July 7, 2023
Significant Improvements Observed on the Detection of Human vs. Machine Translated Texts
The University of Groningen in the Netherlands – with study leads Malina Chichirau, Rik van Noord, and Antonio Toral – recently published a study that shows a significant improvement on classifiers discerning between human versus machine translation. The team used fine-tuned monolingual* and multilingual** language models for their classifiers – testing each model’s performance based on the quality of training data provided. Both types of models excelled when provided with training data from multiple source languages.
—-- *models that are only capable of processing one language;
** models that are capable of processing two or more languages
Due to advancements in AI, machine learning, and neural networks, the language industry has begun to assimilate machine translation into their daily operations. As such machine translation research is crucial, more so the understanding of the variables that are at the center of these studies. In this article we will dissect these variables (i.e., classifiers and training data) to gain appreciation for and have a better understanding of studies for machine translation/learning.
Understanding Classifiers
To use an analogy, classifiers are like judges at an audition. These judges have built up experience over the years that qualifies them to assess audition performances based on certain criteria. These judges are then given the liberty to decide who meets the criteria to get through to the next round. Similarly, classifiers learn from training data in order to assess data points based on specific features. In the case of classifiers, they determine whether a text more closely meets the criteria for a human translation or a machine translation.
In their study, Automatic Discrimination of Human and Neural Machine Translation in Multilingual Scenarios,the University of Groningen’s research team assessed the performance of classifiers trained on monolingual language models and those trained on multilingual models (using English, German, Russian, and Chinese engines). But what types of classifiers did they use?
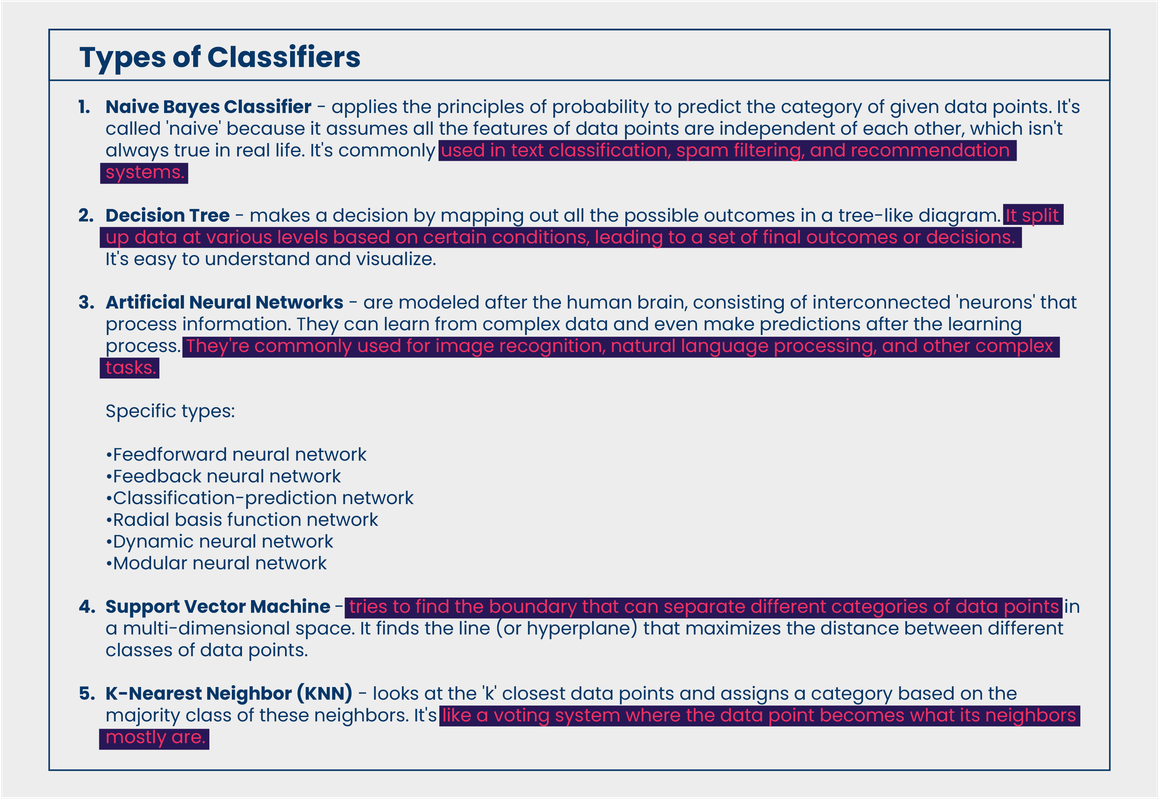
Note that a machine learning model can be trained to perform different types of classification tasks. It is important to understand that the types provided above only pertain to a certain algorithm/structure being utilized by a language model at any given time.
