGrok at $30/month. At the API level, Grok 4.1 is slightly cheaper on input tokens ($2/M vs. $3/M for Claude Sonnet 4.6) and output ($10/M vs. $15/M). MachineTranslation.com's free plan includes both models as part of SMART's 22-model consensus, no sign-up required.
7. Which AI model is best for translating news articles?
For translating news articles, Grok has a structural advantage: its real-time data integration means it has current context about the events being described, which static-trained models may lack. For general news translation where recency is not critical, Claude's benchmark performance is stronger. For high-volume news translation where both recency and accuracy matter, MachineTranslation.com's SMART runs both models and returns their consensus output.