Want to learn more about models? Read about DeBERTa – the language model used by the researchers from University of Groningen.
Training Data Explained
Training data is the initial data on which machine learning algorithms are developed. Breadth and quality of data directly impacts the performance quality of any machine learning model. Machine learning models create and refine rules around the training data they have used. There are three approaches to using training data in machine learning:
-
Supervised learning – humans choose the data features and enrich or annotate the data to help the machine recognize outcomes
-
Unsupervised learning – the data is unlabeled, with the machine identifying patterns in it
-
Hybrid learning – the machine learns from both labeled and unlabeled data
What affects the quality of training data?
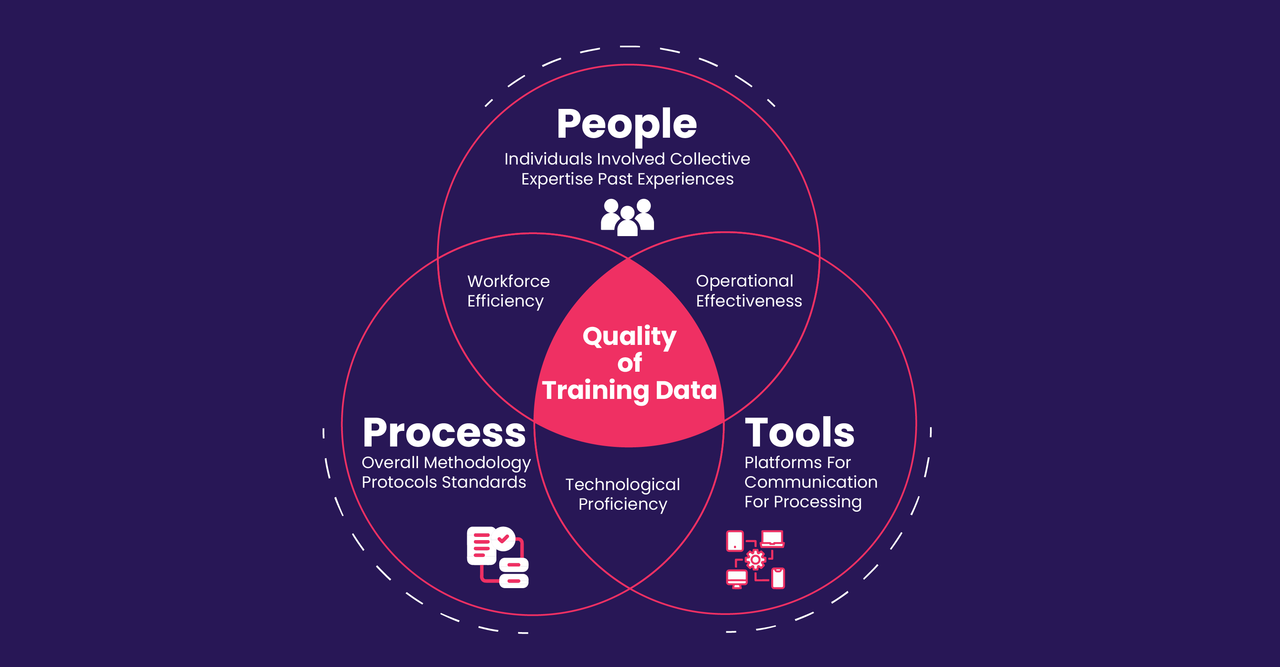
Training a machine learning model with training data is similar to teaching a student with textbooks. The textbooks (training data) are filled with knowledge (patterns and relationships) that the student (machine learning model) needs to internalize. If the textbooks used are accurate, comprehensive, and diverse, a student will be better prepared to answer questions on a test. Similarly, if the training data is high quality and robust, the machine learning model will be better at making accurate predictions.
Researching the Auto-Detection of Machine Translation
The University of Groningen team’s goal was to “tackle the task of automatically discriminating between human and machine translations.” Here their 2 key findings:
[1] The best results came from combining different source languages. Even small amounts of additional training data in another language allowed for a significantly better performing model. Both monolingual and multilingual classifiers benefited from training data taken from multiple source languages.
[2] The team also found that fine-tuning a sentence-level model on document-length text was impactful. This was preferable to simply training models on documents. Fine-tuning in this way led to the highest levels of accuracy and the lowest standard deviations, indicating more stable classifiers.
This research does not only present us with developments, but also raises awareness on the current pain points within the language industry. The research acknowledged that it has become increasingly difficult to distinguish original texts from generated texts – which is a very important consideration when developing training data for language models. As such, the next logical step – according to the researchers – will be to address classifiers that can discern between original texts, human translations, or machine translations.